
Контент: топовые техники SEO-продвижения
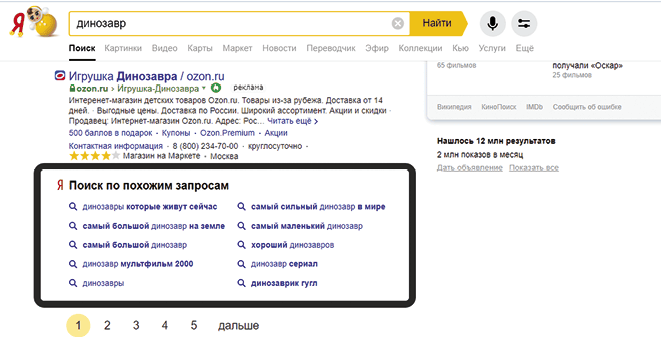
Окна «Поиск по похожим запросам» также сигнализируют об информационных намерениях.
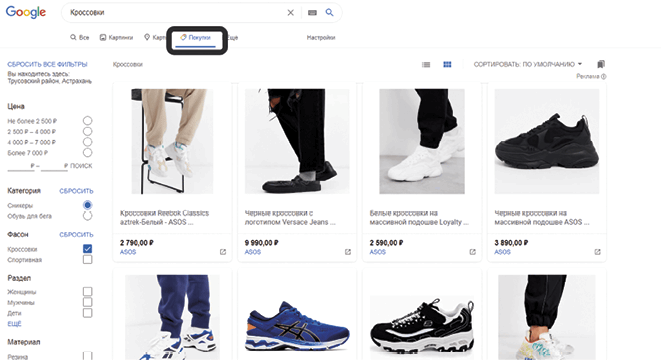
Результаты покупок Google сигнализируют об «активных» поисковых запросах.
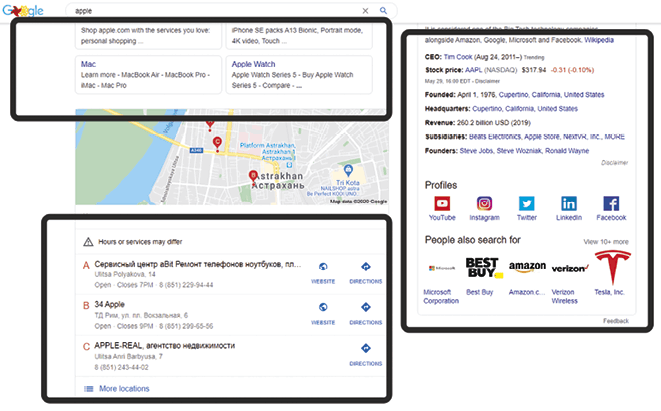
Локальные результаты Google и граф знаний имеют тенденцию сигнализировать о навигационных запросах.
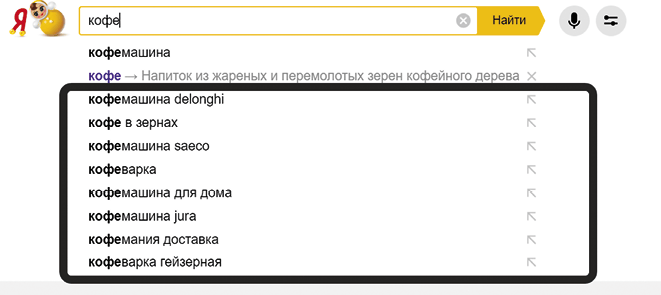
Поисковые подсказки позволяют лучше понять возможный интент:
Вы можете использовать Serpstat, чтобы увидеть, какие типы «универсальных» результатов поиска отображаются по любым заданным триггерам запроса:
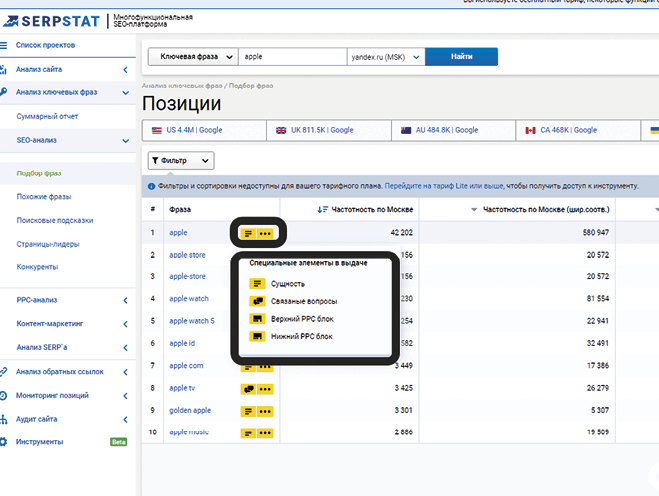
Вы также можете использовать фильтры Serpstat, чтобы ограничить поиск запросами, инициирующими определенный тип поиска (и, следовательно, конкретное намерение):
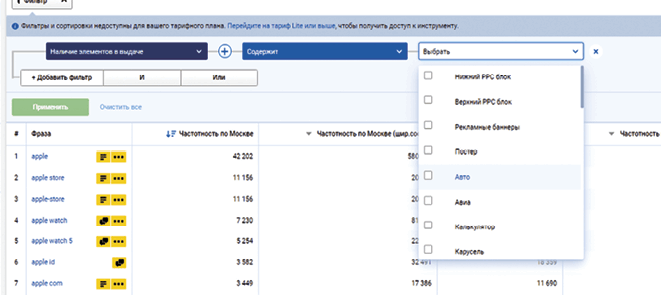
Это очень полезный трюк, когда вы работаете над определенной маркетинговой стратегией. Например, при создании редакционного календаря вы можете использовать Serpstat для исследования ключевых слов, вызывающих результаты «поиска по похожим запросам», раскрывая очевидные информационные намерения.
Психология интента
Будучи неотъемлемой частью исследования ключевых слов, намерение (интент) помогает вам создать более организованную контентную стратегию, нацеленную на довольных клиентов, пользователей, а значит, и на более высокий показатель конверсии. Первый шаг – организовать ключевые фразы по интенту.
Ключевые слова с информационным умыслом – это простые идеи контента, которые можно отправить вашей команде разработчиков контента.
Ключевые слова с транзакционными намерениями, которые могут включать идеи контента (списки продуктов, сравнение продуктов, часто задаваемые вопросы о продуктах, руководства по продуктам и т. д.), которые плавно ведут читателя по каналу конверсии.
Ключевые слова с коммерческими намерениями. Если у вас есть продукт, который вам подходит, обратитесь к своей SEO-команде для выяснения, как лучше оптимизировать страницы продукта, чтобы они могли ранжироваться по этим запросам. В качестве альтернативы это могут быть списки товаров или другие типы целевых страниц «купить сейчас», которые могут точно соответствовать запросу с высоким уровнем намерения.
Ключевые слова с навигационным интентом: некоторые из этих запросов будут иметь намерение «купить сейчас», в то время как другие могут сигнализировать о транзакционном намерении (например, потенциальные клиенты, изучающие отзывы о вашем продукте). Некоторые из них следует отправить вашей команде по управлению репутацией, а некоторые помогут вашим менеджерам по продажам лучше соответствовать ожиданиям клиентов. Большинство из этих запросов будут полезны более чем для одной команды специалистов и потребуют разных точек воздействия.
Конечно же, в дальнейшем мы поговорим о работе с каждым типом запросов более подробно. Сейчас вам необходимо выяснить, с какими типами поисковых запросов вы будете взаимодействовать и как понять психологию интента. В последующих главах мы расскажем, как собрать список ключевых запросов, разбить их по необходимым кластерам, разработать на основе этих данных контент-стратегию и оптимизировать посадочные страницы под поисковые системы. Вся эта деятельность проходит через призму понимания интента. В конце концов успешный бизнесмен – это тот, кто знает, чего хотят его клиенты.
Важно понимать и то, чего пытаются избежать ваши клиенты во время совершения сделки. Это справедливо и для информационных проектов. Например, возможно, читатели вашего блога желают получать самые свежие новости в сжатом виде без лишней информации. Бывают обратные случаи, когда читатели хотят иметь более углубленную информацию по какому-либо вопросу и не любят натыкаться на малоинформативные заметки.
Работа с ключевыми словами требует большого количества времени, но она определяет вашу будущую маркетинговую стратегию на многих уровнях, так что не торопитесь! Учет намерений пользователей при планировании и оптимизации контента делает вашу контент-стратегию намного более организованной и ориентированной на конверсию, что принесет вам больше прибыли.
Почему текстовой контент так важен для поисковых систем?
Мне бы не очень хотелось углубляться в историю развития поисковых систем, поскольку это может сильно поубавить ваш интерес и энтузиазм уже в самом начале. Поэтому в данной книге я позволю себе опустить большую часть исторических деталей, мы сфокусируемся только на самом важном. Те, кому интересно познакомиться с историей развития поисковых систем, могут узнать об этом из других моих книг, а также в блоге 8merka.ru.
Итак, что следует знать: поисковые системы были бы рады индексировать и понимать любые формы контента на сайте – тексты, изображения, аудио- и видеофайлы и даже хотели бы научиться понимать особенности дизайна сайта. Но на деле научить искусственный интеллект подобным навыкам крайне трудно, и сегодня поисковым системам удалось значительно продвинуться только по части текста. Фокусировка на текстовой составляющей обоснована тем, что до эпохи YouTube и Instagram текст был самой основной частью контента в Интернете.
Поисковые роботы постепенно учатся понимать содержание изображения, они значительно продвинулись в понимании flash-сайтов (хотя по-прежнему делают это весьма плохо), но самый значительный скачок произошел в отношении контекстуальной части текстов. Мне нравится говорить об этом, поскольку это позволяет заниматься контент-маркетингом на более высоком уровне, а также является мощным инструментом продвижения. Создавать сайты – это всегда очень интересно, но создавать интересные сайты – огромное удовольствие!
Представители поисковых систем также хорошо понимают потребность пользователей в более качественном контенте. Как мы уже говорили ранее, качественный контент должен соответствовать интенту. Такие материалы должны удовлетворять пользователя тем, что отвечают на его вопрос. Сегодня мы живем в крайне любопытное время, когда сотни тысяч людей пишут страницы полезных для жизни данных, и при этом миллиарды людей имеют свободный доступ к ним. Однако есть и другая сторона – спамный и малоэффективный контент – материалы, которые не имеют никакой практической ценности и не способны приносить пользу людям. Более того, подобные материалы наносят определенный урон, так как отнимают свободное время пользователя, который каким-либо образом наткнулся на материал и пытается вычленить из него полезную информацию. Урон есть и для поисковых систем. Индексируя подобные материалы, поисковые машины попусту растрачивают ресурсы на своих серверах.
Всё это исторически привело к борьбе со спамом и попыткам научиться лучше понимать тексты, чтобы выбирать лучшие из лучших и затем предлагать их пользователям в топе-10 поисковой выдачи. И здесь было бы неплохо углубиться в несколько исторических моментов возникновения важных поисковых алгоритмов.
«Колибри» и «Королёв»
26 сентября 2013 года Google сообщил о запуске алгоритма Hummingbird (в пер. с англ. – колибри). По свидетельству Google, последние столь серьезные перемены в Google происходили в 2001 году. Суть алгоритма заключается в том, что с 2013 года поисковая система Google умеет определять контекст страницы. Скажем, если вы использовали ключевую фразу «кубик Рубика» на странице по продаже апельсинов, Google поймет это и понизит вас в выдаче или выкинет из нее вовсе.
22 августа 2017 года схожий алгоритм анонсировали представители Яндекса. Они назвали данный алгоритм «Королёв». Поиск Яндекса научился определять содержание текста не по набору слов, а по смыслу. Столь значительный прорыв в обеих поисковых системах произошел благодаря развитию нейронных сетей и искусственного интеллекта.
Для того чтобы было проще воспринять эту информацию, я предлагаю вам зайти прямо сейчас в поиск Яндекса и вбить запрос «фильм, в котором у странного парня была шоколадная фабрика». Вы получите ответ «Чарли и шоколадная фабрика». Меня восхищает подобное развитие технологий. Поиск научился работать с longtail запросами. Longtail запросы – это запросы с длинным «хвостом» из дополнительных уточняющих слов. В нашем случае это было: «у странного парня была шоколадная фабрика».
Вернемся ненадолго к примеру с кубиком Рубика на странице по продаже апельсинов. Как в данном случае алгоритмы будут понимать, что речь идет о совершенно разных вещах? Быть может, мы продаем кубик Рубика апельсинового цвета? Поисковые алгоритмы способны понять, что кубик имеет кубическую форму, и это совершенно не связано с шарообразной формой апельсина. Кубик Рубика не может быть одного цвета, так как в данном случае теряется вся логическая необходимость данного предмета. Такой вариант может продаваться только в магазине приколов, и поисковая система способна понять этот момент. А вот апельсины редко бывают фиолетовыми или белыми. Кубик Рубика не имеет вкусовых параметров. Апельсины кислые или сладкие, а еще они – цитрусовые. Таким образом, мы ненадолго погрузились в мозг поисковой системы, которая обзавелась нейронными связями.
В действительности обе поисковые системы шли к этому очень долго и сегодня они по-прежнему развивают технологии, которые позволяют распознавать неочевидный смысл содержания страницы и интента запроса. Благодаря этому авторам и веб-мастерам была дана возможность оптимизировать свои сайты, используя естественные тексты, а не набор ключевых фраз. С помощью развивающихся талантов авторов или в связи с выходом данных алгоритмов, но тексты в Интернете действительно стали значительно лучше, и мы наконец обрели высокую ценность текстовых материалов в Сети.
Я хотел бы остановиться чуть более подробно на истории внедрения поисковых алгоритмов, так как знание этого в разы повышает профессионализм в сфере контент-маркетинга. Знать историю развития поисковых систем в действительности важно, чтобы понимать, что хотят увидеть представители поисковиков, когда говорят о качественном контенте.
В 2016 году Яндекс анонсировал новый алгоритм и большую статью с развернутым объяснением того, как они стремятся научить поисковую систему определять сложные контекстуальные запросы с длинными хвостами ключевых слов. Алгоритм был назван «Палех» в честь сказочного существа – жар-птицы, которая имела длинный хвост и часто изображалась на предметах в стиле «палех». Алгоритм «Королёв», который появился через год после «Палеха», можно считать его усовершенствованным вариантом.
Предлагаю уделить внимание технологиям нейронных сетей в рамках поисковых алгоритмов. Например, сегодня поисковые системы уже умеют понимать содержание графического изображения. Спасибо нейронным сетям!
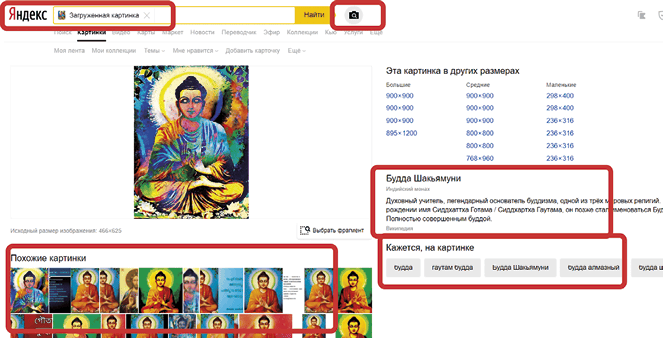
И несмотря на то что они пока научились делать это в узкоспециализированных направлениях, тем не менее это значительный прорыв в технологиях поиска, и на основе этого можно предположить, что данная технология будет внедряться все больше и больше. Например, поисковые системы с легкостью определяют изображения порнографического характера. Они делают это благодаря определению количества телесного цвета на изображении. Таким образом работает цензура поисковой системы, отсеивая неэтичные изображения из прямых источников.
Как стоит интерпретировать информацию о работе данных алгоритмов в практическом смысле? В первую очередь мы получаем ценное понимание того, что поисковые системы стали значительно умнее – они научились понимать контекст страницы. Но я бы сильно поспорил с высказыванием представителей Яндекса о том, что веб-мастерам необходимо просто писать тексты для людей. Некорректность данного высказывания заключается в том, что для того, чтобы написать хорошие тексты для людей, необходимо как минимум изучить их психологию, понять портрет целевого пользователя, узнать всё о его «боли» и проблемах.
Что такому пользователю важно? Как он ищет информацию? Для чего он это делает? Каким образом он пытается сделать свою жизнь лучше, разыскивая ту или иную информацию? В действительности возникает множество важных вопросов, и «просто писать тексты для людей» не получится «просто» – это весьма неординарная задача.
В свете данных алгоритмов мы должны определить полный список ключевых фраз, которые встречаются в данной тематике. Сюда будут относиться вся перекрестная семантика, синонимы, околотематические фразы. В дальнейшем мы поговорим о том, как именно собрать подобную информацию. Я также расскажу о способах составления портрета целевого пользователя.
«Панда» и «Баден-Баден»
Для того чтобы объективно понимать ценность тех или иных техник работы с контентом, мы должны рассмотреть еще два важных алгоритма поисковых систем – это «Панда» у Google и «Баден-Баден» у Яндекс.
Алгоритм Google «Панда» был анонсирован в феврале 2011 года. Данный алгоритм был нацелен на чистку Интернета от низкокачественных сайтов, то есть сайтов, содержащих некачественный контент. Запуск алгоритма прошел не очень гладко, так как в первые же несколько итераций были пессимизированы множественные новостные сайты, популярные форумы, которые активно применяли стороннюю рекламу. Мэтт Каттс – бывший инженер Google, который руководил отделом веб-спама, а в 2017 году покинул Google, раскрыл большие объемы инсайдерской информации. Так, он прокомментировал, что Google в действительности пытался добиться увеличения прибыли от некоторых своих партнеров. В связи с не самым успешным запуском алгоритма в апреле 2011 года Google выпустил новую версию алгоритма, чтобы минимизировать ущерб, который получили множественные проекты в ходе первой итерации.
Алгоритм был назван не в честь редкого китайского животного (для тех, кто не знает: все панды в мире принадлежат КНР), а по фамилии инженера, который его изобрел, – Навнит Панда. Несколько позднее мы вернемся к данному алгоритму, так как требования по работе с контентом в рамках Google Panda совпадают с требованиями алгоритма Яндекса «Баден-Баден», который был анонсирован в марте 2017 года. Традиционно Яндекс называет поисковые алгоритмы в честь тех или иных городов. Можно заметить иронию: «Минусинск» – потому что «минусует», а «Баден-Баден» – потому что много «воды».
Алгоритм «Баден-Баден»
«Баден-Баден» Яндекса – алгоритм поискового ранжирования, направленный на пессимизацию сайтов с некачественными переоптимизированными текстами и созданный в целях «очищения» поисковой выдачи. Чистка напрямую связана с политикой Яндекса отдавать наиболее релевантные и полезные материалы в результатах выдачи.
На самом деле Яндекс не придумал ничего нового, алгоритм работает давно. Исходя из официальных материалов Яндекса, можно сказать, что алгоритм работает с 2011 года, просто сформировалось более четкое представление о том, как должен выглядеть текст для людей, ужесточились требования. Нет нужды паниковать, но уже давно пора обратить внимание на качество текстов на сайтах. Если вы до сих пор этого не сделали – самое время начать.
Вот так выглядит сообщение в панели Яндекс. Вебмастера при наложении фильтра:

Чем грозит «Баден-Баден»?
При наличии переоптимизированных текстов и наложении фильтра «Баден-Баден» все страницы сайта проваливаются в выдаче. Вот как выглядит падение позиций при наложении фильтра «Баден-Баден»:

На изображении указан февраль 2016 года, далее 28 апреля 2017 года. Я не работал по проекту с февраля 2016 года, поэтому у меня не было статистики за промежуточный период, но я знаю, что сайт стабильно занимал топ-10 по основным запросам:
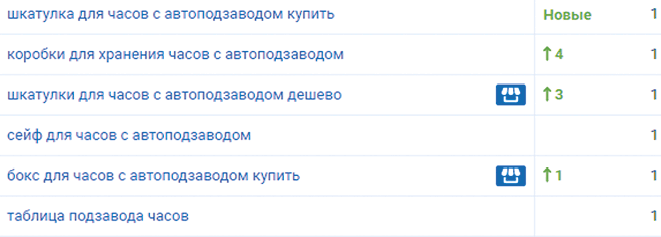
Вот что происходит с трафиком в Яндексе:
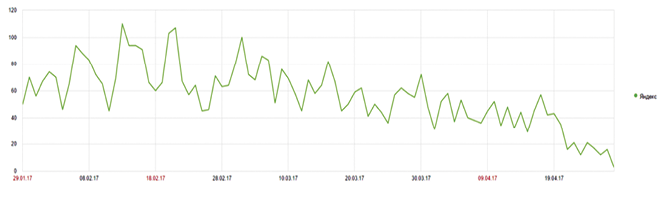
Ущерб просто колоссальный. Поэтому задумайтесь заранее о качестве контента на своих сайтах!
Что важно понимать для избегания «Баден-Бадена»?
Главное и единственное, что нужно понимать, – это определение переоптимизации. Я работаю по принципу «не навреди» и поэтому на первых этапах работы с сайтом скорее могу недооптимизировать сайт, нежели переоптимизировать. Досолить проще, чем пытаться после сделать суп не таким соленым.
Вот пример переоптимизированного текста от Яндекса:

Еще один пример переоптимизированного текста:

Вот так выглядит текст реального сайта, который недавно попал под фильтр «Баден-Баден»:

И еще небольшой пример:

Что делать, чтобы не повторять чужих ошибок? Не требуйте от своих копирайтеров 35 упоминаний ключевой фразы. Навсегда откажитесь от максимализма во взглядах на SEO. Много – не значит хорошо. Обратите свое внимание на методику LSI-текстов. Используйте синонимы, тезаурус, связывайте другие фразы с ключевой – все это влияет на релевантность текстов. На первых порах следите за «тошнотой» текста, количеством «воды» и плотностью вхождения ключевой фразы. С опытом у вас должно сформироваться естественное и правильное понимание удобочитаемости текстов.
Плюсы алгоритма
Я большой сторонник контент-маркетинга. Зачастую для меня действует правило: если публикация написана менее чем на одну тысячу слов, то тема не раскрыта по-настоящему. Дело не в количестве, а в том, что это количество показало себя очень неплохо в тематике блогов о поисковом продвижении. Большая часть вопросов требует действительно серьезного рассмотрения.
Я люблю рассматривать вопрос с разных точек зрения, люблю демонстрировать примеры из личной практики, и я никогда не заглядываю в блоги коллег, чтобы изучить, как они раскрыли вопрос, до тех пор, пока не напишу свою публикацию на эту тему.
Конечно, я собираю много предварительной информации. Использую важные источники, но всеми силами стараюсь избегать рерайтинга. Моя цель – давать что-то новое и полезное, то, чего мои клиенты еще не видели в блогах других SEO-специалистов. Мне кажется, так должен поступать каждый. И «Баден-Баден» помогает таким, как я, освобождая место в выдаче. К слову говоря, заметил хороший рост на своих сайтах после начала работы «Баден-Бадена».
«Баден-Баден» может привести индустрию к созданию более качественных текстов. От этого хорошо всем: копирайтерам, потому что наконец увеличится чек и задачи станут более творческими и интересными, отсеется конкуренция в виде неопытных авторов; для веб-мастеров – тем, что их сайты действительно станут лучше, вырастет поведенческий показатель; для пользователей – тем, что им наконец не придется натыкаться на нечитабельные тексты.
Пользователь будет обращать больше внимания на тексты, после того как доверие пользователей к текстам будет возвращено. От этого значительно улучшатся поведенческие факторы.
Как вывести сайт из-под «Баден-Бадена»?
Для выведения сайта из-под фильтра «Баден-Баден», рекомендую полностью удалить тексты с сайта. Далее два варианта.
1. Сразу отправить сайт без текстов на переиндексацию по фильтру.
2. Написать новые, по-настоящему качественные тексты и отправить сайт на переиндексацию по фильтру.
Хорошая новость заключается также и в том, что, так как вы уже изучаете вопрос качественного контента, то вам будет достаточно применить изложенные здесь техники. Это значительно повысит качество материалов на вашем проекте и поможет быстро выйти из-под фильтра.
Знание поисковых алгоритмов позволяет понимать, чего от нас ждут поисковые системы. В целом политика поисковых систем вполне логична и имеет весомые основания для того, чтобы соблюдать ее. Несмотря на очевидность того, что дублированный низкокачественный контент, у которого нет ни уникальности, ни особой ценности для читателей, никогда не сможет генерировать высокие рейтинги и постоянный поток трафика, тем не менее многие люди продолжают надеяться на то, что подобная простая «работа» позволит им выйти в топ.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Вы ознакомились с фрагментом книги.
Для бесплатного чтения открыта только часть текста.
Приобретайте полный текст книги у нашего партнера:
Всего 10 форматов