
Машинное обучение и Искусственный Интеллект
Когда для модели отображается изображение птицы, она маркирует изображение с некоторой степенью достоверности.
Этот тип машинного обучения называется контролируемым обучением, где алгоритм обучается на данных, размеченных человеком.

Чем больше примеров мы предоставляем контролируемому алгоритму обучения, тем точнее он производит классификацию новых данных.
Неуправляемое обучение, это еще один тип машинного обучения, которое основывается на предоставлении алгоритму неразмеченных данных и позволяет ему самостоятельно находить шаблоны.
Вы предоставляете просто входные данные, и позволяете машине делать выводы и находить шаблоны.
Этот тип обучения может быть полезен для кластеризации данных, когда данные группируются в соответствии с тем, насколько они похожи на своих соседей и отличаются от всего остального.
Как только данные кластеризованы, можно использовать различные методы для изучения этих данных и поиска шаблонов.
Например, можно создать алгоритм машинного обучения с постоянным потоком сетевого трафика и позволить ему независимо изучать активность в сети – базовый уровень, нормальную сетевую активность, а также выбросы и, возможно, злонамеренное поведение, происходящее в сети.

Третий тип алгоритма машинного обучения, обучение с подкреплением, это алгоритм машинного обучения с набором правил и ограничений и позволяет ему учиться достигать целей.
Вы определяете состояние, желаемую цель, разрешенные действия и ограничения.
И алгоритм выясняет, как достичь цели, пробуя различные комбинации разрешенных действий, и его награждают или наказывают в зависимости от того, было ли решение правильным.
Алгоритм изо всех сил старается максимизировать свои вознаграждения в рамках предусмотренных ограничений.
И вы можете использовать обучение с подкреплением, чтобы научить машину играть в шахматы или преодолеть какие-либо препятствия.
Таким образом, машинное обучение – это широкая область, и мы можем разделить его на три разные категории: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением.
И есть много разных задач, которые мы можем решить с помощью них.
В контролируемом обучении, в наборе данных есть метки, и мы используем их для построения модели классификации данных.
Это означает, что, когда мы получаем данные, у них есть метки, которые говорят о том, что представляют эти данные.
В примере с сердцем, у нас была таблица с метками, это сердечный ритм, возраст, пол и вес.
И каждой такой метке соответствовали значения.
При неконтролируемом обучении у нас нет меток, и мы должны обнаружить эти метки в неструктурированных данных.
И такие вещи обычно делаются с помощью кластеризации.
Обучение с подкреплением – это другое подмножество машинного обучения, и оно использует вознаграждение для наказания за плохие действия или вознаграждение за хорошие действия.
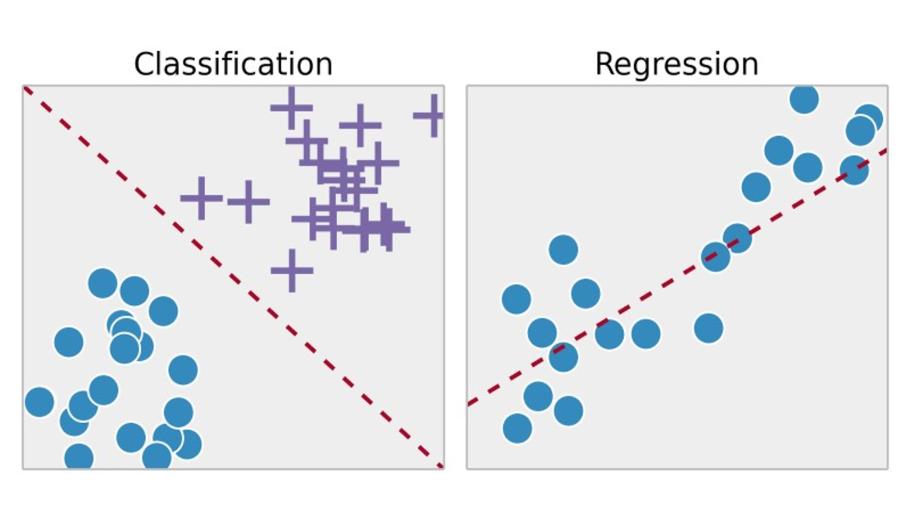
И мы можем разделить контролируемое обучение на три категории: регрессия, классификация и нейронные сети.
Модели регрессии строятся с учетом взаимосвязей между признаками x и результатом y, где y – непрерывная переменная.
По сути, регрессия оценивает непрерывные значения.
Нейронные сети относятся к структурам, которые имитируют структуру человеческого мозга.
Классификация, с другой стороны, фокусируется на дискретных значениях, которые она идентифицирует.
Мы можем назначить дискретные результаты y на основе многих входных признаков x.
В примере с сердцем, учитывая набор признаков x, таких как удары в минуту, вес тела, возраст и пол, алгоритм классифицирует выходные данные y как две категории: истина или ложь, предсказывая, будет ли сердце работать нормально или нет.
В других классификационных моделях мы можем классифицировать результаты по более чем двум категориям.
Например, прогнозирование, является ли данный рецепт рецептом индийского, китайского, японского или тайского блюда.
И с помощью классификации мы можем извлечь особенности из данных.
Особенности в этом примере сердцем, это сердечный ритм или возраст.
Особенности – это отличительные свойства шаблонов ввода, которые помогают определить категории вывода.

Здесь каждый столбец является особенностью, а каждая строка – точкой ввода данных.
Классификация – это процесс прогнозирования категории заданных точек данных.
И наш классификатор использует обучающие данные, чтобы понять, как входные переменные относятся к этой категории.
Что именно мы подразумеваем под обучением?
Обучение подразумевает использование определенного алгоритма обучения для определения и разработки параметров модели.
Хотя для этого есть много разных алгоритмов, с точки зрения непрофессионала, если вы тренируете модель, чтобы предсказать, будет ли сердце работать нормально или нет, есть истинные или ложные значения, и вы будете показывать алгоритму некоторые реальные данные, помеченные как истинные, затем снова показывая данные, помеченные как ложные, и вы будете повторять этот процесс с данными, имеющими истинные или ложные значения.
И алгоритм будет изменять свои внутренние параметры до тех пор, пока он не научится распознавать данные, которые указывают на то, что есть сердечная недостаточность или ее нет.
При машинном обучении мы обычно берем набор данных и делим его на три набора: наборы обучения, проверки и тестирования.
Набор обучения – это данные, используемые для обучения алгоритма.
Набор проверки используется для проверки наших результатов и тонкой настройки параметров алгоритмов.
Данные тестирования – это данные, которые модель никогда не видела прежде и которые используются для оценки того, насколько хороша наша модель.
Опять же, чтобы повторить, модель машинного обучения – это алгоритм, используемый для поиска закономерностей в данных без программирования в явном виде.

В то время как машинное обучение является подмножеством искусственного интеллекта, глубокое обучение является специализированным подмножеством машинного обучения.
Глубокое обучение основывается на алгоритмах машинного обучения, которые основываются на структуре и функциях мозга, и эти алгоритмы называются искусственными нейронными сетями.
Эти сети предназначены для непрерывного обучения в процессе работы для повышения качества и точности результатов.
Эти системы могут обучаться на неструктурированных данных, таких как фотографии, видео и аудиофайлы.
Алгоритмы глубокого обучения напрямую не отображают входные данные в выходные.
Вместо этого они полагаются на несколько слоев обработки.
Каждый такой слой передает свой вывод следующему слою, который обрабатывает его и передает его следующему.
Именно поэтому такая система из многочисленных слоев называется глубоким обучением.
При создании алгоритмов глубокого обучения разработчики и инженеры настраивают количество слоев и тип функций, которые соединяют выходы каждого слоя со входами следующего.
Затем они обучают модель, предоставляя множество размеченных примеров.
Например, вы даете алгоритму глубокого изучения тысячи изображений и метки, которые соответствуют содержанию каждого изображения.
Алгоритм будет запускать эти примеры через свою многоуровневую нейронную сеть и будет подгонять веса переменных в каждом слое нейронной сети, чтобы иметь возможность обнаруживать общие шаблоны, которые определяют изображения с похожими метками.
Глубокое обучение устраняет одну из основных проблем, с которой сталкивались алгоритмы обучения предыдущего поколения.
В то время как эффективность и производительность алгоритмов машинного обучения предыдущего поколения не улучшалась по мере роста наборов данных, алгоритмы глубокого обучения продолжают улучшаться по мере поступления большего количества данных.
Глубокое обучение оказалось очень эффективным при выполнении различных задач, включая распознавание и транскрипцию голоса, распознавание лиц, медицинскую визуализацию и языковой перевод.
Глубокое обучение также является одним из основных компонентов беспилотных автомобилей.

Искусственная нейронная сеть представляет собой совокупность мелких единиц, называемых нейронами, которые представляют собой вычислительные единицы, смоделированные по способу обработки информации человеческим мозгом.
Искусственные нейронные сети заимствуют некоторые идеи из биологической нейронной сети мозга, чтобы приблизить некоторые результаты его обработки.
Эти единицы или нейроны принимают поступающие данные, также как и биологические нейронные сети, и со временем учатся принимать решения.
Нейронные сети учатся через процесс, называемый обратным распространением.
Например, при преобразовании речи в текст, в нейронных сетях вместо кодирования правил вы предоставляете образцы голоса и соответствующий им текст.
И нейронная сеть находит общие шаблоны произношения слов, а затем учится сопоставлять новые голосовые записи с соответствующими им текстами.
YouTube использует это для автоматического создания субтитров.
Обратное распространение использует набор обучающих данных, которые сопоставляют известные входы с желаемыми выходами.
Сначала входы подключаются к сети и определяются выходы.
Затем функция ошибки определяет, насколько далеко данный выход находится от желаемого выхода.
И наконец, делаются изменения, чтобы уменьшить ошибки.

Набор нейронов называется слоем, и слой принимает входные данные и обеспечивает выходные данные.
Любая нейронная сеть будет иметь один входной слой и один выходной слой.
И нейронная сеть также будет иметь один или несколько скрытых слоев, которые имитируют типы деятельности, происходящих в человеческом мозге.
Скрытые слои принимают набор взвешенных входных данных и выдают результат с помощью функции активации.
Нейронная сеть, имеющая более одного скрытого слоя, называется глубокой нейронной сетью.

Перцептроны – это самые простые и старые типы нейронных сетей.
Это однослойные нейронные сети, состоящие из входных узлов, подключенных непосредственно к выходному узлу.

Входные слои передают входные значения следующему слою путем умножения на вес и суммирования результатов.
Скрытые слои получают входные данные от других узлов и направляют свои выходные данные на другие узлы.

Скрытые и выходные узлы имеют свойство, называемое смещением bias, которое представляет собой особый тип веса, который применяется к узлу после рассмотрения других входных данных.

И наконец, функция активации определяет, как узел реагирует на свои входные данные.
Функция запускается на сумме входов и смещения, а затем результат передается как выходной.
Функции активации могут принимать различные формы, и их выбор является критическим компонентом успеха нейронной сети.

Сверточные нейронные сети или CNN представляют собой многослойные нейронные сети, которые основываются на работе зрительной коры животных.
CNN полезны в таких приложениях, как обработка изображений, распознавание видео и обработка языка.
Свертка – это математическая операция, в которой функция применяется к другой функции, а результат представляет собой смесь двух функций.
Свертки хороши при обнаружении простых структур на изображении и объединении этих простых функций для создания более сложных функций.
В сверточной сети этот процесс происходит в последовательности слоев, каждый из которых проводит свертку на выходе предыдущего слоя.
CNN являются экспертами в построении сложных функций из менее сложных.

Рекуррентные нейронные сети или RNN являются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем предыдущие выходы питают входы последующих этапов.
В обычной нейронной сети вход обрабатывается через несколько слоев, а выход создается с допущением, что два последовательных входа независимы друг от друга, но это может не выполняться в определенных сценариях.
Например, когда нам нужно учитывать контекст, в котором было произнесено слово, в таких сценариях необходимо учитывать зависимость от предыдущих наблюдений, чтобы получить результат.
И RNN могут использовать информацию в длинных последовательностях, причем каждый уровень сети представляет наблюдение в определенное время.

Новый тип нейронной сети, называемый порождающей состязательной сетью (GAN), может использоваться для создания сложных выходных данных, таких как фотореалистичные изображения.
На странице сайта IBM вы можете попробовать создать изображение с помощью GAN.
В разделе «Совместное создание с нейронной сетью» в разделе «Выберите сгенерированное изображение» выберите одно из существующих изображений.
И в списке Pick object type выберите тип объекта, который вы хотите добавить.
Например, нажмите на дерево.

Переместите курсор на изображение.
Нажмите и удерживая кнопку мыши нажатой, наведите курсор на область существующего изображения, в которую вы хотите добавить объект, в данном случае дерево.
Выберите другой тип объекта и добавьте его к изображению.
Поэкспериментируйте: можете ли вы поместить дверь в небо?
И используйте функции отмены и удаления, чтобы удалить объекты.
И нажмите «Загрузить», чтобы сохранить свою работу.
Наука о данных
Наука о данных – это процесс использования данных, чтобы понять различные вещи, понять мир.
Это когда у вас есть модель или гипотеза проблемы, и вы пытаетесь проверить эту гипотезу или модель на данных.
Наука о данных – это искусство раскрытия идей и тенденций, которые скрываются за данными.
Данные реальны, данные имеют реальные свойства, и нам нужно изучить их, если мы собираемся работать с ними.
Это название появилось в 90-х годах, когда некоторые профессора вели учебную программу по статистике, и они подумали, что было бы лучше назвать это наукой о данных.
Но что такое наука о данных?
Если у вас есть данные, и вы работаете с данными, и вы манипулируете ими, вы исследуете их, сам процесс анализа данных, в попытках получить ответы на какие-то вопросы, – это наука о данных.
И наука о данных актуальна именно сегодня, потому что у нас есть огромный объем доступных данных.
Раньше стоял вопрос о нехватке данных.
Теперь у нас есть непрерывные потоки данных.
В прошлом у нас не было алгоритмов работы с данными, теперь у нас есть алгоритмы.
Раньше программное обеспечение было дорогим, теперь оно с открытым исходным кодом и бесплатное.
Раньше мы не могли хранить большие объемы данных, теперь за небольшую плату мы можем иметь доступ к большим наборам данных.
Теперь, как соотносятся между собой ИИ, машинное обучение и наука о данных.

Искусственный интеллект – это очень широкий термин для различных применений: от робототехники до анализа текста.
Это все еще развивающаяся технология, и есть вопросы о том, должны ли мы на самом деле стремиться к высокоуровневому ИИ или нет.
Машинное обучение – это подмножество искусственного интеллекта, которое фокусируется на узком диапазоне видов деятельности.
Фактически это единственный вид искусственного интеллекта, который сейчас существует с некоторыми приложениями в реальных задачах.
Наука о данных не является подмножеством машинного обучения, но использует машинное обучение для анализа данных и прогнозирования будущего.
Наука о данных сочетает в себе машинное обучение с другими дисциплинами, такими как анализ больших данных и облачные вычисления.
Наука о данных – это практическое применение машинного обучения с фокусом на решении реальных задач.
Наука о данных в основном сосредоточена на работе с неструктурированными данными.

Структурированные данные больше похожи на табличные данные, с которыми мы имеем дело в Microsoft Excel, где у вас есть строки и столбцы, и это называется структурированными данными.
Неструктурированные данные – это данные, поступающие в основном из Интернета, где они не являются табличными, они не в виде строк и столбцов, а в виде текста, иногда это видео и аудио, поэтому вам придется использовать более сложные алгоритмы для обработки этих данных.
Традиционно при вычислении и обработке данных мы переносим данные на компьютер.
Но если данных очень много, они просто могут не поместиться на одном компьютере.
Поэтому Google придумал очень просто: они взяли данные и разбили их на куски, и они отправили эти куски файлов на тысячи компьютеров, сначала это были сотни, а потом тысячи, и теперь десятки тысяч компьютеров.

И они поставили одну и ту же программу на все эти компьютеры в кластере.
И каждый компьютер запускает эту программу на своем маленьком фрагменте файла и отправляет результаты обратно.
Затем результаты сортируются и объединяются.
Первый процесс называется процессом Map, а второй – процессом Reduce.
Это довольно простые концепции, но оказалось, что вы можете делать с их помощью много разных видов обработки, выполнять много разных задач и обрабатывать очень большие наборы данных.
И такая архитектура называется Hadoop.
И когда у нас появились вычислительные возможности для обработки данных, у нас появились новые методы, такие как машинное обучение.
С помощью которого мы можем взять большие наборы данных, и вместо того, чтобы брать выборку из этих данных и пытаться проверить какую-то гипотезу, мы можем взять большие наборы данных и искать в них шаблоны – закономерности.

То есть перейти от проверки гипотез к поиску шаблонов, которые, возможно, будут генерировать гипотезы.
Это отличается от традиционной статистики, где у вас должна быть гипотеза, которая не зависит от данных, и затем вы проверяете ее на данных.
В машинном обучении сами данные генерируют гипотезы.
С появлением больших данных и вычислительных возможностей стало актуальным глубокое машинное обучение и использование нейронных сетей.
Jupyter Notebook
Технология нейронных сетей существовала 30 лет назад, но ее развитие сдерживалось нехваткой данных и вычислительных возможностей.
Нейронные сети – это попытка подражать нейронам мозга и тому, как на самом деле функционирует наш мозг.
Нейронная сеть получает некоторые входные данные, которые затем передаются в разные узлы обработки, которые выполняют некоторые преобразования в данных, а затем передают результаты на другой уровень узлов и, наконец, сеть выдает конечный результат.
Таким образом, нейронная сеть представляет собой компьютерную программу, которая имитирует, как наш мозг использует нейроны.
Нейронная сеть содержит входы и выходы, и вы продолжаете вводить данные в эти входы, и смотрите на выходы, и вы продолжаете делать это снова и снова, таким образом, чтобы эта сеть давала нужные результаты, при этом регулируя преобразования внутри сети.
Так вы обучаете нейронную сеть.
И теперь у нас есть нейронные сети и глубокое обучение, которые могут распознавать речь и распознавать людей.
И глубокое обучение требует больших вычислительных мощностей, так что это не то, что вы можете делать на своем ноутбуке, вы можете поиграть с нейронной сетью, но, если вы действительно хотите сделать что-то серьезное, у вас должен быть доступ к специальным вычислительным ресурсам.

Теперь, для обучения работе с данными существуют бесплатные инструменты, например, Skills Network Labs от компании IBM.
Это бесплатная виртуальная лабораторная среда, которая позволяет практиковаться и изучать науку о данных.
Skills Network Labs содержит такие инструменты, как RStudio, Jupyter и Zeppelin.
И эти инструменты предоставляют интерактивную среду для анализа данных, визуализации данных, машинного обучения и распознавания изображений.
Например, кнопка JupyterLab откроет собой интерактивную среду, которая позволяет запускать или создавать записные книжки notebook, которые запускают коды на Python с помощью Jupyter Notebooks, Scala на Apache Toree и R.

Jupyter Notebook – это веб-приложение, в котором вы можете создавать и обмениваться документами, содержащими живой код, уравнения, визуализации, а также текст.
И Jupyter Notebook является одним из инструментов, помогающих приобрести необходимые навыки в области науки о данных.
Что такое Jupyter Notebook?

В данном случае «записная книжка» notebook означает документ, который содержат как код, так и элементы форматированного текста, такие как рисунки, ссылки, уравнения и так далее.
И из-за такого сочетания кода и текста, эти документы являются идеальным местом собрать воедино описание анализа данных и его результаты, а также возможность выполнить анализ данных в режиме реального времени.
И приложение Jupyter Notebook создает такие документы.
«Jupyter» является аббревиатурой, означающей Julia, Python и R.
Эти языки программирования были первыми языками, которые поддерживал Jupyter, но в настоящее время технология Jupyter также поддерживает другие языки, на которых можно писать код в Jupyter.
Таким образом, документы notebook – это документы, созданные приложением Jupyter Notebook, которые содержат как компьютерный код (например, python), так и элементы форматированного текста (абзацы, уравнения, рисунки, ссылки и т. д.).
Документы notebook – это читаемые документы, содержащие описание анализа и результаты анализа данных (рисунки, таблицы и т. д.), а также исполняемый код, который можно запустить для анализа данных.
Что такое приложение Jupyter Notebook?
Это клиент-серверное приложение, которое позволяет редактировать и запускать записные книжки notebook через веб-браузер.
Приложение Jupyter Notebook может быть запущено на компьютере без доступа к Интернету или установлено на удаленном сервере, где вы можете получить к нему доступ через Интернет.

Помимо отображения, редактирования и запуска записных книжек, в приложении Jupyter Notebook есть «Панель инструментов» (Notebook Dashboard), отображающая локальные файлы и позволяющая открывать записные книжки и останавливать их ядра.
Ядро – это программа, которая запускает код, написанный в записной книжке.
Приложение Jupyter Notebook имеет ядро ipython для кода Python, но также есть ядра, доступные для других языков программирования.
Когда вы открываете документ Notebook, соответствующее ядро запускается автоматически.
И ядро выполняет вычисления и выдает результаты.
Теперь, как появился Jupyter Notebook.
В 2001 году, программист Фернандо Перес начинает разработку IPython – интерактивную оболочку для языка программирования Python.

И в 2005 году и Роберт Керн, и Фернандо Перес попытались создать систему для ноутбуков.