
Baidu. Как китайский поисковик с помощью искусственного интеллекта обыграл Google
После того, как поведение человека начало фиксироваться в виде данных посредством интернета, у искусственного интеллекта появилось полноценная пища, чтобы идти в ногу с человечеством и помогать ему во всех сферах жизни. Машинный перевод, распознавание речи, изображений опираются на клики пользователей Интернета. Почему точность поисковой системы Baidu трудно сравнить с другими поисковыми системами? Потому что Baidu обладает самым большим объемом данных, самым продвинутым алгоритмом принятия решений и самой сильной командой. Каждый клик пользователя тренирует мозг Baidu и рассказывает о том, что человек хочет больше всего.
Когда искусственный интеллект переживал этап застоя, люди думали, что машина никогда не сможет думать так же, как человек. Но после 1990-х мы поняли, что машина и не должна думать так же, пока мы в состоянии сами решить свои проблемы. У лингвиста Хомского спросили: «Может ли машина думать?» Это был позаимствованный датским компьютерным ученым Дикстра риторический вопрос: «Будет ли подводная лодка плавать?» Ответ был такой: «Подводная лодка не плавает, как рыба или человек, но ее способности очень высоки».
Если мы оглянемся назад (не только на историю развития интернета), то поймем, что вся история развития промышленности – это шаги по направлению к развитию искусственного интеллекта. Кевин Келли отмечал, что самоприводящийся поршень парового двигателя уже представляет собой конструкцию, которая содержит элементы «эволюции». Стремление к автоматизации – эволюционная сила ИИ.
Когда началась промышленная революция, паровой двигатель появился в угольных шахтах и ямах. Эффективность двигателя пара была низкая, энергия, особенно при добыче угля, требовалась значительная, и спрос на дешевую рабочую силу сохранялся существенный. Дело в том, что при добыче угля использовалось много воды. А вода, в свою очередь, была топливом для парового двигателя. После того, как в шахтах впервые была применена новая технология, она постоянно продолжала совершенствоваться для содействия промышленной революции. С искусственным интеллектом то же самое: данные – это топливо для двигателя искусственного интеллекта, а когда ИИ получает достаточное количество данных, он может работать дальше.
Без накопления данных о деятельности человека компьютер не может стать объектом обучения. Это стало возможным благодаря развитию интернета и развитию методов сбора информации. А также благодаря исследователям ИИ, не все из которых являются учеными в сфере компьютерных технологий. Некоторые из них проводят биологические исследования, некоторые – инженерные. Некоторые изучают математику, архитектуру компьютерных чипов или автоматизированную итеративную оптимизацию компьютерных программ. Но однажды результаты изысканий сходятся в одной точке. И на этом месте рождается искусственный интеллект.
Сплотились, чтобы конкурировать
В 2016 году AlphaGo вызвала настоящую сенсацию в средствах массовой информации. Но, это была несколько запоздалая реакция. Гигант искусственного интеллекта Джефри Хинтон еще в 2007 году отмечал, что «вот-вот разразится буря».
В тот год один из студентов Хинтона с помощью Google Big Data применил исследования своего учителя к технологии распознавания речи и добился значительного успеха. Корифей ИИ только воскликнул: «Оказывается, моя неудача была вызвана исключительно отсутствием объема данных и необходимой вычислительной мощности!»
Искусственный интеллект уже готов войти во второе десятилетие XXI века. С 2015 года началась эра бизнес-конкуренции в сфере ИИ. По данным анализа сферы искусственного интеллекта, опубликованного инвестиционным агентством США CB Insights, объем инвестиций в ИИ превысил $1 млрд уже в первом квартале 2016 года, а за два квартала осуществлено 121 финансирование. За аналогичный период в 2011 произошло всего 21 вливание. Со второго квартала 2011 по второй квартал 2016 объем инвестиций превысил $7,5 млрд, 6 из которых поступили после 2014 года.
«Wuzhen Index: глобальный отчет о развитии искусственного интеллекта» демонстрирует, что в течение первых двух кварталов 2016 года в Китае число интеллектуальных предпринимательских компаний увеличилось более чем на 60. А объем инвестиций достиг $600 млн. В прошлом году Китай вложил 202 инвестиции в искусственный интеллект, что в общей сложности составляет $1 млрд (или около 6,8 млрд юаней). Рынок огромен.
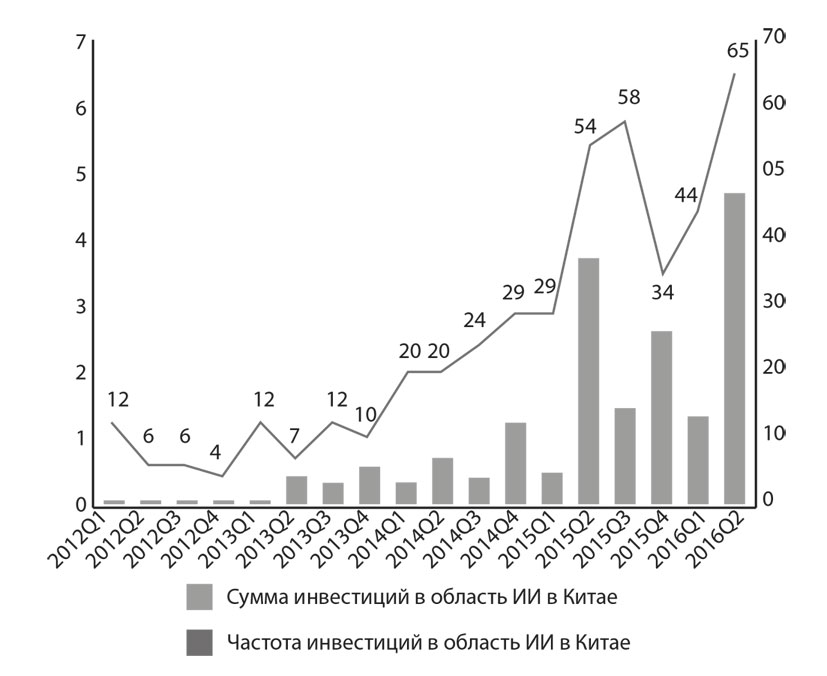
Рис. 1-2. Количество и частота инвестиций в ИИ
Источник: www.cbinsights.com
В 2016 году вице-президент Китайской академии наук и вице-президент китайского общества искусственного интеллекта, академик Тан Тин Бин, отметил, что в 2015 году стоимость мирового рынка искусственного интеллекта составляла $127 млрд. В 2016, по прогнозам специалистов, она достигнет $165 млрд. А к 2018 перешагнет за отметку в $200 млрд.
Китай, Соединенные Штаты и Великобритания – три передовые страны в развитии ИИ. США – источник интернета и искусственного интеллекта. Они обладают уникальными талантами, сильной технической базой и огромным финансированием научных исследований, что делает их лидером в данной области. Помимо Google, Facebook, Microsoft, Amazon, IBM, Apple и других гигантов информационных технологий, в Америке сотни крупных и малых компаний, которые также специализируются на бизнесе ИИ. Например, компания X.AI провела три этапа финансирования, которые в совокупности достигают $3,400 млн. Великобритания продолжает традиции старой школы даже в условиях сокращения производства. Сейчас все таланты собрались в области искусственного интеллекта. Одним из примеров является компания Deep Mind, которая продолжает работу над AlphaGo.
Amazon запустила голосовой помощник Alexa и умную колонку Echo, конкурируя с Apple, Google и Microsoft в сфере голосового поиска. В июне 2016 президент Amazon в своем интервью с американским IT-блогером Уолтом Мосбергом подчеркнул, что инвестиции компании в течение 4 лет вливались только в ключевые проекты в сфере ИИ. «В команду Amazon, занятую в работе над ИИ проектами, входило свыше 1000 человек. И это всего лишь верхушка айсберга».
В сентябре 2016 года Microsoft объявила о создании новой бизнес-группы по разработке искусственного интеллекта под руководством вице-президента Гарри Шума. Он возглавляет тысячи компьютерных ученых и инженеров, которые интегрируют искусственный интеллект в продукты компании. Среди продуктов: Bing Search Engine (Bing), Xiao Na Digital Assistant и Robotics Project. В конце года Microsoft выпустила сервис, который способен развивать чат-ботов и объявила, что она будет предоставлять услуги процессора для открытой лаборатории искусственного интеллекта AI, соучредителя Сэма Альтмана, президента Elon Musk и инкубатора стартапа YCombinator.
Facebook также имеет свою собственную лабораторию искусственного интеллекта и команду, похожую на Google Brain, т. е. использующую технологии машинного обучения. Миссия организации состоит в том, чтобы продвигать технологии искусственного интеллекта в различных продуктах Facebook. По словам Майка Шропфера, главного технического директора компании, «в настоящее время около 1/5 инженеров используют технологию машинного обучения».
Владелец AlphaGo, Google, конечно, не будет довольствоваться игрой в шахматы. Его искусственный интеллект продолжает развиваться на протяжении многих лет. В 2012 году у Google было два проекта, основанных на технологии глубокого обучения. К концу 2016 года этот показатель превысил 1000. В настоящее время многие продукты Google, такие как поисковая система, операционная система Android, бесплатный сервис электронной почты Gmail, онлайн-переводчик, онлайн-карты, видеохостинг YouTube, имеют некоторые свойства глубокого обучения.
Китай имеет огромные возможности для развития IT-бизнеса, значительное количество пользователей, внушительный массив данных и большую группу талантливых специалистов. Это позволяет ускорить темп развития ИИ. BAT (Baidu, Alibaba, Tencent), Huawei и некоторые другие гиганты заняли далеко не все сферы искусственного интеллекта, где можно реализоваться компаниям. Поэтому малый, средний и крупный бизнес продолжают выходить на арену ИИ. В 2016 году на форумах, будь то электронная коммерция, социальные медиа или поисковые системы, руководители интернет-компаний переводят тему разговора на искусственный интеллект. Сообщают о больших и малых достижениях.
В 2016 году точность распознавания речи Baidu достигла 97 %. А точность распознавания лиц – 99,7 %. Облако Baidu Brain, платформы Tianji, Tianxiang, Tiangong и Tianzhi последовательно открыли технологии и возможности Baidu Brain для всего общества.
Сверхмощный мозг
Более десяти лет назад немногие настаивали на развитии машинного обучения. Поэтому технология превратилась в настоящее сокровище. Но после всплеска интереса к сфере искусственного интеллекта самым дефицитным ресурсом стали талантливые специалисты.
Знания, на которые опирается развитие ИИ, имеют большое значение и для фундаментальных дисциплин науки, таких как математика и биология. Поэтому ученые, которые были бы одновременно сведущи в сфере искусственного интеллекта и в фундаментальных отраслях науки – большая редкость. В год выпускается чуть меньше 200 докторов и аспирантов, которые способны принять участие в национальных исследованиях или стартапах. Этого количества катастрофически не хватает. В 2015 году волнение в отрасли вызвала компания Uber, которая переманила 40 из 140 исследователей из Национального института робототехники Университета Карнеги-Меллона.
И это далеко не вся борьба за таланты. Практикующие специалисты более чувствительны к потоку академических кадров. За последние несколько лет из «башни слоновой кости» вышли многие академические звезды и прыгнули в прикладные исследования с парашютом. Они рисковали для того, чтобы простые люди могли заметить действительные изменения в сфере развития искусственного интеллекта. Но куда идти, чтобы в полной мере реализовать свои способности и не увязнуть в потоке, все еще остается проблемой.
Baidu является представителем китайской индустрии искусственного интеллекта. И большое количество талантов занимало или занимает достойное место в нашей команде. Ван Хайфэн работал в Baidu до перехода в Microsoft. Ву Энда появился в Baidu из Соединенных Штатов. Чжан Яцинь поменял Microsoft на Baidu. Линь Юаньцин, гигант в сфере искусственного интеллекта, занял должность директора лаборатории глубокого обучения Baidu по возвращении из Америки. Сегодня в компании есть необходимые талантливые специалисты, чтобы создавать собственные приложения с функциями ИИ. Baidu – это воплощение динамизма Китая в отношении привлечения и обучения ученых для работы в сфере искусственного интеллекта.
Множество сверхмощных человеческих мозгов сходятся в одном месте, чтобы создать один эпохальный китайский мозг для машины. Мы уже пережили эру ПК, эру мобильного интернета. Теперь на всех парах движемся к суперразумной эре взаимосвязи всех вещей. Слияние данных об окружающих нас предметах может в конце концов привести к развитию «Знания»[3]. Baidu двигается в этом направлении. Цель заключается в том, чтобы сделать искусственный разум таким же необходимым для людей, как вода или электричество. Это неизбежно спровоцирует повышенный интерес к развитию технологий. Например, Baidu имеет свои глаза, уши, рот и когнитивные навыки принятия решений. В целом, это искусственный эквивалент ребенка. Но некоторые способности, такие как перевод, распознавание речи, распознавание изображений, значительно превосходят способности ребенка. Мы открываем Baidu для людей, чтобы исследовать его возможности в различных приложениях с функциями ИИ. Baidu Brain уже сегодня стал инструментом для многих разработчиков операционных систем и способствует стандартизации формы искусственного разума. В новой эпохе нас ожидает полный спектр услуг для предприятий, предпринимателей и большинства индивидуальных пользователей.
Мы с энтузиазмом называем китайский мозг средством глубокого обучения серверов, алгоритмов, инфраструктуры приложений на уровне страны. Именно формирование китайского мозга станет олицетворением всестороннего повышения конкурентоспособности Китая и мощного ускорителя китайского возрождения.
Технологии, необходимые для улучшения жизни
Прежде чем начать разговор о данных, которые питают искусственный интеллект, я бы хотел остановиться на пользователях, бесчисленных потребителях, поддерживающих развитие Baidu и всего высокотехнологичного интернета.
Сегодня тенденция развития интернета и технологий сбора огромного количества информации подталкивает не только гигантов отрасли, таких как Google, Microsoft и BAT, но и малый и средний бизнес к наращиванию потенциала для того, чтобы решать проблемы в сложившейся ситуации.
Секрет успеха на самом деле прост: выясните, чего люди больше всего хотят, а затем дайте им это. Его успеху также способствовали сильные маркетинговые кампании и корпоративный имидж. Кейн сыграл здесь ключевую роль. Он ничего не знает о компьютерных технологиях. Но он от мозга костей – деловой человек, а его ноги глубоко укоренились в обществе. Центр мира – это потребитель. «Мы будем устами интернет-мира».
Цитата из книги «Кремниевая долина»
В книге «Кремниевая долина» я подчеркиваю важность каждого пользователя. В глазах инженеров потребитель – это один из элементов в технической документации, существование которого можно свести к одной формуле: потребности потребителя – развитие – обратная связь. Но интернет не только упрощает получение товаров и услуг, но и обеспечивает поле для обмена мыслями и эмоциями. Можно сказать, что интернет создает своего рода единое мнение пользователей.
Многие из наших инженеров и программистов наслаждаются свободой Baidu и полагаются на его простоту. Техник ясно мыслит, увлечен разработкой новых продуктов и общителен. Но люди с живыми эмоциями и мыслями не совсем соответствуют тому, как их видят инженеры. Вероятно, маленькие кусочки жизни каждого отдельного человека или сложные сделки в торговых центрах не будут ощущаться в наших лабораториях. Для того, чтобы лучше понять психологию пользователя, существует PR-отдел. Однако и они не всегда справляются с задачей и сталкиваются с проблемами, которые делают код уязвимым. Чтобы разобраться, как сломать барьер между техниками, бизнесменами и обычными пользователями, нам нужно сконцентрироваться на высоком уровне мышления продукта и скромном изучении трансграничного опыта.
Мысли о потребностях человека в повседневной жизни – непрерывная работа, которая требует настойчивости. Но если вернуться к теме книги, то мы, в конце концов, инженеры, и не забываем думать о том, как удовлетворять потребности пользователей с помощью технологий и цифр. Мы используем технологию разграничения данных для того, чтобы обслуживать разных пользователей.
Оцифровка – это тенденция, которая обсуждается в «Цифровом выживании», «Бесконтрольном» и «Чего хотят технологии» Кевина Келли. А также это то, что думают атланты современных технологий. Теперь помимо коммерческих, финансовых, сельскохозяйственных, военных и технологических данных, в нашем арсенале появились данные о жизни. Иногда дело доходит даже до того, что данные вызывают тревогу. Например, а что если личные данные будут проданы? Вкратце должны сказать, что данные в глазах искусственного интеллекта не носят личностной окраски. У него нет потребности запоминать ваши пароли и другие сведения в отличие от торговцев данными с низким уровнем образования. Искусственный интеллект сосредоточен на обнаружении общей «модели» из хаотичных действий, оптимизации производства и его обслуживания. Перевод, распознавание речи и распознавание изображений являются лучшими примерами прогресса. Эти данные, через алгоритм распознавания ИИ, будут иметь огромное значение для человечества. Например, от повседневного распознавания речи в борьбе с мошенничеством в сфере финансов до борьбы с терроризмом на национальном уровне.
Технология должна адаптироваться под пользователя, потому как продукт должен отвечать потребностям потребителя. Кажется, что хороший искусственный интеллект должен работать безмолвно и не может допускать скачки напряжения и мутность сведений. Но для того, чтобы улучшить технологии ИИ, нужно оптимизировать детали. Некоторые из них, например технология распознавания речи, работают неплохо, но метод ввода очень далек от того, чтобы называться удобным. Что не может не влиять на восприятие пользователя. Baidu в багаже опыта уже имеет примеры неудачно реализованных продуктов, которые должны быть изменены в соответствии с предпочтениями потребителей.
Данные и технологии не стоят на месте. Они постепенно очеловечиваются и начинают видоизменяться.
Многие интернет-пользователи были впечатлены изображением 1-2. Это Baidu карта с использованием технологии визуализации данных, которая наглядно демонстрирует линии миграции в Китае в начале 2014 года, когда в Дунгуане вышел запрет на порнографию и желтую прессу.
Старший редактор новостей сказал нам, что, рассматривая эту карту, он ощутил себя за пределами обычных новостей. И на мгновение приблизился к пониманию мира. Индекс миграции Baidu отражает перемещения людей с помощью технологии визуализации данных. Миграция людей в цифровую эпоху – это лишь небольшая страница в эпопее миграции людей за миллионы лет. Но эпоха огромных массивов информации тоже имеет свою первую историческую страницу.
Я бы сказал, что это тоже исторический момент в эпоху искусственного интеллекта. Это интеллектуальная картографическая технология для восприятия человеческой деятельности, человеческой судьбы. Искусственный интеллект сам по себе не является гуманным, но в сочетании с творческими идеями разработчиков, философией может обеспечить новую перспективу, даже другое человеческое отношение.
Компьютер и интернет – это тело искусственного интеллекта. А массивы данных или записи человеческой деятельности и человеческой природы могут наконец-то стать его «душой».
Бульвар данных
Один философ сказал, что человек – это существо «в постоянном пути». Baidu накапливает огромное количество картографических данных, дополненных мудростью создателя и различными сложными алгоритмами, которые изображают действия человека и демонстрируют его путь выживания.
Именно наше поколение слушает песню Дуна Ангера: «Ради жизни люди бегают, а их судьбы сплетаются. Я надеюсь, что благодаря искусственному интеллекту траектория движения человечества будет не просто пульсировать, но постоянно пересекаться. Она будет сливаться в одну полноводную реку и длиться бесконечно».
Молодой ученый из лаборатории больших данных Baidu в Принстоне по студенчеству изучал закономерности движения рыб. По возвращении домой он увидел карту миграции Baidu и заметил, что человеческие перемещения очень напоминают перемещения рыб. Изучение человеческих миграций даже более удобно за счет наличия масштабных данных и сведений. Так началась его работа в нашей компании. В 2016 году он и его коллеги использовали данные Baidu о миграции, чтобы предсказать падение продаж iPhone (Apple Phone). Подобный умный подход к анализу стал возможен за счет многочисленных данных, собираемых лабораторией, о разнообразии городской жизни и деятельности производственных предприятий.
В 2014 году Министерство транспорта предложило провести реформу. Было принято решение ускорить развитие программы «четырех перевозок» и строительства, ориентированного на рынок промышленности и научно-исследовательской отрасли. Это стало возможным благодаря технологическим инновациям, которые способны преобразовать научные достижения в производительность транспорта. Сейчас мы сосредоточены на создании многоканальной многорежимной системы и интегрированной платформы информационных услуг в сфере транспорта и путешествий. Она позволит мгновенно публиковать актуальную информацию и решит ряд вопросов человека, который отправляется в очередное путешествие.
В поддержку реформы Baidu выдвинул «интеллектуальный план платформы облачных услуг транспорта Китая». Планировалось совместно с Научно-исследовательским институтом автомобильных дорог Министерства транспорта и Национальным центром интеллектуальных транспортных систем инженерных технологий создать платформу для сотрудничества – эффективную систему обмена информационными ресурсами между провинциями, государственными предприятиями и другими членами общества.
Умная карта может измерить степень затора на дороге, анализируя скорость движения пользователя. И во избежание потери времени сконструировать маршрут объезда пробки. Это стало возможным благодаря использованию технологии виртуальной реальности. На основе данных и с помощью эффективного алгоритма принятия решений карта способна облегчить нагрузку на транспортную систему города и сократить работу для сектора управления дорожным движением.
Современные карты собирают всевозможные географические данные, что позволяет расширить число интеллектуальных проектов. Технология навигации высокой четкости достигает точности до сантиметра. И поэтому была задействована в разработке беспилотных автомобилей. В 2016 году на Всемирном интернет-конгрессе беспилотный автомобиль Baidu был публично протестирован и введен в эксплуатацию в городе Ву. Опыт проходил в условиях движения города. Машина проехала 3,16 километра, 3 светофора и несколько поворотов. Она не только не сталкивалась с людьми, которые перемещались в различных направлениях, но и учитывала погодные условия – дождь, туман, дымку. Полученный результат не уступает успехам коллег из Кремниевой долины, которые проводили подобные испытания в Северной Америке. В рамках разработки беспилотного автомобиля эти успехи незначительны. Но для развития искусственного интеллекта – это внушительный шаг вперед.
ИИ не упал с неба. Ему предшествовали десятилетия работы над компьютерными сетевыми технологиями и технологиями обработки данных, а также сбор необходимой информации о человеческой жизни и деятельности. Baidu Search и Baidu Maps являются материальным результатом процесса развития.
ИИ не миф и не шутка
Сегодня в средствах массовой информации появляется множество новостей о роботах и масса шуток. Например, в недавнем выпуске новостей был сюжет о роботе, который ранит людей. На самом деле это был робот, который упал с платформы. Существует также мнение, что роботы – это игрушки. Но если взглянуть на ситуацию с точки зрения науки, обнаружится, что ИИ – не миф и не шутка. Он – результат человеческого труда. И он не нуждается ни в поклонении, ни в страхе.
Ученые в области искусственного интеллекта часто скромно описывают свои достижения. Ву Цзюнь, бывший инженер Google, рассказывал, что в 2003 году, когда он и его компаньоны работали над повышением точности вводимых ключевых слов в поисковике, основной проблемой стал подбор синонимов для удовлетворения запроса пользователя. Если компьютер не выдает необходимого результата при поиске информации, то человек будет продолжать подбирать ключевые слова. Но в этой ситуации пользователь фактически делает всю работу самостоятельно. Нужно было усовершенствовать технологию, чтобы ускорить процесс поиска и улучшить механизм обратной связи. Инженер сказал: «Может показаться, что у нас нет соответствующих технологий для решения проблемы. На протяжении многих лет пользователи сами подбирали ключевые слова для поиска. Но в 2003 году во время долгих выходных в честь Дня Независимости Соединенных Штатов мы приостановили работу одного из пяти крупнейших центров обработки данных. И за 4 дня сделали обработку каждого ключевого слова. По сути, это был метод исчерпывания. Мы выявили сочетания слов, которые часто использовались для того, чтобы сузить результат поиска. Теперь, когда поступает аналогичный запрос, система дает более точные результаты гораздо быстрее».
Чтобы идти в ногу со стратегией поиска, использующей метод исчерпывания, машинный перевод и другие области технической логики должны иметь сходства. В июне 2016 года на заседании бюро переводов Google активно обсуждалась статья в «Нью-Йорк Таймс», в которой сообщалось о результатах исследований в области машинного перевода, опубликованных Baidu. Высказывание Майка Шустера привело конференц-зал в чувство: «Да, Baidu выпустила новую статью. И такое чувство, что кто-то видит то, что происходит в наших стенах. Потому что все тезисы имеют аналогичную нашим структуру и результат». Баллы BLEU Baidu (оценка качества искуственного перевода в сравнении с человевеческим) в основном совпадали с результатами, достигнутыми Google во внутренних тестах в феврале и марте. Квок Вей Ле, ведущий исследователь Google, не был расстроен. Он пришел к выводу, что исследования двигаются в правильном направлении. «Их система очень похожа на нашу», – прошептал он.