
Нейросети. Генерация изображений
– Дополнительные слои нормализации: такие как Instance Normalization, Layer Normalization и другие, которые могут быть применены для стабилизации и нормализации данных.
– Слои внимания (Attention Layers): позволяют сети фокусироваться на определенных участках данных и улавливать более важные информационные паттерны.
Архитектура GAN является творческим процессом, и часто оптимальные решения могут быть найдены только через эксперименты и исследования. Разработчики и исследователи должны аккуратно подбирать слои и их параметры, учитывая особенности конкретной задачи и типа данных.
Ориентирование в различных типах слоев нейронных сетей может быть сложной задачей, особенно для начинающих. Шпаргалки – это полезные и компактные ресурсы, которые помогают быстро вспомнить основные характеристики каждого слоя и их применение. Ниже представлены примеры удобных шпаргалок для ориентирования в слоях нейронных сетей:
Шпаргалка по сверточным слоям (Convolutional Layers)

2. Шпаргалка по рекуррентным слоям (Recurrent Layers):

3. Шпаргалка по полносвязным слоям (Fully Connected Layers):

Это примеры исходя из наиболее популярных слоев. Помните, что существует множество других типов слоев и их вариантов, которые могут быть использованы для различных задач и в разных архитектурах нейронных сетей. При работе с GAN и другими нейронными сетями, рекомендуется глубже изучить каждый тип слоя и экспериментировать с их комбинациями для оптимизации вашей конкретной задачи.
Глава 2: Подготовка данных для обучения
2.1. Сбор и подготовка данных для обучения GANСбор и подготовка данных для обучения генеративных нейронных сетей (GAN) – это критически важный процесс, который требует внимания к деталям, чтобы обеспечить успешное обучение модели и достижение хороших результатов. В этом процессе следует учитывать не только сбор данных из источников, но и предобработку данных, чтобы они были готовы к использованию в обучении. Давайте рассмотрим этот процесс более подробно:
1. Определение целевого домена и данных:
Важным первым шагом является определение целевого домена данных, в котором вы хотите использовать генеративную нейронную сеть. Это может быть область, связанная с изображениями, текстами, аудио, видео или другими типами данных.
2. Выбор источника данных
После определения целевого домена данных для обучения генеративных нейронных сетей (GAN) важно выбрать подходящий источник данных. Выбор источника данных зависит от доступности данных, типа задачи и конкретных требований вашего проекта. Вот несколько типов источников данных, которые можно использовать для обучения GAN:
–Общедоступные базы данных:
В Интернете существует множество общедоступных баз данных, содержащих различные типы данных, такие как изображения, тексты, аудио и видео. Некоторые популярные базы данных, которые часто используются для обучения GAN, включают CIFAR-10, MNIST, ImageNet и др. Они предоставляют большой объем разнообразных данных и являются отличным выбором для начала работы.
–Создание собственных данных:
Если доступные общедоступные базы данных не соответствуют вашим требованиям или вы хотите решать уникальную задачу, вы можете создать свои собственные данные. Например, вы можете сделать снимки объектов, записать аудио или составить текстовый корпус.
–Данные из внешних источников:
Если вам нужны данные, которые недоступны в открытых источниках, вы можете получить их из внешних источников с помощью веб-скрапинга или API. Некоторые веб-сайты предоставляют доступ к своим данным через API, что позволяет получить необходимую информацию.
–Синтез данных:
В некоторых случаях может быть сложно или невозможно найти подходящие реальные данные для вашей задачи. В таких случаях можно воспользоваться синтезом данных с помощью GAN. Генеративные сети могут быть обучены на существующих данных и создавать искусственные данные, которые будут похожи на реальные.
–Данные с различными источниками:
В некоторых проектах может быть полезно объединить данные из различных источников для обучения GAN. Это позволяет увеличить разнообразие данных и сделать модель более обобщающей.
Когда вы выбираете источник данных для обучения GAN, убедитесь, что у вас есть права на использование данных, особенно если данные являются чьей-то интеллектуальной собственностью. Также важно учитывать объем данных, доступность их загрузки и хранение, а также их качество и соответствие вашей задаче.
3. Сбор данных
На этапе сбора данных для обучения генеративных нейронных сетей (GAN) фактически происходит сбор и подготовка данных из выбранного источника. Этот этап играет критическую роль в успешности обучения GAN, и важно обратить внимание на несколько ключевых аспектов:
– Качество данных является одним из самых важных факторов в обучении GAN. Исходные данные должны быть точными, чистыми и соответствовать вашей задаче. Например, если вы работаете с изображениями, убедитесь, что они имеют достаточное разрешение и являются репрезентативными для объектов, которые вы хотите сгенерировать.
– Разнообразие данных играет важную роль в способности GAN обучаться различным шаблонам и особенностям в данных. Если данные слишком однообразны или монотонны, модель может стать склонной к генерации однотипных результатов. Поэтому старайтесь собрать данные, которые представляют различные варианты и разнообразные сценарии вашей задачи.
– Объем данных также имеет значение. Чем больше данных, тем лучше модель может выучить общие закономерности и особенности данных. Однако собирать огромные объемы данных не всегда возможно, поэтому важно найти баланс между объемом данных и их разнообразием.
– Очистка данных от шума и ошибок является важной частью процесса подготовки данных. Некачественные данные или выбросы могут негативно повлиять на обучение модели. Обратите внимание на предварительную обработку данных и исключите нежелательные аномалии.
– Если вы работаете с многоклассовыми данными, обратите внимание на баланс классов. Если одни классы сильно преобладают над другими, это может привести к несбалансированности модели. Постарайтесь собрать данные таким образом, чтобы каждый класс был достаточно представлен в обучающем наборе.
– Обязательно убедитесь, что у вас есть права на использование собранных данных, особенно если вы планируете использовать их для коммерческих целей или публикации результатов.
Правильная сборка и подготовка данных является важным этапом в обучении GAN и может существенно повлиять на качество и результаты модели. Чем более качественные и разнообразные данные вы соберете, тем лучше GAN сможет обучиться и создавать высококачественный контент.
2.2. Препроцессинг изображений: масштабирование, нормализация и другие техникиПрепроцессинг изображений является важным этапом подготовки данных перед обучением генеративных нейронных сетей (GAN). Цель препроцессинга – привести данные в определенный формат, нормализовать их и обработать для улучшения производительности и сходимости модели. В данной главе рассмотрим различные техники препроцессинга, такие как масштабирование, нормализация и другие.
1. Масштабирование (Rescaling):
Масштабирование – это процесс изменения масштаба изображений, чтобы они соответствовали определенному диапазону значений. Обычно изображения масштабируются к диапазону от 0 до 1 или от -1 до 1. Это делается для облегчения обучения модели, так как большие значения пикселей могут замедлить процесс обучения и ухудшить сходимость.
2. Нормализация (Normalization):
Нормализация – это процесс приведения значений пикселей изображений к некоторой стандартной шкале. Чаще всего используется нормализация по среднему значению и стандартному отклонению. Для этого каждый пиксель изображения вычитается из среднего значения пикселей и делится на стандартное отклонение всех пикселей в наборе данных. Нормализация помогает уменьшить влияние различных шкал значений пикселей на обучение модели и обеспечивает стабильность процесса обучения.
3. Центрирование (Centering):
Центрирование – это процесс вычитания среднего значения всех пикселей из каждого пикселя изображения. Это приводит к тому, что среднее значение всех пикселей в изображении становится равным нулю. Центрирование также помогает уменьшить влияние смещения на обучение модели.
4. Аугментация данных (Data Augmentation):
Аугментация данных – это методика, при которой исходные данные дополняются дополнительными преобразованиями или искажениями. В контексте обработки изображений, это может быть случайное изменение яркости, поворот, обрезка, зеркальное отражение и другие трансформации. Аугментация данных увеличивает разнообразие данных, что помогает улучшить обобщающую способность модели и уменьшить переобучение.
5. Удаление выбросов (Outlier Removal):
Удаление выбросов – это процесс удаления аномальных значений из набора данных. В некоторых случаях аномальные значения могут повлиять на обучение модели и привести к некорректным результатам. Удаление выбросов может улучшить качество модели.
6. Преобразование изображений (Image Transformation):
Преобразование изображений – это процесс изменения размера, поворота, переворота и других геометрических трансформаций изображений. Это может быть полезно, например, при работе с изображениями разных размеров или при создании дополнительных данных для обучения.
Применение различных техник препроцессинга данных для генеративных нейронных сетей (GAN) может существенно повлиять на производительность и качество модели. Выбор определенных методов препроцессинга зависит от особенностей данных и требований к конкретной задаче. Оптимальный набор техник препроцессинга поможет создать более стабильную и эффективную GAN для генерации данных.
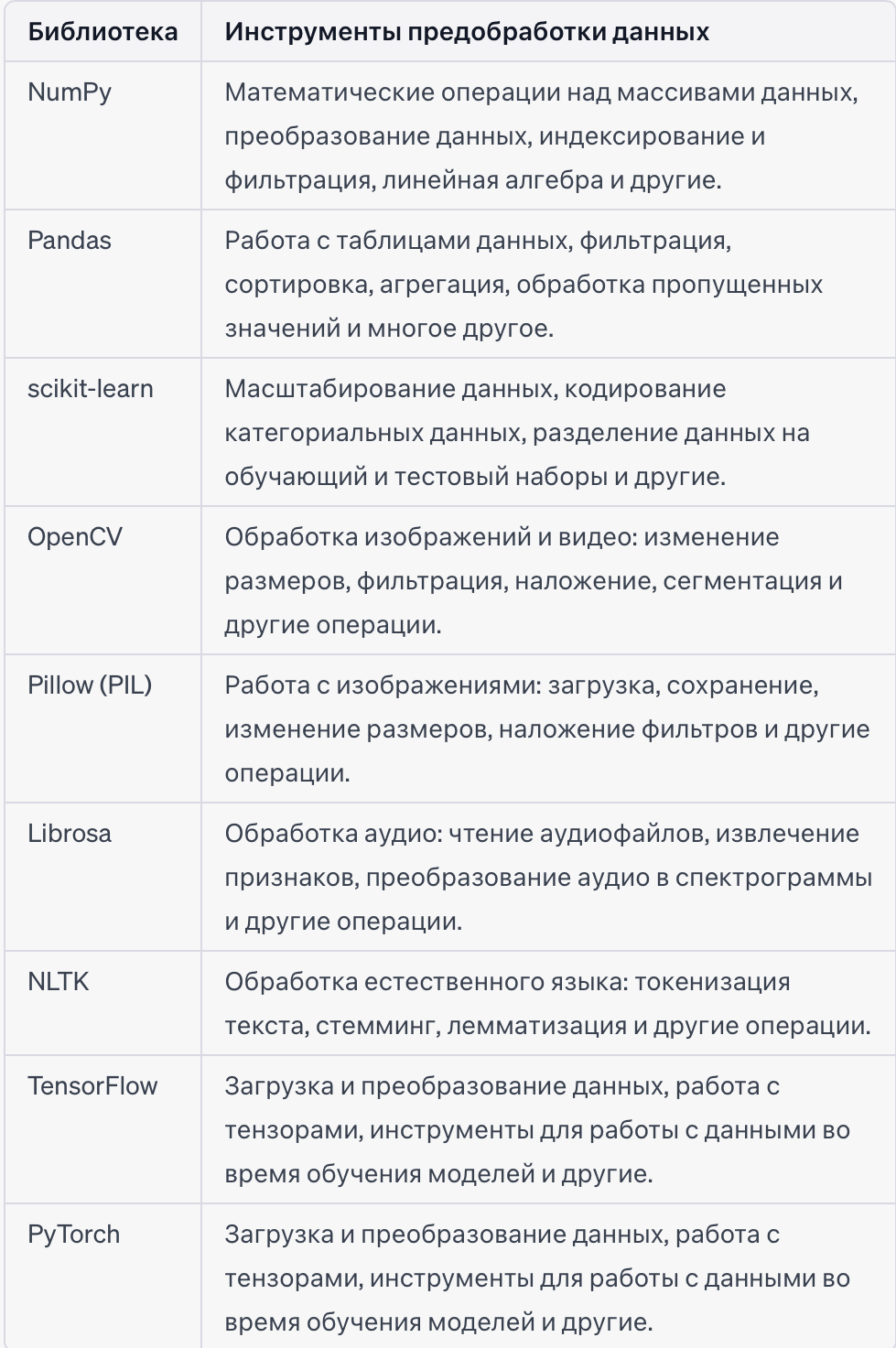
Предобработка данных
После сбора данных следует предобработать их для подготовки к обучению GAN. Этот шаг может включать в себя следующие действия:
– Приведение изображений к одному размеру и формату, если используются изображения.
– Нормализацию данных для сведения их к определенному диапазону значений (например, от -1 до 1) или стандартизацию данных.
– Очистку данных от нежелательных символов или шумов.
– Токенизацию текстовых данных на отдельные слова или символы.
– Удаление выбросов или аномальных значений.
***
Для задачи приведения изображений к одному размеру и формату можно использовать следующие инструменты:
Pillow – это библиотека Python для работы с изображениями. Она предоставляет широкий набор функций для загрузки, сохранения и манипулирования изображениями, включая изменение размеров. Вы можете использовать функцию `resize()` из библиотеки Pillow для изменения размеров изображений на заданный размер.
OpenCV – это библиотека компьютерного зрения, которая также предоставляет функции для работы с изображениями. Она может быть использована для изменения размеров изображений с помощью функции `cv2.resize()`.
scikit-image – это библиотека Python для обработки изображений. Она предоставляет функцию `resize()` для изменения размеров изображений.
Пример использования библиотеки Pillow для приведения изображений к одному размеру:
```python
from PIL import Image
# Загрузка изображения
image = Image.open("image.jpg")
# Приведение изображения к заданному размеру (например, 256x256 пикселей)
desired_size = (256, 256)
resized_image = image.resize(desired_size)
# Сохранение приведенного изображения
resized_image.save("resized_image.jpg")
```
Важно отметить, что при приведении изображений к одному размеру следует учитывать аспекты сохранения пропорций изображений, чтобы изображения не были искажены. Многие из указанных библиотек предоставляют возможность сохранять пропорции при изменении размера, что обычно рекомендуется для сохранения качества изображений.
Выбор конкретного инструмента зависит от ваших предпочтений и требований проекта.
***
Для нормализации данных и приведения их к определенному диапазону значений (например, от -1 до 1) или стандартизации данных можно использовать следующие инструменты, доступные в различных библиотеках:
NumPy предоставляет множество функций для работы с массивами данных и выполнения математических операций. Для нормализации данных можно использовать функции `numpy.min()`, `numpy.max()` для вычисления минимального и максимального значения в массиве, а затем выполнить нормализацию с помощью арифметических операций.
scikit-learn предоставляет класс `MinMaxScaler`, который позволяет выполнить минимакс-нормализацию данных и привести их к определенному диапазону значений. Также есть класс `StandardScaler` для стандартизации данных путем приведения их к нулевому среднему и единичному стандартному отклонению.
Как две основные библиотеки глубокого обучения, TensorFlow и PyTorch также предоставляют возможности для нормализации данных. В TensorFlow это можно сделать с помощью функции `tf.keras.layers.BatchNormalization`, а в PyTorch с помощью класса `torch.nn.BatchNorm2d`.
При работе с таблицами данных в Pandas можно использовать функции `DataFrame.min()` и `DataFrame.max()` для вычисления минимального и максимального значения в колонках, а затем выполнить нормализацию или стандартизацию данных с помощью арифметических операций.
Пример нормализации данных с использованием MinMaxScaler из библиотеки scikit-learn:
```python
from sklearn.preprocessing import MinMaxScaler
# Пример данных (замените data на свои данные)
data = [[10], [5], [3], [15]]
# Создание объекта MinMaxScaler и выполнение нормализации
scaler = MinMaxScaler(feature_range=(-1, 1))
normalized_data = scaler.fit_transform(data)
print(normalized_data)
```
В результате данных будут приведены к диапазону от -1 до 1. Конкретный выбор инструмента зависит от ваших потребностей и предпочтений, а также от того, в какой библиотеке вы работаете и с каким типом данных.
***
Инструменты и библиотеки для очистки данных от нежелательных символов или шумов в изображениях:
OpenCV:
– Фильтры Гаусса (`cv2.GaussianBlur`) для размытия изображений и удаления шума.
– Медианные фильтры (`cv2.medianBlur`) для сглаживания и устранения шума.
– Билатеральные фильтры (`cv2.bilateralFilter`) для сглаживания, сохраняющего границы и устранения шума.
scikit-image:
– Фильтры Гаусса (`skimage.filters.gaussian`) для размытия изображений и удаления шума.
– Медианные фильтры (`skimage.filters.median`) для сглаживания и устранения шума.
– Адаптивные фильтры (`skimage.restoration.denoise_tv_bregman`) для денойзинга с сохранением границ.
Denoising Autoencoders (DAE):
– Нейронные сети, такие как TensorFlow или PyTorch, могут быть использованы для реализации денойзинг автоэнкодеров.
Методы сегментации:
– Пороговая сегментация (`cv2.threshold`) для разделения изображения на передний и задний план.
– Вычитание фона (`cv2.absdiff`) для удаления нежелательного фона из изображения.
Алгоритмы устранения:
– Морфологические операции (`cv2.erode`, `cv2.dilate`) для устранения мелких артефактов или шумов.
– Фильтры устранения шума (`cv2.fastNlMeansDenoising`) для удаления шумов с сохранением деталей.
Улучшение качества:
– Методы суперразрешения (`skimage.transform.resize`, `cv2.resize`) для увеличения размеров изображений с улучшением качества.
– Фильтры повышения резкости (`cv2.filter2D`, `skimage.filters.unsharp_mask`) для улучшения четкости изображений.
Для примера очистки изображений от шумов, мы будем использовать библиотеку `scikit-image`. Установите ее, если она еще не установлена, используя команду:
```bash
pip install scikit-image
```
Предположим, у нас есть изображение с шумом и мы хотим очистить его. Для этого используем фильтр Гаусса и медианный фильтр. Ниже приведен пример кода:
```python
import numpy as np
import matplotlib.pyplot as plt
from skimage import io, img_as_ubyte, img_as_float
from skimage.filters import gaussian, median
# Загрузим изображение с шумом
image_with_noise = io.imread('image_with_noise.jpg')
image_with_noise = img_as_float(image_with_noise)
# Применим фильтр Гаусса для устранения шума
image_gaussian_filtered = gaussian(image_with_noise, sigma=1)
# Применим медианный фильтр для устранения шума
image_median_filtered = median(image_with_noise)
# Выведем исходное изображение и обработанные изображения для сравнения
plt.figure(figsize=(10, 4))
plt.subplot(131)
plt.imshow(image_with_noise, cmap='gray')
plt.title('Исходное изображение с шумом')
plt.subplot(132)
plt.imshow(image_gaussian_filtered, cmap='gray')
plt.title('Фильтр Гаусса')
plt.subplot(133)
plt.imshow(image_median_filtered, cmap='gray')
plt.title('Медианный фильтр')
plt.tight_layout()
plt.show()
```
Обратите внимание, что в этом примере мы загружаем изображение, приводим его к числовому формату с плавающей точкой, применяем фильтры Гаусса и медианный фильтр для устранения шума, и затем выводим исходное изображение с шумом и обработанные изображения для сравнения.
Пожалуйста, замените `'image_with_noise.jpg'` на путь к вашему изображению с шумом.
***
Для работы с изображениями и их токенизации на отдельные символы или пиксели обычно используется библиотека Python `PIL` (Python Imaging Library), которая теперь известна как `Pillow`. `Pillow` является форком оригинальной библиотеки `PIL` и предоставляет мощные инструменты для работы с изображениями в Python.
Для токенизации изображения на отдельные символы или пиксели можно использовать методы из библиотеки `Pillow`, такие как `Image.getdata()` или `numpy.array`. Вот пример:
```python
from PIL import Image
# Загрузим изображение
image = Image.open('example_image.jpg')
# Токенизируем изображение на пиксели
pixel_data = list(image.getdata())
# Токенизируем изображение на символы (если оно содержит текстовую информацию)
# Необходимо использовать OCR (Optical Character Recognition) библиотеки для распознавания текста.
```
Здесь `Image.open()` открывает изображение, а `image.getdata()` возвращает пиксели изображения в виде списка. Обратите внимание, что при токенизации изображений на символы, если изображение содержит текстовую информацию, для распознавания текста потребуются специализированные библиотеки OCR (например, Tesseract или pytesseract).
Токенизация изображений более сложная задача по сравнению с токенизацией текста, и в большинстве случаев требует специфических алгоритмов и инструментов в зависимости от конкретной задачи и целей обработки изображений.
***
Для удаления выбросов или аномальных значений на изображениях можно использовать различные инструменты и методы, которые предоставляют библиотеки для обработки изображений. Вот некоторые из них:
Конкретные инструменты для удаления выбросов или аномальных значений могут отличаться в каждой библиотеке. Вот примеры инструментов из библиотек OpenCV и scikit-image:
OpenCV:
В OpenCV для удаления выбросов можно использовать функцию `cv2.GaussianBlur`, которая применяет фильтр Гаусса к изображению для сглаживания и устранения шумов:
```python
import cv2
# Загрузим изображение
image = cv2.imread('example_image.jpg')
# Применим фильтр Гаусса для удаления выбросов
image_filtered = cv2.GaussianBlur(image, (5, 5), 0)
```
Также в OpenCV доступны другие фильтры для обработки изображений, такие как медианный фильтр (`cv2.medianBlur`) или билатеральный фильтр (`cv2.bilateralFilter`), которые также могут использоваться для удаления шумов и аномалий.
scikit-image:
В scikit-image для удаления выбросов можно использовать функции из подмодуля `filters`, такие как `gaussian`, `median` и другие:
```python
from skimage import io, img_as_ubyte
from skimage.filters import gaussian, median
# Загрузим изображение
image = io.imread('example_image.jpg')
image = img_as_ubyte(image)
# Применим фильтр Гаусса для удаления выбросов
image_gaussian_filtered = gaussian(image, sigma=1)
# Применим медианный фильтр для удаления выбросов
image_median_filtered = median(image)
```
Здесь мы использовали функции `gaussian` и `median` из `skimage.filters` для применения фильтров Гаусса и медианного фильтра к изображению с целью удаления выбросов и шумов.
Обратите внимание, что конкретный выбор инструментов и методов для удаления выбросов может зависеть от ваших данных, задачи и целей обработки изображений. Рекомендуется прочитать документацию соответствующих библиотек, чтобы более полно ознакомиться со всеми доступными функциями и их параметрами.
Разделение данных на обучающую и тестовую выборки
После предобработки данных следующим шагом является разделение их на обучающую и тестовую выборки. Этот процесс позволяет оценить производительность и качество модели на данных, которые она ранее не видела. Обучающая выборка будет использоваться для обучения GAN, а тестовая выборка будет использоваться для оценки, насколько хорошо модель обобщает на новых данных.
Обычно данные разделяют случайным образом в заданном соотношении, например, 80% данных используется для обучения, а оставшиеся 20% – для тестирования. В некоторых случаях может быть полезно использовать кросс-валидацию для более надежной оценки производительности модели.
В Python для разделения данных на обучающую и тестовую выборки часто используются библиотеки `scikit-learn` или `tensorflow.keras` (если вы работаете с нейронными сетями на базе TensorFlow). Вот примеры использования обеих библиотек:
С использованием scikit-learn:
```python
from sklearn.model_selection import train_test_split
# X – признаки (входные данные), y – метки (целевая переменная)
X, y = … # Ваши предобработанные данные
# Разделим данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
```
В этом примере мы использовали функцию `train_test_split` из `sklearn.model_selection` для разделения данных `X` и `y` на обучающую и тестовую выборки в соотношении 80:20. Параметр `test_size=0.2` указывает на то, что 20% данных будут использоваться для тестирования, а `random_state=42` обеспечивает воспроизводимость разделения данных.
С использованием tensorflow.keras:
```python
import tensorflow as tf
# X – признаки (входные данные), y – метки (целевая переменная)
X, y = … # Ваши предобработанные данные
# Разделим данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = tf.keras.train_test_split(X, y, test_size=0.2, random_state=42)