
Объектно-ориентированное программирование на Java. Платформа Java SE
Другими словами, полиморфизм позволяет использовать наследников, как родителей. При этом, если в классе-наследнике был переопределен какой-то метод, то вызовется он.
Переопределение и перегрузка

Теперь давайте рассмотрим две концепции, которые выглядят взаимосвязанными, но на самом деле являются разными, это перегрузка и переопределение.
Обе эти концепции применяются к методам.
Ранее мы говорили о конструкторах.
Помните, что у нас был автомобиль с двумя полями, lights и color.

И мы определили в одном классе не один, а несколько конструкторов.
Имена этих конструкторов были одинаковыми, но параметры были разные.
И это важно, чтобы список параметров был другим.
Вы не можете определить два конструктора с одним и тем же именем, и одним и тем же списком параметров.
Фактически, Java понимает, какой конструктор вызвать, просматривая параметры.
И то, что мы делали для конструкторов, также применимо для методов.
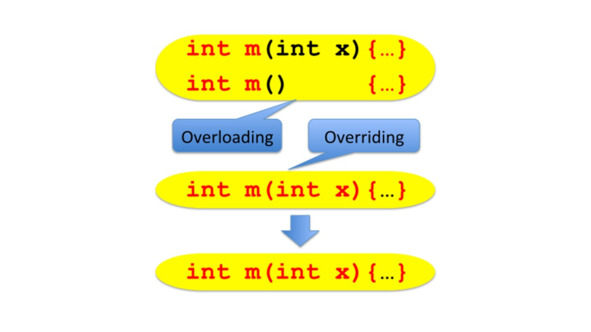
Мы говорим о перегрузке, когда у нас есть разные методы с тем же именем, но разным списком параметров.
С другой стороны, мы ввели переопределение, когда мы хотели изменить поведение метода, унаследованного от суперкласса.
В этом примере метод toString суперкласса переопределяется в подклассе с помощью метода с тем же именем, и теми же параметрами, и возвращаемым типом, но другим телом метода.

Важно, чтобы параметры и возвращаемый тип были одинаковыми.
Отличалось только тело метода.
И в пределах одного класса мы можем перегрузить метод.
В этом случае имя и возвращаемый тип совпадают, но список параметров будет другим.
Компилятор будет различать, какой вызывается метод, сравнивая списки параметров.
Неправильно пытаться перегрузить метод, просто изменив возвращаемый тип.
Если мы это сделаем, мы получим ошибку компилятора.
То же самое произойдет, если мы просто изменим имена параметров.
В этом случае определенный метод не изменится вообще.
И мы также получим ошибку компилятора.
Когда мы определяем метод, мы связываем идентификатор – имя метода – с некоторым кодом – телом метода.

Всякий раз, когда мы вызываем это имя метода с некоторыми значениями, мы знаем, какой код нужно выполнить.
Например, используя объявление метода, мы связываем идентификатор sq с методом, который отображает целые числа в целые числа, возводя число в квадрат.
Идентификатор sq всегда привязан к методу в соответствующей области кода.
Во многих языках, которые не являются объектно-ориентированными, эта привязка выполняется обычно во время компиляции.
Во время выполнения эта привязка зафиксирована.
И это называется «ранним» или «статическим» связыванием.
Но этот способ не соответствует концепции полиморфизма и переопределения методов в производных классах.
Здесь мы хотим точно противоположного – чтобы часть кода была не привязана статически к имени метода, а, чтобы зависела от объекта, вызванного во время выполнения.
Поведение, которое нам нужно, называется «динамическим» связыванием.
Поэтому нам нужно различать статическое или раннее связывание, которое выполняется во время компиляции, от динамического или позднего связывания, которое выполняется во время выполнения кода.
В отличие от переопределения перегруженные методы разрешаются во время компиляции.
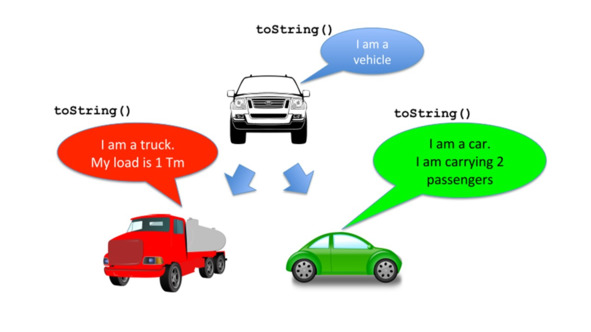
При этом информация предоставляется классом.
Когда код программы доходит до имени метода, компилятор знает, какое тело метода выполнить – по крайней мере в случае перегруженных методов.
Но это не относится к переопределению.
Здесь разрешение имен выполняется во время выполнения программы.
Динамическое связывание используется для переопределенных методов.
Здесь информация задается объектом, а не классом.
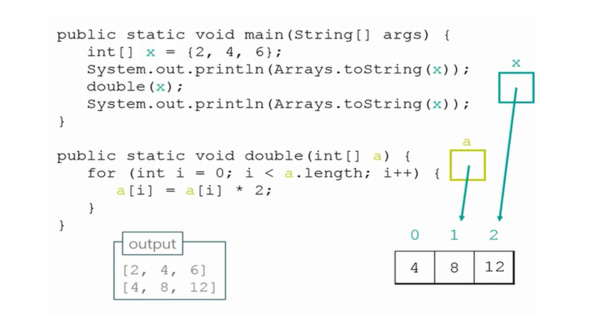
Предположим, мы объявили массив транспортных средств под названием «гараж» для хранения четырех автомобилей.
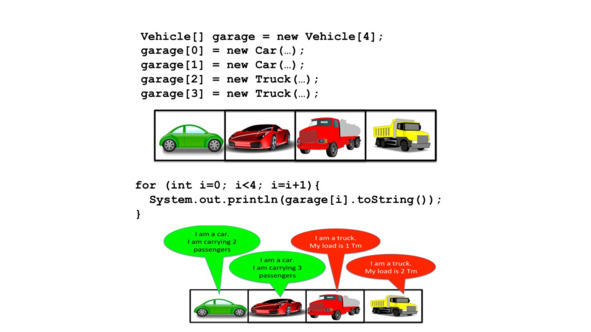
И предположим также, что у нас есть автомобили и грузовики, которые стоят в разных позициях.
Теперь в цикле for мы применяем методы toString,
Которые мы определили ранее, ко всем элементам массива.
Что происходит?
Свой метод применяется к каждому из этих элементов.
Таким образом, мы можем иметь единую форму объектов, но разнообразие в том, что выполняется.
Возможно даже, в случае компиляции мы не знаем классов элементов массива.
Это будет считываться во время выполнения программы.
Поэтому динамическое связывание является необходимым поведением для переопределения метода.
Теперь посмотрим на другой пример.
Давайте теперь определим несколько перегруженных методов с именем p.

У них есть один параметр, который является объектом разных классов.
И теперь мы вызываем метод p для всех элементов этого массива.
Помните, что аргумент метода p – это vehicle в массиве vehicle.
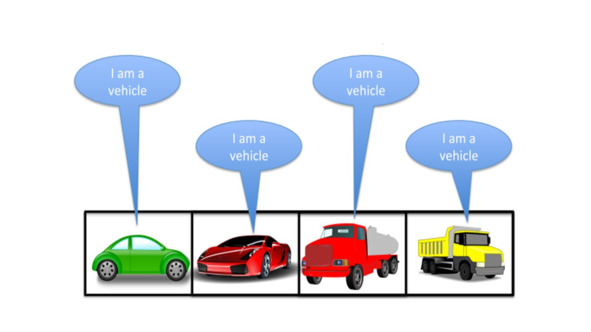
Поскольку каждый элемент является vehicle, строка будет напечатана для vehicle, так как метод p привязывается к телу во время компиляции.
Помимо примера, который мы видели, private, final, и static методы также привязываются статически.
Кроме того, атрибуты всегда привязываются статически.
Возникает вопрос, почему все не привязывать динамически?
Имеет смысл связывать идентификаторы с данными или кодом во время компиляции по двум причинам.
Во-первых, чтобы выполнить первую проверку кода и выявить ошибки, а во-вторых, оптимизировать генерируемый код.
Вот почему эта стратегия используется чаще в языках программирования.
Однако это не работает, когда мы переопределяем метод.
Во время компиляции мы можем даже не знать, какой объект мы получим.
Тогда имеет смысл применить динамическое связывание.
Динамическое связывание также называется «поздним связыванием».
Первое приближение к классу выполняется во время компиляции, но нужный класс окончательно определяется во время выполнения.
Теперь вернемся к исключениям, чтобы объяснить некоторые дополнительные исключения, которые вы должны знать и которые связаны с объектами и классами.
Небольшое напоминание, исключения – это события, которые происходят во время выполнения программы и которые нарушают нормальный поток выполнения инструкций программы.
Мы уже видели три исключения: ArithmeticException, ArrayIndexOutOfBoundsException и NumberFormatException.
Следующее исключение, которое мы увидим, – это исключение NullPointerException.
Это исключение возникает при попытке программы использовать переменную, которая не имеет примитивного типа, и которая еще не была инициализирована.
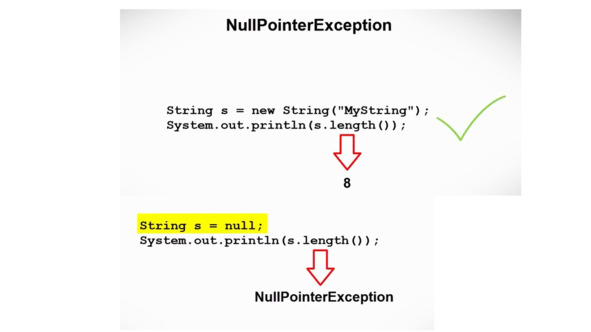
Т. е. мы пытаемся использовать переменную, которая должна указывать на объект, который еще не был создан.
Представьте, что мы хотим напечатать длину массива, который мы объявили, но который мы еще не инициализировали.

Тогда мы получим такое же исключение NullPointerException.
Имейте в виду, что «length» – это метод в случае класса String, но поле в случае массива.
И, если мы попытаемся получить доступ к позиции в массиве, который не был инициализирован, программа будет генерировать исключение NullPointerException, а не исключение ArrayIndexOutOfBoundsException.
В этих примерах очень легко обнаружить, что мы пытаемся использовать переменную, которая не была инициализирована.

Однако, когда мы программируем, мы определяем методы, которые получают аргументы и которые вызываются из других объектов.
В этих случаях обнаружение переменных, которые не были инициализированы, не так очевидно.

Второе исключение, которое связано с объектами и классами, и которое мы увидим, это ClassCastException.
Чтобы проиллюстрировать это исключение, рассмотрим эту иерархию классов, где Vehicle является суперклассом, и Car и Bike – это подклассы.
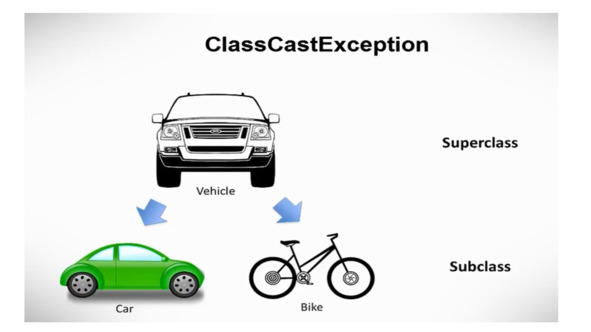
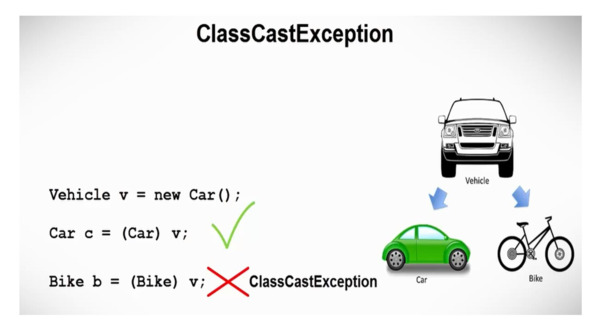
Согласно этой иерархии, можно создать экземпляр класса Car и присвоить его переменной типа Vehicle, потому что Car также является Vehicle.
Это приведение правильное и позволяет нам воспользоваться свойством полиморфизма, сохраняя в одном массиве Vehicle набор объектов классов Car и Bike.

Позже в программе нам может понадобиться привести этот экземпляр к объекту класса Car.
Единственное условие, которое налагает Java, – это сделать это приведение явным.
Однако, если мы попытаемся применить этот экземпляр к объекту класса Bike, программа выбросит ClassCastException во время выполнения, потому что объект в переменной «v» не является байком.
Мы уже видели, как обрабатывать исключения, которые выбрасываются, когда в программах происходят определенные события, используя конструкцию «try-catch».
Однако мы также можем программировать методы, которые при определенных обстоятельствах должны выбрасывать исключения.
Чтобы явно выбросить исключение в методе, нам нужно использовать ключевое слово «throw» и создать экземпляр конкретного исключения, которое метод должен выбросить.
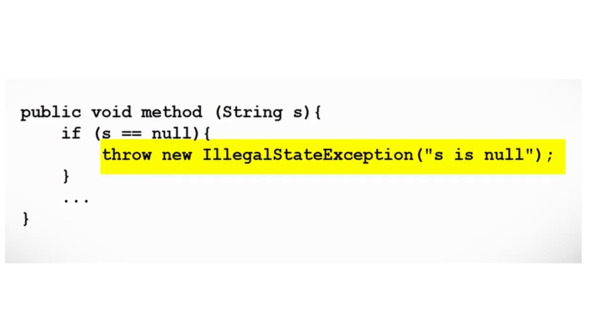
Один и тот же метод может выбросить несколько исключений в зависимости от конкретных обстоятельств.
Примитивы и объекты

Теперь в качестве обобщения.
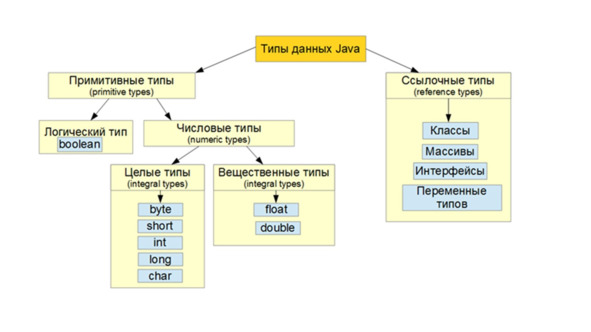
В Java есть два общих типа данных: примитивы и объекты.
Примитив – это тип данных Java, которые считаются простейшей формой данных.
Данные этого типа хранятся непосредственно в памяти.
Это данные типа int, char, double и boolean.
И когда вы создаете новую переменную типа int, которая является примитивом, компьютер выделяет область в памяти с именем и значением этого int прямо там.
Поэтому всякий раз, когда вы передаете переменную в качестве параметра или копируете ее, вы копируете значение этой переменной.
Поэтому вы создаете совершенно новую версию этой переменной каждый раз, когда вы манипулируете ей.
Так как примитивы такие простые, мы можем выполнять с ними прямые математические операции, такие как сложение, вычитание, деление, и так далее.
Теперь, что такое объект?
Объектом является гораздо более сложный тип данных, потому что на самом деле это способ хранения нескольких фрагментов связанной информации и различных вещей, которые вы можете делать с этой информацией под одним типом данных.
Такие вещи, как String, Array, Scanner и ArrayList считаются объектами.
И все они начинаются с большой буквы в Java, чтобы обозначить их как объекты.
Когда вы создаете новую переменную типа объект, например, для массива, компьютер выделяет область памяти для ссылки на то, где этот код на самом деле собирается хранить эти данные.
Затем, когда вы передаете это значение в качестве параметра, вы передаете ссылку, а не фактические данные.
И это потому, что объекты намного больше примитивов, и постоянно копировать их очень затратно.
Поэтому вам всегда нужно понимать, когда вы копируете ссылку на объект или сами данные объекта.
Поскольку объекты сложнее примитивов, вы не можете выполнять такие вещи, как сложение и вычитание, как с простыми числами.
Но, поскольку объекты имеют свое поведение, вам просто нужно взглянуть на методы объекта, чтобы узнать, что вы можете с этим объектом сделать.
Например, если вы хотите узнать, сколько символов в строке, вы вызываете метод length.
Каждый объект имеет свой собственный набор моделей поведения.
И есть одна вещь, о которой нужно знать.
Это специальное ключевое слово null.
Null – это просто слово, которое означает отсутствие объекта.
По сути, это значение 0 для объекта.
Точно так же, как 0 – это значение 0 для int или 0.0 – это значение 0 для double.
Null – это значение 0 для всех типов объектов.
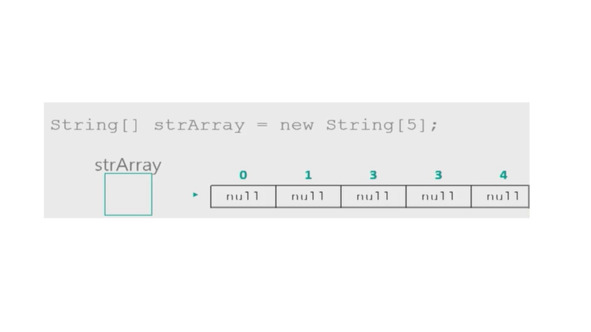
Предположим, мы создаем новый массив строк.
Если мы создадим новый массив символов, мы знаем, что он хранит значения нулей по умолчанию.
Но что он хранит в случае, когда мы создаем массив строк?
Это Null.
Это то, что автоматически заполняется в массив, что означает, объект может быть здесь, но его нет здесь и сейчас.
Это важно знать, потому что вы можете столкнуться с очень распространенным типом исключения Null Pointer.
Обычно это происходит, когда вы пытаетесь выполнить метод объекта, который является нулевым.
Например, мы хотим получить длину строки, которая хранится в этом массиве.
Там нет строки, поэтому мы получаем так называемое исключение Null Pointer.
Вы не можете назвать длину того, чего не существует.
Имейте в виду, что null означает объект, а не пустой объект.
Например, вы можете вызвать метод length для пустой String.
Это длина равна нулю.
Но нет такой длины, как длина того, чего не существует.
Просто важно знать, что null означает, что здесь нет объекта.
И нам нужно туда его поместить.
Теперь, когда мы понимаем, что такое примитив и что такое объект, важно понять, как компьютер рассматривает эти два типа переменных в своей собственной памяти.
Потому что это оказывает огромное влияние на то, как вы их программируете.
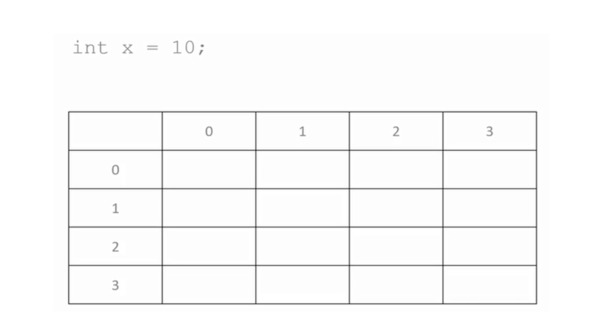
Представим себе, что это память компьютера.
На самом деле это похоже на то, как выглядит память компьютера.
Это общая сетка с адресами для каждого отдельного местоположения, очень похожая на массив.
Когда вы создаете новую переменную примитивного типа, компьютер занимает одно место в памяти и просто помещает эту информацию прямо там, имя и значение переменной.
Когда вы создаете новый объект, он является динамическим.
Он может расти и сокращаться, он может быть большим.
Поэтому компьютер должен придумать особый способ поддерживать этот объект в собственной памяти.
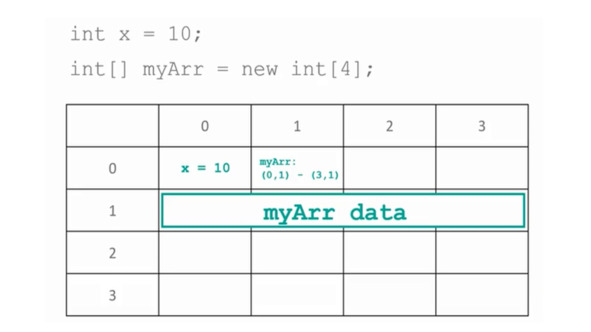
Поэтому, при создании, например, нового массива, компьютер сначала находит место в своей памяти для хранения адреса, где он будет хранить этот массив.
И затем он занимает целую секцию памяти для какого-либо большого объекта.
И, теперь у нас есть массив, находящийся в памяти, где одна из ячеек хранит адрес, где находятся реальные данные.
Это и есть ссылка.
Таким образом существует большое различие между примитивами и объектами.
Примитивы хранятся непосредственно в памяти, как только вы создаете примитив.
Они настолько малы, что это имеет смысл.
Когда вы копируете переменную примитивного типа и меняете ее значение, первоначальное значение никак не меняется.
Между ними нет реальной связи.
Это будут две совершенно разные переменные.
Как вы можете себе представить, объекты функционируют по-другому.
Вместо того, чтобы выделять пространство для фактического значения, объекты занимают пространство в памяти для ссылки на место, где хранится информация объекта.
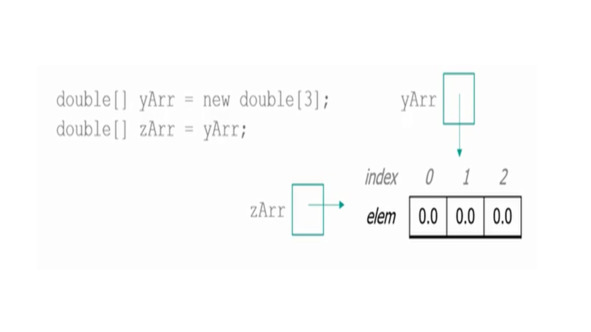
Поэтому, если я создаю новый массив, а затем создаю другой массив, и устанавливаю его равным первому массиву, что копируется?
Компьютер копирует ссылку.
Теперь у меня есть две переменные, которые указывают на одну и ту же информацию.
Поэтому, если я что-то изменяю в массиве z, изменится и массив y, и наоборот.
Вы просто скопировали адрес, где находится информация.
Поэтому, если я создам объект и передам его как параметр в метод, я передам ссылку или адрес.
И любые изменения, которые я сделаю в этом методе с объектом, будут отражены в первоначальном объекте.
Мне даже не нужно возвращать его в методе.
Как было сказано ранее, массивы – это объекты. Однако, у них нет полезных методов внутри объекта Array.
Для этого в Java есть класс Arrays,
который содержит набор статических вспомогательных методов для работы с числами, схожих с тем, как в классе Math есть набор статических вспомогательных методов для работы с числами.
Вот несколько популярных методов из класса Arrays.
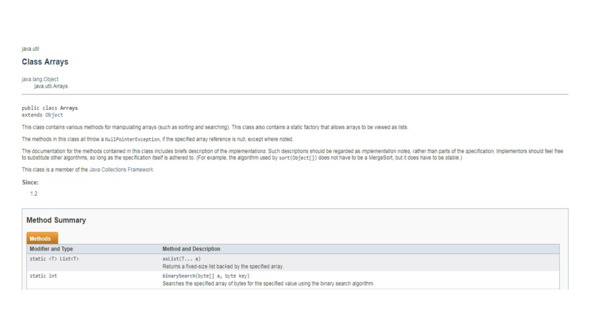
Метод toString возвращает строковое представление массива.
Метод equals определяет, одинаковы ли два массива.
Метод fill присваивает новое значение всем элементам массива.
Метод sort сортирует элементы.
Метод binarySearch выполняет поиск элемента по значению и возвращает индекс элемента в случае успеха, или отрицательное целое в случае, если такого элемента нет.
Для работы метода binarySearch необходимо, чтобы массив был уже отсортирован.

Класс Arrays находится в пакете java. util, и если вы хотите его использовать, вы должны добавить строку import java. util.* в начало Java файла.
Давайте рассмотрим пример использования пары методов из класса Arrays.

В этой задаче мы хотим вернуть медианное значение для множества чисел, где медиана – это среднее значение, когда числа отсортированы.
Для решения задачи, сначала мы создадим копию массива, т.о. мы не изменим оригинальный массив.
После создания копии, мы отсортируем массив. Потом мы просто сможем получить медианное значение, которое представляет собой просто средний элемент массива нечетной длины, или арифметическое среднее двух средних элементов массива четной длины.
Вот наш метод median, который принимает массив целых чисел в качестве аргумента, и возвращает значение типа double.
Мы возвращаем тип double, т.к. у нас может быть усреднение двух целых чисел.
Метод начинается с создания копии массива-аргумента вызовом метода copyOf класса Arrays.
Этот метод создаст копию массива с количеством элементов, которое указанно вторым аргументом.
В данном случае, мы создаем полную копию массива numbers.
После того, как копия сделана, мы сортируем ее, вызывая метод Arrays.sort.
Мы находим средний элемент массива, используя целочисленное деление, и затем определяем, четная ли длина у массива или нечетная.
Если длина четная, мы возвращаем среднее значение двух центральных элементов.
В этом случае, мы делим на 2.0, чтобы получить число с плавающей запятой.
Если длина нечетная, мы просто возвращаем центральный элемент отсортированного массива.
В заключение, давайте коротко обсудим массивы объектов.
Как упоминалось ранее, когда массив создан, его элементы инициализируются нулем 0 такого же типа, что и базовый тип массива.
Для массивов объектных типов, значение при инициализации – это специальное значение null.
Значение null просто означает, что там не пока объекта.

Например, если мы создадим массив coordinate, это массив трех элементов типа Point.
Все три элемента будут проинициализированы значением null.
Перед тем, как пользоваться этим массивом, нам нужно заменить все значения null реальными объектами Point.
Т.о. массивы объектного типа требуют инициализации в два этапа.
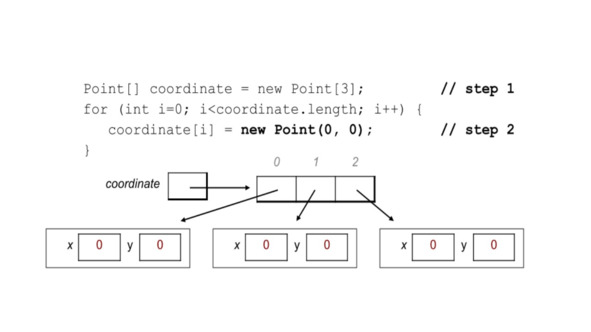
На первом тапе, вы создаете объект массива, а на втором этапе, вы создаете объект базового типа для каждого элемента массива.
В образце кода, первым шагом является создание массива coordinate.
Затем, мы выполняем второй шаг с помощью цикла, в котором создается реальный объект класса Point для элемента 0, 1 и 2.
Массивы – полезный инструмент.
Однако они имеют некоторые ограничения.
Когда вы сначала создаете массив, вам нужно выбрать его размер.
И как только вы выберете размер массива, его нельзя изменить.
Это усложняет ситуацию, если у вас есть динамический набор информации, входящий и выходящий из вашей структуры данных.
Что, если вы не знаете, сколько всего будет элементов в конце концов?
Кроме того, если вы захотите, скажем, вставить что-то в середину массива, вы должны освободить место для этого.
Это означает, что вы должны сдвинуть все остальные элементы дальше по массиву.
Было бы неплохо, если бы существовала структура данных, которая обеспечивала бы легкий доступ и организацию массива, но при этом предоставляла бы всю гибкость, которая вам нужна.
Такая структура данных в Java есть и это список.
Список представляет собой упорядоченную последовательность элементов, как и массив.
При этом, он добавляет функциональность, позволяющую ему расти и уменьшаться и вставлять элемент в середину без необходимости делать какие-либо изменения.
Также вы можете удалить элемент внутри списка.
Первый тип списка, так как в Java существует много типов списков, это ArrayList.
ArrayList хранит информацию в массиве, но при этом предоставляет дополнительную функциональность списка.
Вот несколько сравнений использования ArrayList и простого массива.

С массивом вы начнете с типа и затем набор скобок, а затем его размер.
С ArrayList, вам просто нужно знать, какой тип информации вы собираетесь хранить в нем, а затем вы создаете новый ArrayList.
И он будет расти и сокращаться по мере необходимости.
Не нужно передавать его длину.
Чтобы добавить значение в массив вы должны найти в нем место и добавить в это место значение.
В ArrayList вы можете просто сказать add и затем добавить все, что захотите, в ArrayList.
Он сам знает, где находится свободное пространство.
Вы также можете получить элемент, как и массив, используя индекс.