
Искусственный интеллект и Машинное обучение. Основы программирования на Python

Тимур Казанцев
Искусственный интеллект и Машинное обучение. Основы программирования на Python
Введение
В последнее время очень много разговоров об Искусственном интеллекте (Artificial Intelligence), Машинном обучении (Machine learning), Глубоком обучении (Deep learning), больших данных (Big Data), нейронных сетях (Neural networks) и многих других терминах и технологиях, о которых 30 лет назад можно было прочитать только в футуристических книгах. Однако это не с проста. Уже сегодня различные технологии искусственного интеллекта используются в нашей повседневной жизни.
Когда мы смотрим новостную ленту, новостные агрегаторы показывают нам именно те новости, которые нам могут быть наиболее интересны. То же самое происходит в социальных сетях, на Youtube, музыкальных сервисах, где нам показывают именно те видео, песни или изображения, которые скорее всего нам понравятся.
Компьютеры уже могут распознавать нашу речь и автоматический перевод от Яндекс и Google Translate работает на порядок лучше, чем всего лишь 5 лет назад.
Техники распознавания изображений и окружающей среды и местности применяются в автономных беспилотных автомобилях, которые уже ездят по миру, в том числе и в России. И количество автономных машин увеличивается огромными темпами.
Кроме того, ИИ используется банками при решении о выдаче кредита, отделами продаж и маркетинга в компаниях, чтобы предсказывать объемы продаж, и делать более персональные рекомендации для каждого клиента.
Огромные бюджеты тратятся на таргетированную рекламу, которая становится все более точечной благодаря технологиям машинного обучения.
Особо актуальным ИИ становится в медицине, где нейронные сети могут выявлять наличие серьезных заболеваний намного с большей точностью чем самые профессиональные доктора.
Как вы видите, спектр использования Искусственного интеллекта очень обширен и его технологии уже используются во многих сферах.
Так как ареал использования охватывает практически все области, это требует большого количества специалистов, разбирающихся в том, как работают алгоритмы искусственного интеллекта и машинного обучения. И именно поэтому сегодня любому, кто хочет развития своей карьеры, необходимо иметь как минимум базовое представление об ИИ и МО.
По различным оценкам, сейчас во всем мире примерно всего лишь 300 000 специалистов по искусственному интеллекту, и из них только 10 000 это очень сильные профессионалы, которые работают над масштабными проектами. Оценивается, что спрос в самое ближайшее время на таких специалистов вырастет до 30 миллионов человек и продолжит расти в дальнейшем. То есть налицо огромная нехватка экспертов, которые понимают и умеют работать с технологиями ИИ и МО.
Многие технологические гиганты, такие как Google, Яндекс, Netflix, Alibaba, Tencent, Facebook жалуются на нехватку высококлассных специалистов и не даром зарплаты для таких вакансий – одни из самых высоких на рынке.
Сегодня специалист с двумя – тремя годами опыта в области больших данных и ИИ может получать более 150 тысяч долларов в год в Америке, Европе и Китае, а лучшие специалисты зарабатывают от миллиона долларов в год и выше. Не стоит и говорить о многочисленных стартапах в области ИИ, которые запускаются каждую неделю и привлекают огромные раунды инвестиций.
Таким образом, если подытожить, то Искусственный интеллект уже используется вокруг нас многими компаниями и сервисами, порой даже когда мы этого не замечаем. В общем и целом, он делает наш опыт взаимодействия с окружающей действительностью более персонализированным и удобным.
Есть масса областей и индустрий, где можно приложить на практике знания ИИ. И есть очевидная нехватка специалистов в этой области, и они будут востребованы в ближайшие пару десятилетий как минимум.
В этой книге мы дадим базовое представление о том, что такое Искусственный интеллект и машинное обучение, расскажем основные виды, алгоритмы и модели, покажем вам где искать данные для анализа, и попрактикуемся вместе с вами над решением некоторых реальных задач машинного обучения. После прочтения данной книги вы сможете общаться свободно на эти темы, и, если захотите, сможете в дальнейшем углубить свои знания в этой области с помощью более специализированных программ.
До встречи внутри книги!
История развития Искусственного интеллекта
Именно в последние несколько лет термины Искусственный интеллект, машинное обучение, нейронные сети, биг дата стали, пожалуй, одними из самых обсуждаемых тем во всем мире. Сегодня об искусственном интеллекте не говорит только ленивый. Однако, необходимо помнить, что ИИ – это не что-то новое, и этой дисциплине уже несколько десятков лет.
Задумываться о том, может ли у машин быть интеллект, начали еще в середине прошлого века. Еще в 1950 году английский математик Алан Тьюринг предложил Тест Тьюринга, цель которого заключалась в том, чтобы определить может ли машина мыслить и обмануть человека, заставив его поверить, что он общается с таким же человеком как и он сам, а не с компьютером.
В том же самом году фантаст Айзек Азимов ввел в терминологию Три закона робототехники, в котором указал, какими должны быть взаимоотношения между людьми и роботами.
Законы гласили:
Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинён вред.
Робот должен повиноваться всем приказам, которые даёт человек, кроме тех случаев, когда эти приказы противоречат Первому Закону.
Робот должен заботиться о своей безопасности в той мере, в которой это не противоречит Первому или Второму Законам.
В 1955 году проходил семинар ученых, где обсуждали будущее компьютеров. Одним из присутствующих был Джон Маккарти, который первым ввел в обиход термин Искусственный интеллект. Поэтому именно 1955 год принято считать годом рождения ИИ. Через три года тот же Маккарти создал язык программирования Lisp, который стал основным в работе с ИИ на следующие несколько лет.
В 1956 году инженер Артур Сэмюэл создает первый в мире самообучающийся компьютер, который умеет играть в шашки. Шашки были выбраны из-за того, что в них присутствовали элементарные правила, и в то же время если вы хотели выиграть в них, то требовалось следовать определенной стратегии. Этот компьютер, созданный Сэмуэлэм, обучался на простых книжках по игре в шашки, в которых описывались сотни партий с хорошими и плохими ходами.
В этом же году Герберт Саймон, Алан Ньюэлл, и Клиффорд Шоу придумали программу, которая называлась Логический теоретик. Считается, что это одна из первых программ, обладающих ИИ. Логический теоретик хорошо справлялся с ограниченным кругом задач, например, задачи по геометрии, и даже смог доказать теорему о равностороннем треугольнике элегантнее, чем Бертран Рассел.
В следующем 1957 году Фрэнк Розенблатт придумал Перцептрон, который представлял собой обучаемую систему, действовавшую не только в соответствии с заданными алгоритмами и формулами, но и на основании прошлого опыта. Здесь важно отметить, что в перцептроне были впервые использованы нейронные сети. Уже тогда ученые понимали, что некоторые (нечеткие) задачи решаются человеком очень быстро, в то время как у компьютера они отнимают много времени. Поэтому подумали, что возможно необходимо воспроизвести структуру работы мозга человека, чтобы научить компьютер работать так же быстро. Поэтому простейшие элементы перцептрона назывались нейронами, потому что вели себя похожим образом, как и нейроны мозга человека. Компьютерная модель перцептрона была реализована в 1960 году в виде первого нейрокомпьютера, который был назван Марк-1.
А в 1959 году Массачусетский Технологический Институт основывает лабораторию Искусственного интеллекта.
Идем дальше в следующее десятилетие. Уже в 1961 году первый робот внедряется на производстве автомобилей компании General Motors.
В 1965 году был изобретен первый чат-бот Eliza. Eliza должна была имитировать психотерапевта, который расспрашивал у пациента о его состоянии и предлагал возможные решения или просто мог посочувствовать собеседнику. Оказалось, что в разговоре с Элайзой люди испытывали примерно такие же эмоции и чувства, как и при общении с настоящим человеком.
В 1974 году было изобретено первое беспилотное транспортное средство в лаборатории Стэнфордского университета, оно станет прототипом для следующих лунных модулей.
В 1978 году Дуглас Леннон – создал самообучающуюся систему Эвриско. Эта система не только уточняла уже известные закономерности, но и предлагало новые. Через несколько лет Эвриско научилась решать такие задачи как: моделирование биологической эволюции, очистка поверхности от химикатов, размещение элементов на интегральных схемах.
В 1989 году Карнеги Мэллон создает беспилотный автомобиль с использованием нейронных сетей.
В 1988 году компьютер Deep Thought играет против чемпиона мира по шахматам Гарри Каспарова, но проигрывает ему, через 8 лет у них проходит очередная игра, и опять Каспаров оказывается сильнее компьютера. Но уже всего лишь через год, в 1997 году – сильно апгрейденный шахматный суперкомпьютер Deep Blue от IBM одерживает победу над Гарри Гаспаровым, и он становится первым компьютером, выигравшим у действующего чемпиона мира по шахматам. Начиная с 2000-х годов компьютеры стабильно выигрывают у людей.
В 1999 году компания Sony анонсирует собачку Айбо, навыки и поведение которой развиваются со временем. В этом же году впервые Массачусетский технологический институт показывает эмоциональный ИИ под названием Кисмет, который может распознавать эмоции людей и реагировать на них соответствующим образом.
В 2002 году начинается массовое производство автономных пылесосов iRobot, которые умеют перемещаться по дому самостоятельно, избегая препятствий.
В 2009 году Google подключается к гонке компаний по разработке собственного беспилотного автомобиля.
В 2011 году появляются Siri, Google Now и Cortana, умные виртуальные ассистенты. В 2014 году к ним присоединится Alexa от Amazon, а в 2017 году Алиса от Яндекса.
Помните мы говорили про Тест Тьюринга, который был изобретен Аланом Тьюрингом в 1950 году и был предназначен чтобы понять сможет ли ИИ обмануть человека и убедить его, что перед ним не компьютер, а человек. Так вот в 2014 году компьютерный чатбот Эжен Густман прошел этот тест, заставив треть жюри поверить, что компьютером управлял человек, а не ИИ.
В 2016 году Deep Mind от Google под названием Alpha Go побеждает чемпиона по игре в Го. Игра Го намного сложнее шахмат, здесь больше вариантов развития игры, и тем не менее Го стала второй игрой, в которой люди больше не могут выиграть.
В 2017 году после более чем 10 лет попыток и неудач, две команды независимо друг от друга разработали свои модели ИИ, компьютеры DeepStack и Libratus, которые смогли обыграть профессионалов в покер. В отличие от Го и шахмат, где все подчиняется строгим правилам, в покере на первый план выходит человеческий фактор. Потому что покер – во многом психологическая игра, построенная на эмоциях, невербальной коммуникации, умении блефовать и распознавать блеф.
Один из участников игры в покер с этими компьютерами так описал свои впечатления: «Это как играть с кем-то, кто видит все твои карты. Я не обвиняю нейросеть в нечестной игре, просто она действительно настолько хороша».
В 2015 году Илон Маск и Сэм Альтман, президент Y Combinator, основали компанию OpenAI, чтобы создать «открытый и дружественный» искусственный интеллект.
В 2017 году команда разработчиков OpenAI решила натренировать свою нейросеть в крупнейшей киберспортивной игре Dota 2. В этой игре играют команды по 5 человек, и они используют множество комбинаций из более чем сотни героев. У каждого из них есть свой набор навыков, За две недели нейросеть смогла обучиться и победить нескольких лучших игроков мира в режиме один на один, и сейчас ее создатели готовятся выпустить версию для основного режима, пять на пять.
Перемещаемся еще ближе к нашим дням. В начале 2018 году алгоритмы от Alibaba и Microsoft превзошли человека в тесте на понимание прочитанного текста.
В марте 2018 года небольшой робот собрал кубик Рубика за 0,38 секунды. Рекорд среди людей до этого составлял – 4,69 секунды.
Одним из самых важных прорывов в развитии ИИ, который может принести много пользы человечеству, стало то, что в мае 2018 искусственный интеллект стал лучше людей распознавать рак кожи.
Кроме распознавания заболеваний у пациентов, алгоритмы ИИ используются сегодня для исследования сворачивания белка, пытаясь найти лекарство от болезней Альцгеймера и Паркинсона. ИИ используется также для снижения уровня потребляемой энергии, и создания новых революционных материалов.
Искусственный интеллект активно применяется и в бизнесе – банки используют его для одобрения кредитов, а розничные компании применяют его для более точечных рекламных компаний и предложений для своих клиентов.
Почему же именно в наше время ИИ стал так быстро набирать скорость. Этому есть две причины. Во-первых, сейчас в мире производится огромное количество информации. Каждые два года, объем информации в мире удваивается. А как мы знаем, ИИ учится на имеющихся данных. И вторая причина – это наличие сильных вычислительных мощностей. Наши компьютеры сегодня достаточно сильные, чтобы они умели обрабатывать эти объемы информации в достаточно ограниченные сроки.
Итак, мы посмотрели на краткую историю развития ИИ. В одной из следующих глав мы посмотрим, чего же можно ожидать от развития ИИ в будущем.
Различие между ИИ, машинным обучением, глубинным обучением и нейронными сетями
Сегодня зачастую термины искусственный интеллект, машинное обучение (МО), глубокое обучение (ГО), нейронные сети (НС), Биг Дата используются взаимозаменяемо. И хотя они действительно очень связаны между собой, давайте разберемся что представляет собой каждое из этих понятий, и чем они отличаются.
Во-первых, если говорить очень кратко, то искусственный интеллект – это достаточно широкая отрасль, которая в свою очередь охватывает и машинное и глубокое обучение. МО является подвидом ИИ, а ГО является подвидом МО.
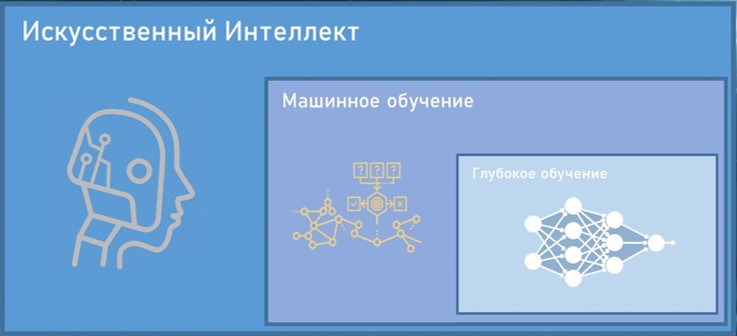
Под ИИ подразумевается, что компьютер может выполнять такие задачи, которые может выполнять и человек. И здесь дело касается не просто каких-то механических действий, например, поднять и отнести какой-то предмет, а задачи, которые требуют интеллектуального мышления, то есть, когда надо принять правильное решение. Например, задача выиграть в шахматы, или распознать что изображено на картинке, или понять, что было произнесено собеседником и выдать правильный ответ.
Для этого компьютеру дают множество правил или алгоритмов, следуя которым, он смог бы поступать так же, как поступал бы человек.
ИИ может быть узким (narrow AI) либо его еще иногда называют слабым, то есть когда машина может справляться только с ограниченным видом задач, лучше чем человек. Например, распознать, что на картинке или сыграть в шахматы и выиграть. Именно на этом этапе развития ИИ мы сейчас находимся. Следующий этап – это общий ИИ (general AI), когда ИИ может решить любую интеллектуальную задачу так же хорошо, как человек. И финальный этап – это сильный ИИ, когда ИИ справляется с большинством задач намного лучше, чем человек.
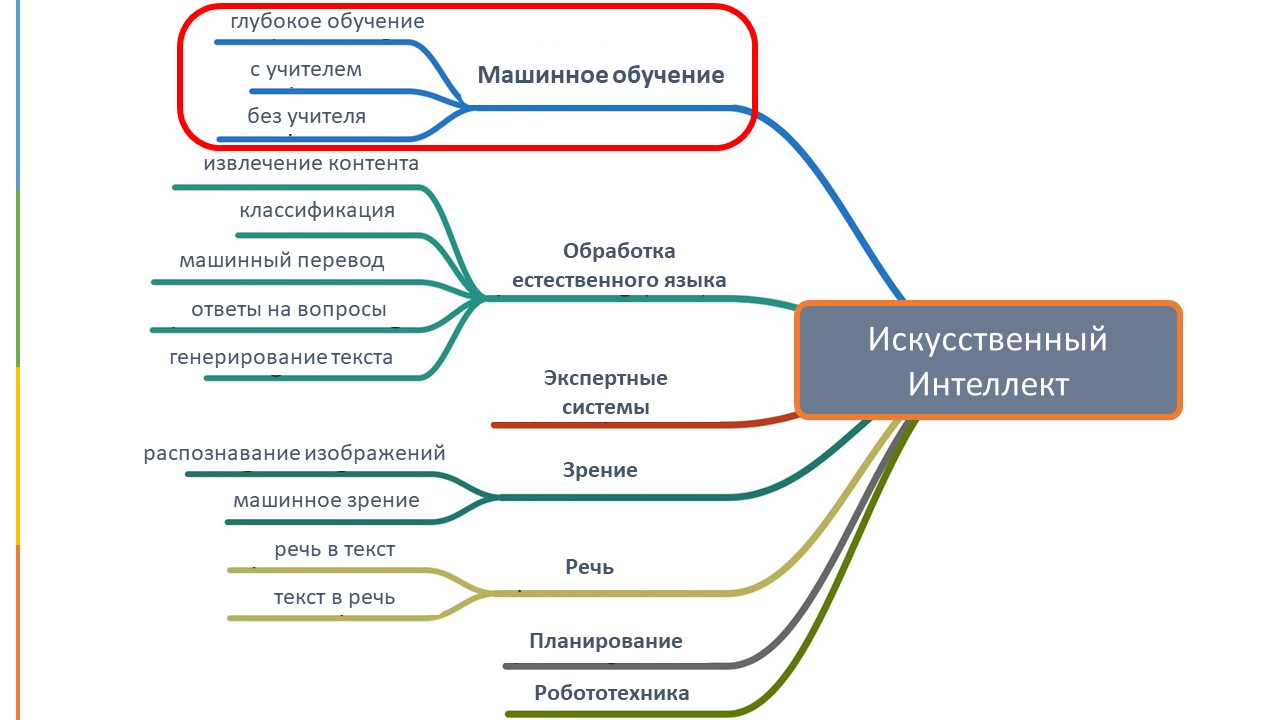
Как мы уже сказали, ИИ – это достаточно обширная область знаний. Она включает в себя следующие направления.
1. Обработка естественного языка, когда компьютер должен понимать, что написано, и выдать правильный и релевантный ответ. Сюда же входят переводы текстов и даже составление сложных текстов компьютерами.
2. Экспертные системы – это компьютерные системы, которые имитируют способность принятия решений человеком, в основном с помощью правил «если – то», нежели с использованием какого-то кода.
3. Речь – компьютер должен распознавать речь людей и сам уметь разговаривать.
4. Компьютерное зрение – компьютеры распознают те или иные объекты на изображении или при движении.
5. Робототехника – также очень популярное направление ИИ, создание роботов, которые могут выполнять различные функции, в том числе двигаться и общаться, преодолевать препятствия.
6. Автоматическое планирование – обычно используется автономными роботами и беспилотными аппаратами, когда им необходимо выполнять последовательность действий, особенно когда это происходит в многомерном пространстве и когда им приходится решать комплексные задачи.
7. И наконец, Машинное обучение.
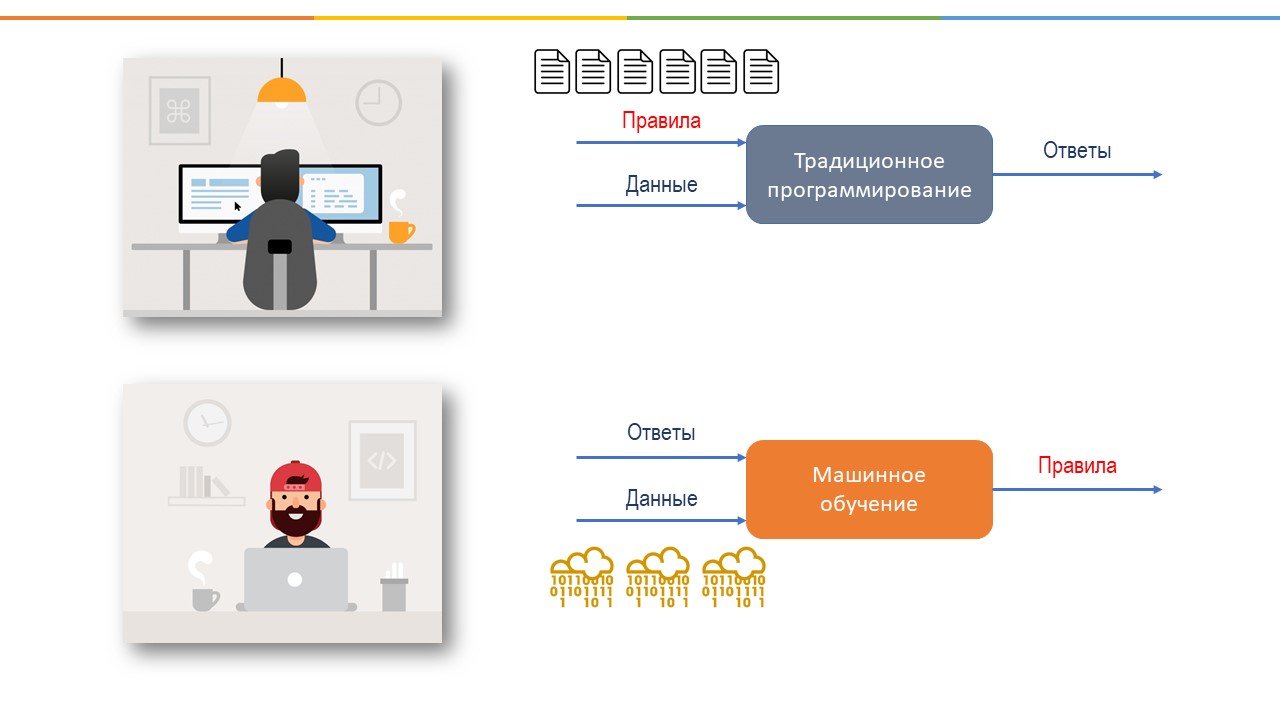
Машинное обучение появилось после того, как долгое время мы пытались сделать компьютер умнее, давая ему все больше и больше правил и инструкций. Однако, это оказалось не такой уж и хорошей идеей, потому что отнимало много времени, и мы не могли придумать правила для каждой детали и для каждой ситуации.
И тогда ученые пришли к выводу, а почему бы не написать алгоритмы, которые учатся самостоятельно на основе опыта. Так родилось машинное обучение. То есть, когда машины могут учиться на основе больших наборов данных вместо явно написанных инструкций и правил.
МО – это область ИИ, когда мы тренируем наш алгоритм с помощью набора данных, делая его все лучше, точнее и более эффективным. При машинном обучении наши алгоритмы обучаются на основе данных, но без заранее запрограммированных инструкций. То есть мы даем машине большой набор данных, и говорим правильные ответы, и потом машина сама создает алгоритмы, которые бы удовлетворяли этим ответам. И с каждым новым дополнительным объемом данных, машина учится дальше и еще больше улучшает свою точность прогнозов.
Например, если взять пример шахмат, то в примере с ИИ, мы даем машине много логических правил, и на их основе она учится играть. А в примере с МО, мы даем машине много примеров прошлых игр, она изучает их и анализирует почему одни игроки выигрывали, а другие проигрывали, какие шаги вели к успеху, а какие – к поражению. И на основе этих примеров, машина сама создает алгоритмы и правила как надо играть в шахматы, чтобы выиграть.
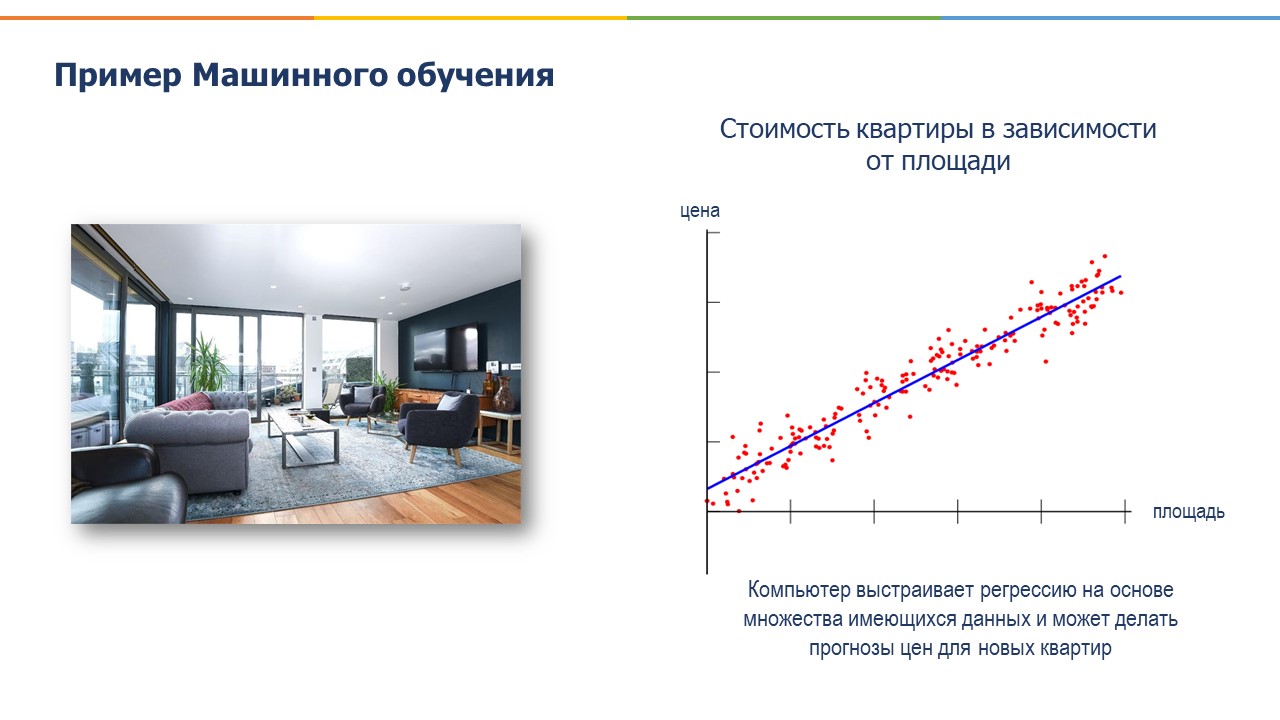
Другой пример, предположим, нам надо понять, как будет вести себя цена квартиры при изменении тех или иных параметров, например, в зависимости от площади, удаленности от метро, этажности и прочих факторов. Мы загружаем данные с разными квартирами, и компьютер создает модель, по которой можно будет предсказать цены в зависимости от этих факторов. Мы можем регулярно обновлять эти данные, и наш алгоритм будет обучаться на основе этих новых данных и каждый раз будет усовершенствовать свою точность по предсказанию цены в зависимости от параметров.
Идем дальше. Глубокое обучение – это подотрасль МО, то есть здесь тоже компьютер обучается, но обучается немного по-другому, чем в стандартном МО. В ГО используются нейронные сети (НС), которые представляют собой алгоритмы, повторяющие логику нейронов человеческого мозга. Большие объемы данных проходят через эти нейронные сети, и на выходе выдаются уже готовые ответы. Нейронные сети намного сложнее, чем обычное машинное обучение, и мы можем не всегда понимать, какие факторы имеют больший вес на тот или иной ответ, но использование нейронных сетей также помогает решать очень запутанные задачи в наше время. Иногда нейронные сети называют даже черным ящиком, потому что мы не всегда можем понять, что происходит внутри этих сетей.
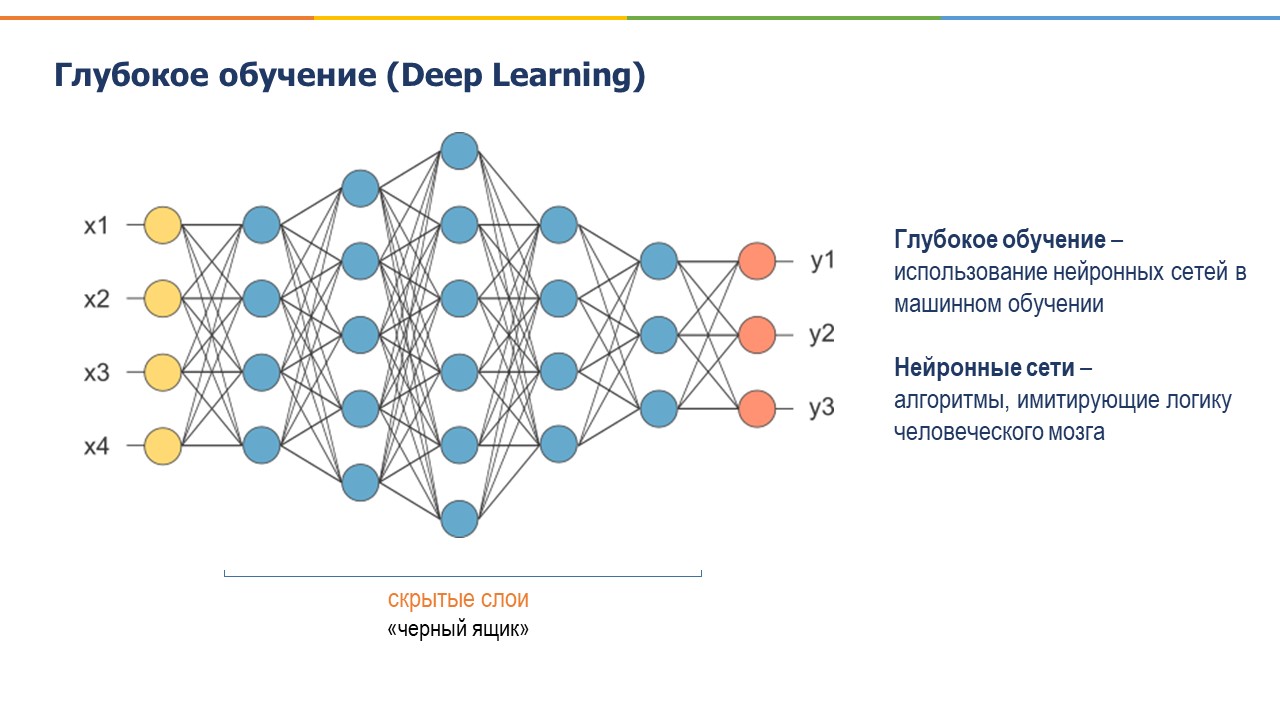
Предположим, ваш компьютер оценивает, насколько хорошо написано эссе. Если вы используете ГО, то компьютер вам просто выдаст финальное решение, что эссе хорошее либо нет, и скорее всего, ответ будет очень близок к тому, как бы оценил это эссе человек. Но вы не сможете понять, почему было принято такое решение, потому что в ГО используются несколько уровней НС, что делает его очень трудно интерпретируемым. Вы не будете знать какой узел НС был активирован, и как эти узлы вели себя вместе, чтобы прийти к этому результату. Если же вы используете МО, например, алгоритм «дерево решений», то там видно какой фактор сыграл решающую роль в определении качества эссе.
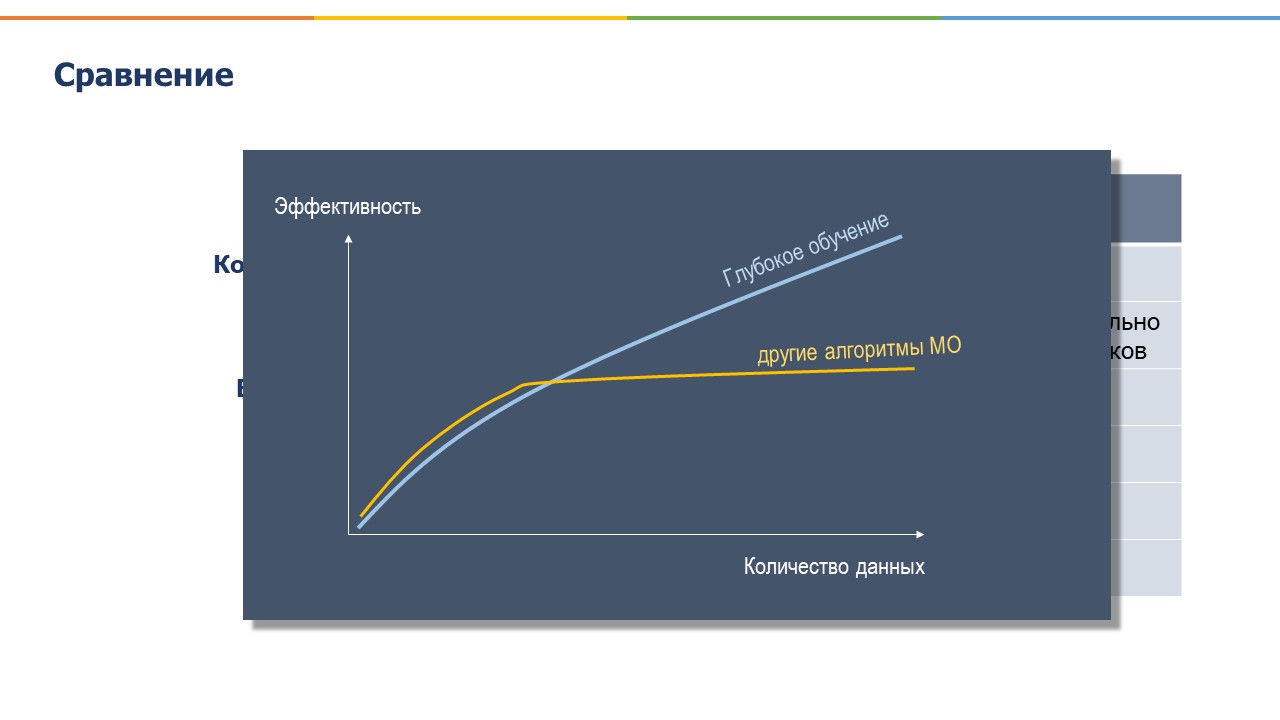
Нейронные сети были известны еще в 20 веке, но тогда они были не настолько глубокими, там был всего один или два слоя, и они не давали таких хороших результатов, как другие алгоритмы МО. Поэтому на какое-то время они отошли на второй план. Однако они стали популярны в последнее время, особенно примерно с 2006 года, когда появились огромные наборы данных и сильные компьютерные мощности, в частности, видео карты и мощные процессоры, которые стали способны создавать более глубокие слои НС и делать вычисления более эффективно.
По этим же причинам, ГО является достаточно дорогим. Потому что, во-первых, сложно собрать большие данные по определенным признакам и, во-вторых, серьезные вычислительные способности компьютеров – тоже достаточно дорогое удовольствие.
Если вкратце, то каким образом работает ГО. Предположим, наша задача вычислить сколько единиц транспорта и какой именно транспорт (то есть автобусы, грузовики, машины или велосипеды) проходит через определенную трассу в день, чтобы в дальнейшем распределить полосы движения.
Для этой цели нам надо научить наш компьютер распознавать виды транспорта. Если бы мы решали эту задачу с помощью МО, мы бы написали алгоритм, в котором указывали бы характеристики машин, автобусов, грузовиков и велосипедов, например, если количество колес 2, то мотоцикл, если длина движущегося средства более 5 метров, то грузовик либо автобус, если много окон, то автобус, и т.д. Но как понимаете, здесь много подводных камней. Например, автобус может быть затонированным и будет трудно понять, где там окна, либо грузовик может выглядеть как автобус или наоборот, да и крупные машины пикапы выглядят как некоторые небольшие грузовики.
Поэтому другой вариант решения этой задачи, это загрузить большое количество изображений с разными видами транспорта в наш компьютер и просто указать ему, на каких изображениях изображен мотоцикл, автомобиль, грузовик или автобус. Компьютер сам начнет подбирать характеристики, по которым можно определить, что за вид транспорта изображен и как их можно отличить друг от друга. После этого мы загрузим еще некоторое количество изображений и протестируем насколько хорошо компьютер справляется с задачей. Если он будет ошибаться, мы укажем ему, что вот здесь ты ошибся, здесь не грузовик, а автобус. Компьютер, в свою очередь, вернется назад к своим алгоритмам (это называется backpropagation) и внесет туда какие-то изменения, и мы начнем заново по кругу до тех пор, пока компьютер не начнет угадывать, что изображено на картинке с очень большой долей вероятности. Это и называется глубокое обучение на основе нейронных сетей. Как вы понимаете, это может занимать достаточно долгое время, может быть несколько недель, в зависимости от сложности поставленной задачи, также требует наличия большого количества данных, желательно, чтобы было от миллиона изображений и выше, и все эти изображения должны либо быть промаркированы, либо это должен делать человек, но это будет очень затратно по времени.
Давайте еще раз сравним МО и ГО по разным параметрам.
Если суммировать:
ГО является подобластью МО, и они оба подпадают под более широкое определение ИИ.
МО использует алгоритмы, чтобы разбирать данные, обучаться на их основе, и принимать взвешенные решения на основе обученного.
ГО делает то же самое, так как оно тоже является разновидностью МО, но специфика ГО в том, что при нем алгоритмы структурируются в несколько слоев, чтобы создать искусственную нейронную сеть, которая может тоже обучаться и принимать умные решения.