
Основы статистической обработки педагогической информации

Доброй памяти В.А.Стукалова, приоткрывшего дверь автору в бескрайний мир математической статистики, посвящается.
Введение
Несомненно, в цифровую эпоху тезис «кто владеет информацией – владеет миром» обретает новые интерпретации, но одного только факта владения становится недостаточным, когда объёмы информации колоссальны и осмысление её без специального инструментария не представляется возможным. Настоящее учебное пособие являет собой дополнение к курсу теории вероятностей и математической статистики, попытку авторской систематизации опыта работы и изложения материала, адаптированного к анализу педагогических данных. На волне глобализации школьный онлайн-учитель в ходе своей профессиональной деятельности сталкивается с необходимостью статистической обработки информации, когда на смену традиционным классам ограниченного объема на виртуальные уроки приходят многомилионные аудитории подписчиков из социальных сетей. О чём вы думаете, когда видите американского солдата в экзоскелете и очках дополненной реальности способного переносить грузы значительно превышающие пределы человеческих возможностей и вести наблюдение через непрозрачные стены, либо израильского хирурга, проводящего сложнейшую операцию дистанционно, либо арабского полицейского на джетпаках патрулирующего небоскребы в эмиратах? Без сопутствующего высокотехнологического оборудования ничто из перечисленного не было бы возможным, так и современный онлайн-учитель определенно получает некоторые преимущества лишь освоив соответствующие технологии анализа данных. В первую очередь, наглядную визуализацию. На сегодняшний день в мире не так много научных организаций, целенаправленно занимающихся вопросами визуализации. Из ведущих лабораторий на память приходят: Electronic Visualization Laboratory, Kitware, Лос-Аламосская национальная лаборатория, Подразделение Передовых Суперкомпьютеров NASA, Национальный центр суперкомпьютерных приложений, Сандийские национальные лаборатории, Центр Суперкомпьютеров Сан Диего, Научный институт вычислений и визуальной информации, Техасский Центр передовых вычислительных систем. Специализированных конференций и того меньше: IEEE Visualization, SIGGRAPH, EuroVis, Конференция по вопросам влияния человеческого фактора на компьютерные системы, Eurographics, PacificVis. Отрадно сознавать, что с недавних пор сей список пополнил и ОмГПУ. Необходимость наглядного представления педагогической информации обусловлена самой природой человека, получающего порядка 80%-90% данных с помощью зрения. Наглядность важна и для понимания, весомым подтверждением тому является небезызвестный «квартет Энскомба», составленный в 1973 году английским математиком Ф. Дж. Энскомбом для иллюстрации важности применения графиков для статистического анализа и влияния выбросов значений на свойства всего набора данных. А именно, следующие четыре набора данных имеют идентичные статистические характеристики, но их графики существенно различаются:
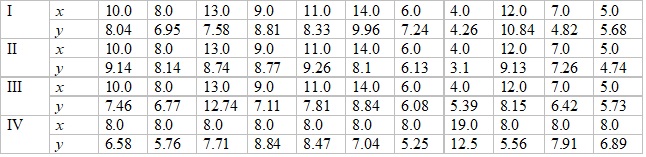
Табличное представление данных естественно, эффективно и удобно для хранения в памяти электронной вычислительной машины, но для осознания представленной информации человеком не обойтись без описательной статистики и главное – графиков:
В качестве вводного примера для иллюстрации возможностей анализа и визуализации педагогической информации приведем процесс установки и запуска визуализации средствами пакета R. Предположим, что вами уже создан и активно используется онлайн-курс по математике в iSpring Suite (https://www.ispring.ru/ispring-suite) с активным использованием GeoGebra (https://www.geogebra.org). В некоторый момент вы понимаете, что объем слушателей курса превосходит ваши физические возможности для анализа успеваемости, необходимо использовать программные средства специального назначения. Как быть?
Для решения обозначенной проблемы скачайте и установите пакет R для используемой вами операционной системы (https://www.r-project.org). Прямая ссылка с сайта МГУ: https://cran.cmm.msu.ru/bin/windows/base/R-4.0.2-win.exe При первом запуске процесса установки будет предложен выбор языка установки:
Далее важный момент, будет предложено ознакомиться с условиями универсальной общественной лицензии GNU, по которой распространяется R. Для тех, кто не знаком с ней, это лицензия на свободное программное обеспечение, созданная в рамках проекта GNU в 1988 г., по которой автор передаёт программное обеспечение в «общественную собственность». Её также сокращённо называют GNU GPL или даже просто GPL, если из контекста понятно, что речь идёт именно о данной лицензии. Как видите, R распространяется на правах второй версии этой лицензии, которая была выпущена в 1991 году. Суть в том, что в 1990 году стало очевидным наличие менее ограничивающей лицензии, которая могла бы использоваться для некоторых библиотек ПО; когда версия 2 GPL была выпущена в июне 1991 года, была введена в обращение и GNU Library General Public License (GNU LGPL, LGPL), также получившая номер 2, для обозначения того, что эти две лицензии являются взаимодополняющими.
Далее следует выбор папки установки:
Следующий важный момент – выбор разрядности приложения. Основное и едва ли не единственное отличие x64 от x32 в том, что версия x64 может работать с памятью вплоть до 32 Гбайт и запускать одновременно и 64-битные, и 32-битные приложения, тогда как традиционная x32 способна адресовать лишь до 4 Гбайт памяти, запускать только 32-битные программы для которых доступно только 3 Гбайт (говоря проще, даже если в компьютере 4 Гбайт (и более) памяти, то 32-битная система будет отображать и работать лишь с 3-мя, а остальная память будет попросту простаивать, ибо ни система, ни программы, попросту её не увидят). Как видите, отличия лишь в допустимых объемах обрабатываемой информации и общей производительности системы.
Настройки запуска программы и дополнительные опции не принципиальны. Предлагаемое на следующих экранах по умолчанию можно оставить без изменений, на том установка будет завершена.
Вторым шагом скачайте и установите RStudio (https://rstudio.com) – этот этап можно пропустить, пока не планируете профессионального освоения данного инструмента. Тем не менее, имейте ввиду, что RStudio в первую очередь это свободная среда разработки программного обеспечения с открытым исходным кодом для языка программирования R. Дистрибутивы RStudio Desktop доступны для Linux, OS X и Windows. Более того, в RStudio Server предоставляется доступ через браузер к RStudio установленной на удаленном Linux-сервере.
Процесс установки RStudio не многим отличается от установки R.
В на подготовительном этапе предлагается выбрать папку установки на диске, имеющем достаточно свободного места для развёртывания дистрибутива.
Последующие этапы позволяют выбрать опциональное создание ярлыков программы, по умолчанию располагаемых в меню «Пуск», и наблюдать за процессом завлечения и копирования файлов RStudio в папку назначения. Так как RStudio написана на языке программирования C++ и использует фреймворк Qt для графического интерфейса пользователя, то в операционную систему будут установлены все необходимые для запуска дополнительные библиотеки сторонних разработчиков. Наиболее крупной из которых, в частности, является Qt5WebEngineCore.dll. По окончанию процесса копирования работа мастера установки будет завершена.
Если пользоваться R без RStudio, то запускаем консоль в Пуск/R/R x64, после разрядности записывается номер установленной версии программного комплекса. Интерфейс будет чуть проще чем RStudio, но для решения элементарных задач достаточным:
Третьим шагом установите надстройку для многофакторного анализа (http://factominer.free.fr), для этого в консоли R просто вводится команда
install.packages("FactoMineR")
install.packages("Factoshiny")
после чего выбирается зеркало для загрузки надстройки.
Для включения пакета следует выбрать пункт меню «Пакеты/Включить пакет…/FactoMineR/ОК», либо установить в пункте меню «Пакеты/установить пакеты…/Factoshiny/ОК». После установки консоль готова для работы.
Кратко опишем, в каких целях используется пакет Factoshiny. Не секрет, что качественная графическая иллюстрация зачастую говорит больше, чем длинная речь оратора, поэтому крайне важно улучшать графики, полученные любыми основными компонентами методами (например: Метод главных компонент «PCA», Анализ соответствий «CA», Анализ повторяющихся соответствий «MCA», Многофакторный анализ «MFA», и многие другие). Factoshiny позволяет легко улучшить графики в интерактивном режиме. Этот удобный интерфейс позволяет параметризовать используемые методы и изменять графические параметры. При этом не нужно знать, как программировать.
Внося изменения в интерактивном режиме через интуитивно понятный интерфейс, становится очевидным, как улучшаются соответствующие графики. Результаты настроек графиков и параметров обновляются автоматически. В дальнейшем можно скачать получившиеся графики, а также строки настроенного кода, чтобы повторить анализ. Кроме того, можно сохранить, а затем повторно использовать объект, полученный из Factoshiny, для дальнейшей модификации графиков. При каждом новом запуске интерфейс открывается с теми настройками, которые были выбраны при последнем выходе из программы, следовательно, быстро можно продолжить изменение параметров выбранного метода факторного анализа или визуализации графиков.
Подготовив рабочее окружение, можно в качестве демонстрации из Google-документов выгрузить Excel-таблицу table.xlsx успеваемости своего онлайн-класса (с оценками для 5-7 учеников по 7-10 темам) и выполнить анализ данных созданной электронной таблицы средствами R. Для этого достаточно ввести следующую серию команд в консоли R (начинающиеся с символа # строки пропускаются, так как воспринимаются системой в качестве комментариев, подробнее необходимость комментирования исходных кодов будет обоснована в следующих разделах):
1) подключаем библиотеку импорта данных из .xls
library(readxl)
2) подключаем библиотеку многофакторного анализа
library(Factoshiny)
3) загружаем в переменную My_table содержимое файла table.xlsx
My_table <– read_excel("C:/путь к файлу/table.xlsx")
4) запускаем графический интерфейс для визуальной настройки и получения статотчетов PCA, в примере 1, 2, 3, 4, 5, 6, 7, 8 – номера импортируемых колонок из электронной таблицы My_table
PCAshiny(My_table[,c(1, 2, 3, 4, 5, 6, 7, 8)])
5) делаем выводы на предмет ведущих факторов, тем, вызвавших наибольшие/наименьшие затруднения учащихся и их взаимовлияния, тенденции развития.
Предположим, что электронный журнал, экспортированный в файл D:\test.xlsx содержит следующие данные об успеваемости обучающихся в 7а и 7б классах:
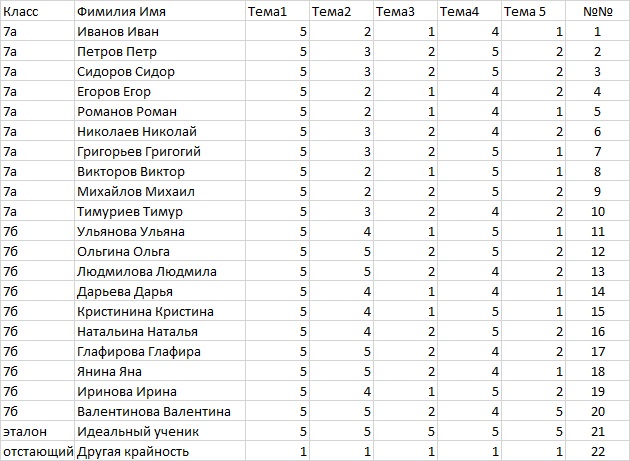
Запустим RStudio с предустановленными пакетами многофакторного анализа и в консоли R введём серию команд:
library(readxl)
library(Factoshiny)
My_table <– read_excel("D:/test.xlsx")
PCAshiny(My_table[,c(1, 3, 4, 5, 6, 7)])
Система запишет лог выполнения:
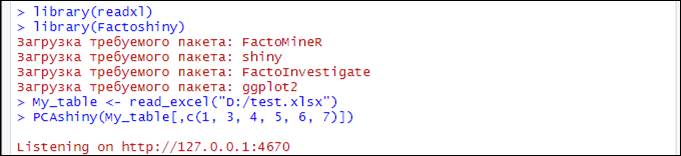
В открывшемся окне браузера настроим некоторые опции. Под номером 1 на рисунке отмечено включение дополнительных параметров построения графика; ПОД номером 2 настраивается способ выделения переменных цветом; под номером 3 включается изображение эллипсов доверительных интервалов значений переменных из разных категорий:
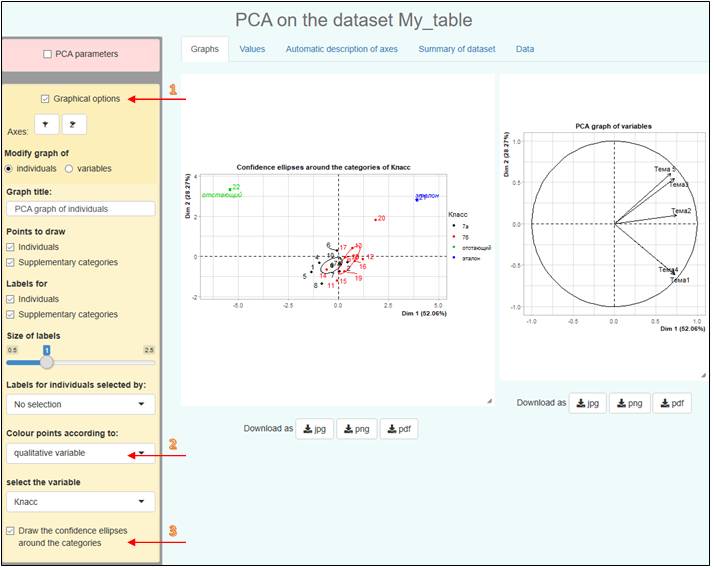
По полученному рисунку становится очевидным следующее:
– так как на круге корреляций вектора Тема1 и Тема4 фактически совпадают, то с этими темами большинство справились одинаково хорошо (если быть более точным, разделение по горизонтальной оси охватывает 52.06%, а по вертикальной – 28.27% тестируемых);
– эталонный ученик оказался в первой четверти, где лежат вектора Тема2, Тема3 и Тема5, значит остальным хуже дались перечисленные Тема2, Тема3 и Тема5;
– ученик №20 лучше всех освоил пройденный материал, так как ближе к эталонному отличнику, а с учениками 1, 4, 6, 8 следует позаниматься дополнительно;
– Тема2 в 7б была освоена лучше, чем в 7а, так как красный и черный эллипсы оказались разнесены вдоль направления вектора Тема2;
– так как центры обоих эллипсов лежат в нижней полуплоскости, снесены от начала координат по направлению векторов Тема1 и Тема4, следовательно статистическому большинству Тема3 и Тема5 далась хуже, чем Тема1 и Тема4, поэтому Темы 3 и 5 необходимо изучить детальнее.
Сказанное выше соотносится с исходными табличными данными, но на большом количестве факторов и аналитических данных графическое представление для обнаружения закономерностей оказывается гораздо удобнее.
Глава 1. Первое знакомство
Внимательный читатель наверняка понял из введения, что эта книга поможет в сфере анализа педагогических данных с помощью R: научит, как импортировать данные в R, систематизировать их наиболее эффективным способом, преобразовать данные, визуализировать и смоделировать возможную динамику. Аналогично тому, как начинающий математик учится ставить мысленные эксперименты, формулировать гипотезы, рассуждать по аналогии, формировать доказательную базу, вы узнаете, как представлять данные, строить графики и многое другое. Эти навыки позволяют состояться онлайн-учителю как исследователю, и в этой книге собраны проверенные оптимальные способы работы с R, освоив которые будет легко использовать язык графиков, чтобы экономить время. Кроме того, станет ясным, как достичь понимания в процессе визуализации и исследования данных. Наука о данных – это захватывающая дисциплина, которая позволяет превратить необработанные исходные разрозненные данные в систематизированные, породив понимание и новое знание. Таким образом, основная цель этой книги – помочь читателю изучить наиболее важные инструменты в R, позволяющие заниматься наукой о педагогических данных. После прочтения этой книги у вас появятся инструменты для решения широкого круга задач средствами R.
§1. Основы статистической обработки информацией
Наука о данных – это огромная сфера человеческой деятельности, общепринятый подход к освоению которой, прослеживающийся в каждом исследовательском проекте как правило следующий. Сначала данные импортируются в R. Обычно это означает, что берете данные, хранящиеся в файле, базе данных или интернете, и загружаете их в таблицу данных R. Если не можете импортировать свои данные в R, то дальнейший анализ данных в R не представляется возможным и стоит рассмотреть альтернативные варианты.
После того, как импортировали свои данные в R, неплохо было бы привести их в порядок. Очистка ваших данных означает хранение их в согласованном виде, который соответствует семантике набора данных. Короче говоря, когда данные структурированы, каждый столбец является переменной, и каждый ряд – это наблюдение. Структурированные отфильтрованные данные важны еще и потому, что последовательная запись позволяет сосредоточиться на вопросах о непосредственно самих данных, а не на вопросах о получении данные в правильном формате для разных функций.
После того, как у вас есть структурированные данные, общим первым шагом является их преобразование, включающее в себя:
1) фильтрацию по наблюдениям (например, все люди обучающиеся в одном городе, или все данные за последний учебный год);
2) создание новых переменных, которые являются функциями от существующих переменных (например, вычисление продолжительности обучения или длительности прохождения тестов);
3) вычисление набора сводных статистических данных (например, наивысший балл из набранных обучающимися).
После того, как у вас есть структурированные данные с вычисленными переменными запускаются два основных генератора новых знаний: визуализация и моделирование. Оба имеют свои сильные и слабые стороны, и любой реальный анализ будет происходить в процессе их многократного чередования.
Визуализация – это фундаментальная человеческая деятельность. Одна хорошая визуализация покажет вам то, чего даже не ожидали, или поднимет новые вопросы об анализируемых данных. Хорошая визуализация также может намекнуть, что задаете неправильный вопрос, или что нужно собирать дополнительные данные. Визуализация может вдохновить вас, но не стоит обольщаться, так как для интерпретации результатов всё же требуется участие человека.
Моделирование является дополнительным инструментам визуализации. После того, как достаточно точно сформулировали свои вопросы, можете попробовать использовать математическую модель, чтобы ответить на них. Модели в R принципиально являются математическими и представляют собой вычислительный инструментарий, поэтому они хорошо масштабируются. Нередко бывает дешевле купить больше компьютеров, чем это купить больше мозгов. Но каждая модель при этом генерирует лишь предположения, и по своей природе математическая модель не может подвергать сомнению свои собственные предположения. Это означает, что модель сама по себе не может сделать принципиальное открытие.
Последняя ступень анализа данных: представление полученных результатов, – самая критическая часть любого аналитического проекта. При этом не важно, насколько хороши ваши модели или визуализации, если не можете передать свои идеи и результаты другим людям.
Объединяет все названные этапы – программирование, оно красной нитью проходит через каждый этап проекта, но не нужно быть опытным программистом, чтобы анализировать данные, достаточно знания базовых концепций, и желания постоянно улучшать свои навыки программирования, так как последнее позволяет автоматизировать частые задачи и проще решать новые.
Вы будете использовать названные инструменты практически в каждом проекте, но для большинства проектов их недостаточно. Есть эмпирический принцип 80/20 (закон Парето): можно решить около 80% задач каждого проекта используя методы, которыми уже владеете, но всегда понадобятся новые знания, чтобы справиться с оставшимися 20%.
Предыдущее описание инструментов обработки данных организована примерно в соответствии с той последовательностью, в которой они используются в статистическом анализе (хотя, конечно, любое правило имеет исключения). По собственному опыту, лучший порядок их освоения таков:
1) Начинать изучение с импорта данных, их очистки и систематизации является неоптимальным, так как 80% времени будет занято рутиной. Вместо этого, начнем с визуализации и преобразования данных, которые уже были импортированы и отфильтрованы. Таким образом, когда будете импортировать и приводить в порядок собственные данные, ваша мотивация останется высокой, потому что понимаете, к чему движетесь.
2) Некоторые темы лучше объяснить объединив их. Например, легче понять, как работают модели, если уже знаете о визуализации, структурированных данных, и программировании.
3) Инструменты программирования не самоцель, но все же позволяют взяться за решение значительно более сложных проблем. Поэтому весь спектр инструментов программирования будет представлен в середине книги, а затем увидите, как они могут сочетаться с другими статистическими инструментами, при решении интересных задач моделирования.
В рамках каждой главы постараемся придерживаться подхода из введения по аналогичному шаблону: начинать с некоторых мотивирующих примеров, чтобы увидеть картину в целом, а затем погрузиться в детали. Каждый раздел книги сопровождается упражнениями, позволяющими на практике закреплять пройденный материал. Хотя и бывает заманчивым пропускать их, но очень хорошо сказал Д. Пойа по этому поводу: «лучший способ научиться решать задачи состоит в том, чтобы самому решать эти задачи».
Есть несколько важных тем, которые в данной книге не будут охвачены, с той лишь целью, чтобы сосредоточиться на самом главном и как можно быстрее начать работать в R. А именно, не будут охвачены популярные ныне большие данные (так называемые «биг дата»). Сфокусируемся на небольших, располагаемых в памяти персонального компьютера наборах данных, что вполне оправдано для начала, ведь невозможно заниматься большими данными, если у вас нет опыта работы с малыми. При этом, сам инструмент освоите, и будете легко обрабатывать сотни мегабайт данных, и с тем же успехом сможете использовать полученные навыки для работы с 1-2 Гб данных. Для сравнения, базы рабочих учебных программ дисциплин подготавливаемых каждым преподавателем ежегодно занимают порядка 1 Гб. Если же регулярно работаете с большими данными (порядка 10-100 Гб и более), то должны будете узнать больше об иных инструментах для их обработки. Эта книга не учит работе с большими таблицами данных, появляющимися на международных образовательных платформах, из облачных хранилищ. Но если действительно работаете с большими данными, то для повышения производительности своего труда стоит приложить дополнительные усилия к освоению необходимых инструментов.
Если данные действительно большие, тщательно подумайте, может ли задача с большими данными быть решена на небольших наборах данных. Хотя исходные данные могут быть большими, часто данные, необходимые для ответа на конкретный вопрос, невелики. Возможно, найдется подмножество, подвыборка или сводка, которая помещается в память и все еще позволяет ответить на интересующий вопрос. Проблема здесь заключается в том, чтобы найти правильные небольшие данные, что часто требует много итераций. Альтернативный вариант заключается в том, что задача с большими данными является совокупностью задач с малыми входными данными, а значит, решение легко поддается распараллеливанию. Например, каждая подзадача может поместиться в локальной памяти, но у вас их миллионы. В этом примере можно построить соответствующую модель для каждого наблюдения в наборе данных. Это было бы тривиально, если бы было всего 10 или 100 наблюдений, но вместо этого у вас их миллион. К счастью, порой анализ каждого наблюдения можно осуществлять независимо от других, тогда понадобится система (например, Hadoop или Spark), позволяющая отправлять различные наборы данных на разные компьютеры для параллельной обработки. После того, как нашли способ решения своей задачи для фиксированного подмножества входных данных с помощью описанных в этой книге инструментов, примените иные инструменты, для решения её на всём наборе данных.
Далее, из этой книги ничего не узнаете о Python, Julia или любом другом языке программирования, полезном при обработке данных. Это не потому, что эти инструменты плохие, отнюдь. На практике большинство команд аналитиков используют смешение языков, часто такое происходит с R и Python. Однако, лучше осваивать один инструмент за раз. Подобно ныряльщику за жемчугом, если сгруппироваться при входе, то движение к заветной цели в новой среде будет и глубже и быстрее. Это вовсе не значит, что следует изучить только одну тему, хотелось лишь напомнить, что как правило, учиться гораздо легче, если во время обучения методом погружения придерживаться одного направления. Следует так же стремиться узнавать новое на протяжении всей своей карьеры онлайн-учителя.
Поистине, R это отличная отправная точка для путешествия в мире науки о данных. Ведь R это не просто язык программирования, а интерактивная среда для совместной работы над анализом научных данных. Для поддержки взаимодействия пользователей, R является гораздо более гибким языком, чем многие из них его ровесники. Эта гибкость имеет своими недостатки, но большой плюс в том, как легко можно развивать адаптированные грамматики для конкретных частей процесса обработки данных. Эти вспомогательные мини-языки помогают думать о решаемых проблемах в привычной терминологии, поддерживая пластичное взаимодействие между вашим мозгом и компьютером.