Бизнес-аналитика. Сводные таблицы. Часть 2. Учебное пособие

Бизнес-аналитика. Сводные таблицы. Часть 2
Учебное пособие
Валентин Юльевич Арьков
© Валентин Юльевич Арьков, 2020
ISBN 978-5-4498-3195-8 (т. 2)
ISBN 978-5-4498-3196-5
Создано в интеллектуальной издательской системе Ridero
Введение
Задание. Прочитайте в учебнике раздел «Динамика»
В первой части работы [1] по сводным таблицам мы познакомились с «базовыми» функциями этого инструмента – в самых общих чертах, хотя и довольно подробно. С большим количеством примеров, заданий и упражнений.
В данной работе мы продолжаем использовать наш общий подход к практическому освоению программного пакета: моделирование и исследование. Поэтому, кроме освоения сводных таблиц, мы поработаем с генератором случайных чисел и сформируем более-менее реалистичные наборы данных для анализа.
Попутно мы выясним, как связана бизнес-аналитика и статистика. Освежим в памяти некоторые пройденные разделы. А также увидим примеры того, к чему приводит бездумное использование машинного перевода.
Мы будем использовать последнюю версию Microsoft Excel 365, доступную на момент написания данного учебного пособия. Эта версия соответствует выпуску Microsoft Excel 2019. В других версиях программы могут немного различаться названия упоминаемых пунктов меню и кнопок, а также их расположение.
Верхнее меню в последних версиях Excel разработчики назвали лентой (Ribbon). Этот вариант меню включает в себя наиболее часто используемые инструменты. Название красивое, образное, но это по-прежнему многоуровневая система меню. К тому же, диалоговые окна, которые можно вызвать через меню ленты, совсем не изменились за последние лет десять-пятнадцать.
1. Цель и задачи работы
Целью работы является знакомство с продвинутыми функциями сводных таблиц Excel.
В процессе выполнения данной работы мы решим следующие задачи:
1) получим исходные данные путём имитационного моделирования;
2) построим сводные таблицы по смоделированным данным;
3) загрузим реальные данные из интернет;
4) построим сводные таблицы по реальным данным.
2. План работы
В данной работе мы рассмотрим следующие приёмы работы и инструменты сводных таблиц:
1. Мы сгенерируем исходные данные, в которых заложим три компонента динамики: тренд, сезонность и случайность по разным видам товаров.
2. В исходные данные мы также заложим корреляцию между количеством товаров и их ценой (функция регрессии плюс случайность).
3. По смоделированным данным мы построим сводные таблицы – уже знакомый шаг – и добавим условное форматирование для наглядности.
4. Затем проведём анализ динамики с помощью сводных таблиц, в том числе и с помощью миниатюрных графиков – спарклайнов.
5. Наконец, мы проведём анализ взаимосвязи между количеством товаров и ценой с помощью сводки и группировки данных.
6. И конечно же, мы возьмём реальные данные и применим к ним уже рассмотренные и освоенные техники анализа.
3. Отчёт
Отчёт по лабораторной работе оформляется в виде рабочей книги Excel. Вся процедура оформления отчёта подробно описана в предыдущей работе [1].
В отчёте должны быть следующие элементы:
– титульный лист;
– оглавление;
– пронумерованные листы.
Зарисовки вставляем как сфотографированные или отсканированные рисунки.
Название файла должно быть коротким и понятным.
Все эти шаги уже были описаны. Студентам предстоит освежить их в памяти и выполнить.
Задание. Оформите титульный лист и оглавление отчёта и сохраните в файле с коротким информативным названием.
4. Варианты заданий
Номер варианта – это последняя цифра номера зачётки. Если это ноль, выбираем вариант номер 10. Нулевой вариант мы рассмотрим в качестве примера для демонстрации приёмов работы.
Задание. Выясните свой номер варианта и укажите его на титульном листе.
Варианты заданий приводятся в Таблице 4.1. Для каждого варианта имеются свои параметры. Что эти цифры означают, мы скоро узнаем. Но для начала запишем их в отчёт.
Задание. Запишите в отчёте параметры своего варианта задания.

Итак, мы получили параметры задания. Разберёмся, что означают эти многочисленные слова и цифры. Это не так страшно. Кстати, в реальных данных встречается гораздо больше и слов, и цифр. Как мы уже сказали, во всех примерах мы разбираем нулевой вариант.
4.1. Справочник товаров
Вначале посмотрим на товары. У нас должно быть 3 категории по 2 товара. Сразу же придумаем их и запишем. Для этого создадим на новом листе справочник товаров (рис. 4.1). В первом столбце дадим идентификатор товара. Это целое число от 1 и (в нашем случае) до 3*2=6.
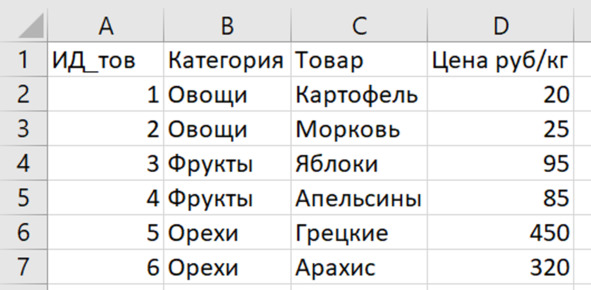
Рис. 4.1. Справочник товаров
Задание. Изучите вариант задания и сформируйте свой справочник товаров.
Справочник товаров готов. Почти готов. Чтобы нам было удобнее на него ссылаться, оформим его как таблицу Excel. Выделяем диапазон ячеек вместе с заголовками столбцов и нажимаем
Insert —Table.
Появляется диалоговое окно Create Table (рис. 4.2).
Чтобы задействовать наши заголовки, отмечаем пункт
My table has headers.
Нажимаем ОК.

Рис. 4.2. Вставка таблицы
Теперь наш справочник превращается в полноценный объект – «таблицу Excel» (рис. 4.3). Для удобства работы временно озаглавим вкладку «Тов». Затем можно будет указать только порядковый номер страницы отчёта.
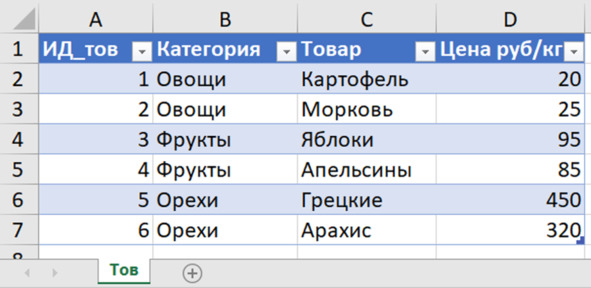
Рис. 4.3. Таблица-справочник товаров
Задание. Выделите справочник товаров и сделайте из него таблицу Excel.
Дадим нашему объекту короткое понятное название, чтобы к нему было легко обращаться. Назовем его просто: «Товары». Для этого щёлкаем по любой ячейке таблицы и выбираем в верхнем меню
Table Tools – Design – Properties – Table Name.
Вводим название таблицы и нажимаем клавишу Enter (рис. 4.4).
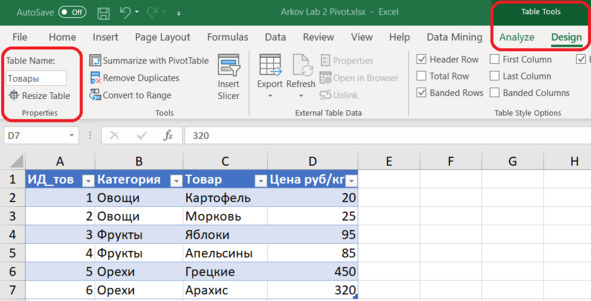
Рис. 4.4. Название таблицы
Задание. Установите название для таблицы-справочника товаров.
4.2. Справочник городов
Переходим к географии и создадим второй справочник. В нулевом варианте у нас будет 3 федеральных округа (ФО) по 2 региона в каждом округе, по 2 города в каждом регионе.
Пользуясь случаем, познакомимся картой страны и территориально-административным делением.
Задание. Изучите карту России в Википедии в статье «Федеральные округа Российской Федерации».
Карту мы успешно посмотрели, теперь можно подготовить справочник городов. Выбираем три округа и выясняем, какие в них входят республики и области. А в этих регионах какие есть города. Попутно узнаем, административные центры этих ФО:
– Центральный (ЦФО) – Москва;
– Северо-Западный (СЗФО) – Санкт-Петербург;
– Южный (ЮФО) – Ростов-на-Дону.
Наша задача очень условная и не строгая. Мы просто попытаемся смоделировать федеральную сеть продовольственных магазинов.
Чтобы узнать состав каждого ФО, перейдем по ссылкам и ознакомимся с описанием соответствующего ФО (рис. 4.5). Точно так же можно узнать состав каждой области, перейдя по ссылкам.
Рис. 4.5. Состав ФО
Задание. Выберите ФО и ознакомьтесь с их составом.
Задание. Выберите регионы в составе ФО и ознакомьтесь с их административно-территориальным делением.
Мы посмотрели на карту местности и теперь можем переходить к творчеству. Сформируем справочник регионов и городов (рис. 4.6). Назначим простое и понятное название нашему справочнику – для дальнейшей работы.
Мы получили 3 ФО по 2 региона по 2 города, то есть общее количество городов равно
3*2*2=12.
Всего 12 городов. Это совсем немного для федеральной сети. Можно представить, с каким количеством данных приходится работать на реальном предприятии.
В первой части работы мы генерировали названия магазинов. По несколько штук в каждом городе. В данной работе мы остановимся на городах – для знакомства с функциями сводных таблиц. Дальнейшую детализацию пока не будем рассматривать.
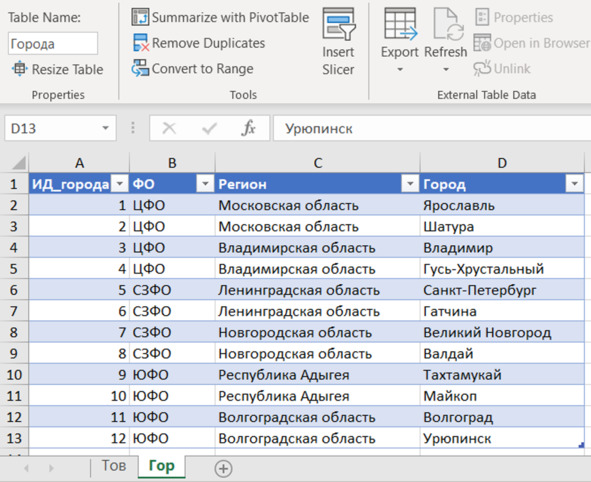
Рис. 4.6. Справочник городов
Задание. Сформируйте справочник городов для своего варианта.
4.3. Модели динамики
ДИНАМИКА – это изменение чего-то во времени. Какого-то статистического признака. Отдельные значения прявязаны к моментам времени. В нашем случае сведения о каждой покупке привязаны к конкретным датам.
В динамике выделяют три компонента, три составные части:
– тренд;
– сезонные колебания;
– случайная составляющая.
Компоненты динамики – это составные части. Это «кирпичики», из которых строится конкретная модель. Компоненты – это разные части. Очень разные. Они не похожи друг на друга. Ихтрудно перепутать. Только если очень постараться.
Для анализа, пронозирования и имитационного моделирования динамики используют два вида моделей:
Аддитивная модель – сумма компонентов.
Мультипликативная модель – произведение компонентов.
Задание. Прочитайте в учебнике «Теория статистики» раздел «Динамика» и выясните, как выглядят компоненты динамики и модели динамики.
Задание. Сделайте зарисовки графиков трёх компонентов динамики и двух видов моделей динамики.
4.4. Тренд
Далее сформируем ТРЕНД. Это долгосрочная тенденция. Общее направление изменений. В нашей модели тренд – это количество товара в одном чеке, в одной покупке. Будем моделировать постепенный рост покупок в течение нескольких лет.
Для нашей модели тренда нам понадобится два значения из параметров задания:
– Начало – начальное значение на линии тренда;
– Конец – последнее значение на линии тренда;
– Период – интервал времени в годах.
В нулевом варианте мы получили такие параметры:
– Начало = 2;
– Конец = 4;
– Период = 2.
Мы будем моделировать данные за два последних года. На момент написания пособия текущий год 2020. Так что возьмём данные за 2018—2019 годы. То есть наш интервал времени такой:
01.01.2018 – 31.12.2019.
Задание. Определите интервал дат для моделирования.
Напомним, что дата в пакете Excel хранится как порядковый номер дня. Мы будем моделировать даты как целые случайные числа. Но для этого нам нужно определить, какие номера дней соответствуют нашим датам.
Запишем даты начала и конца интервала моделирования. Будем вводить даты так, что Excel догадался, что это даты, а не просто какой-то текст:
2018-01-01
2019-12-31.
Даты распознали как даты, и они выводятся в формате даты.
Скопируем даты в соседние ячейки и установим общий формат (рис. 4.7):
Format Cells – Number – Category – General.
Получаем номера дней:
– начало интервала = 43101
– конец интервала = 43830.
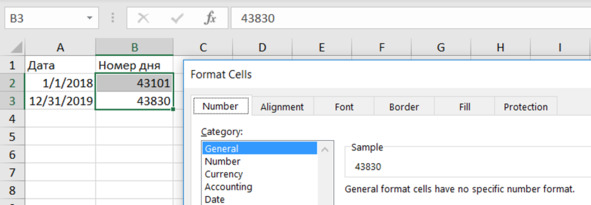
Рис. 4.7. Даты интервала моделирования
Задание. Определите номера дней для своего интервала.
Сделаем зарисовку —как должен выглядеть график. Как должна проходить линия тренда. Рисуем от руки на бумаге, фотографируем и вставляем в наш отчёт (рис. 4.8).
Работу с зарисовками мы уже обсуждали в предыдущих работах. Главное – нужно мысленно представлять себе, что мы ожидаем получить. Тогда можно будет обнаружить грубые ошибки.
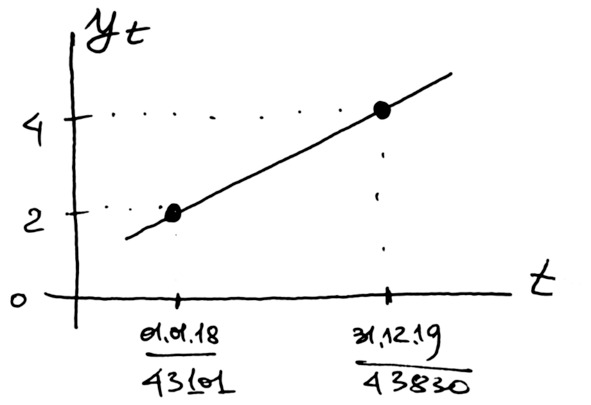
Рис. 4.8. Зарисовка линии тренда
Задание. Сделайте зарисовку линии тренда и вставьте в отчёт.
Далее нам понадобится построить уравнение тренда для моделирования. Добавим в нашу табличку новую колонку – значения на линии тренда:
Начальное значение = 2
Конечное значение = 4.
Выделяем колонки дней и значений и строим график:
Insert – Charts – Insert Scatter (X, Y) or Bubble Chart – Scatter – Scatter with Straight Lines.
Всплывающая подсказка сообщает, что такой график используют, когда есть два набора данных (рис. 4.9). У нас как раз два набора – дни и значения.
Рис. 4.9. Вставка диаграммы
Задание. Постройте график тренда.
Появляется график (рис. 4.10). Рассмотрим его поподробней. Вид довольно странный. Это не совсем то, что мы хотели и что мы ожидали. Даже совсем не то. Мы хотели увидеть номера дней по оси «иксов», а значения по оси «игреков».
Вот для чего нужна зарисовка! И просто мысленное представление будущих результатов. Мы сразу заметили отличие от того, что должно быть.
В таблице данных для графика выделены две строки. То есть Excel решил, что у нас данные расположены по строкам, а не по столбцам.
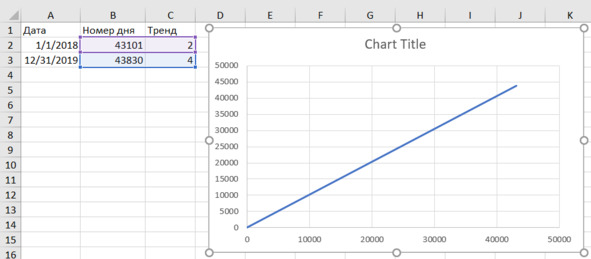
Рис. 4.10. Первоначальный вид графика
Задание. Рассмотрите полученную диаграмму.
Исправим выбор данных для графика (рис. 4.11). Щёлкаем по графику и выбираем в контекстном меню
Select Data.
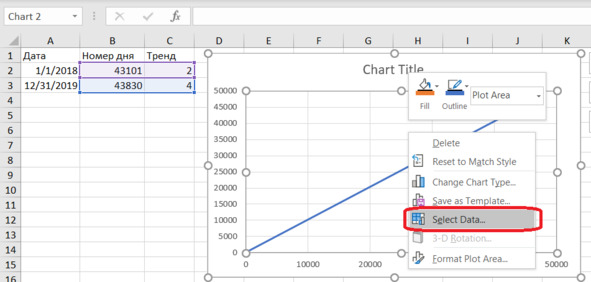
Рис. 4.11. Выбор данных для графика
Появляется диалоговое окно
Select Data Source.
Переходим к редактированию источника данных (рис. 4.12):
Select Data Source – Legend Entries (Series) – Edit.
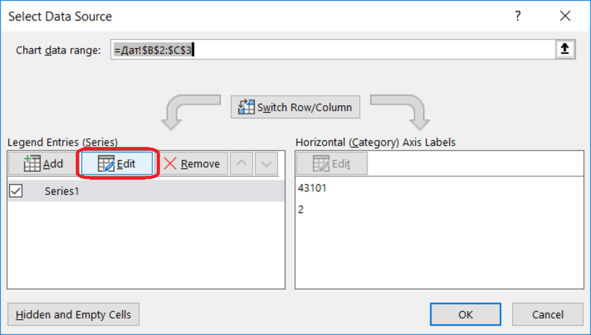
Рис. 4.12. Редактирование источника данных
Появляется диалоговое окно
Edit Series.
Указываем, что наши данные расположены по столбцам (рис. 4.13):
Series X values;
Series Y values.
Нажимаем ОК и получаем более приемлемый вид графика.

Рис. 4.13. Выбор данных по столбцам
Задание. Установите расположение данных для графика по столбцам.
Ещё немного, и мы получим уравнение тренда. Графики позволяют быстро получить уравнение по точкам (рис. 4.14).
Щёлкаем по графику и нажимаем на кнопку [+] справа от графика. Выбираем в меню
Chart Elements – Trendline – More options.
По умолчанию линия строится в виде прямой линии и соответствующей линейной функции.

Рис. 4.14. Настройка линии тренда
В правой части окна Excel появляется раздел настройки графика тренда (рис. 4.15). Устанавливаем следующие настройки:
Format Trendline – Trendline Options – Linear – Display Equation on chart.
Заодно и название графика зададим. Чтобы было понятно читателю, что мы тут изобразили.
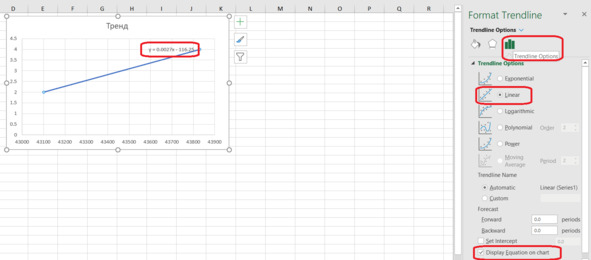
Рис. 4.15. Вывод уравнения тренда
Получаем уравнение тренда на графике. Можно его немного подвинуть. Перетащим уравнение мышкой на свободное место (рис. 4.16).
Итак, вот наше уравнение:
y = 0,0027 x – 116,25.
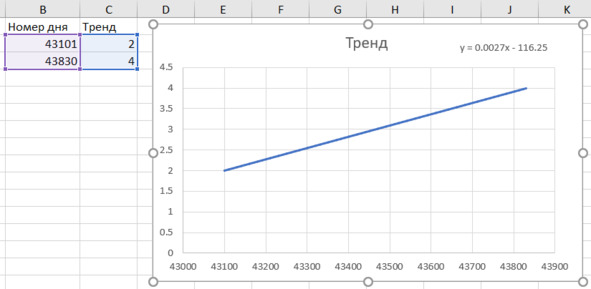
Рис. 4.16. Уравнение и линия тренда
Задание. Включите вывод уравнения тренда на график
Всё вроде бы хорошо, но коэффициент при «иксе» содержит всего два значащих разряда. Нули перед ними не дают особой точности. А вот свободный член уравнения даёт пять значащих разрядов. Исправить вид графика будет довольно сложно.
Мы пойдём другим путём. Вызовем надстройку «Анализ данных» (рис. 4.17) и попросим построить нам уравнение регрессии:
Data – Analysis – Data Analysis – Regression.
Что это такое и как это работает – мы разбирали в одной из предыдущих работ [2].
Появляется диалоговое окно
Regression.
Указываем диапазоны ячеек для «игреков» и для «иксов»:
– Input Y Range;
– Input X Range.
Чтобы всё запутать, вначале нас просят ввести «игреки». Но мы не поддаёмся на провокации и делаем всё правильно.
Ещё нужно указать, куда выводить результаты анализа. Указываем на свободное место.
Нажимаем ОК.

Рис. 4.17. Построение регрессии
Задание. Вызовите надстройку «Анализ данных» и выберите построение регрессии.
Рассмотрим результаты регрессионного анализа (рис. 4.18).
Среди большого количества цифр нас будет интересовать раздел с коэффициентами. Напомним, кто есть кто:
Intercept – свободный член уравнения
X Variable 1 – коэффициент регрессии, то есть коэффициент при «иксе». В нашем случае, при переменной t, которая обозначает время, номер дня.
Теперь можем записать наше уравнение тренда более точно. Оставляем по пять значащих разрядов в каждом коэффициенте:
y = —116,25 +0,0027435 t.
Последний разряд округляем.
Обратите внимание, как выглядят ЗНАЧАЩИЕ ЦИФРЫ. Перед ними и после них может быть много нулей, которые могут и не содержать полезной информации.
Кстати, это пример ситуации, когда ДАННЫЕ и ИНФОРМАЦИЯ – не одно и то же. Много данных в виде цифр – это не обязательно много полезной информации. Это просто цифры. А информация должна быть ПОЛЕЗНОЙ для дела.
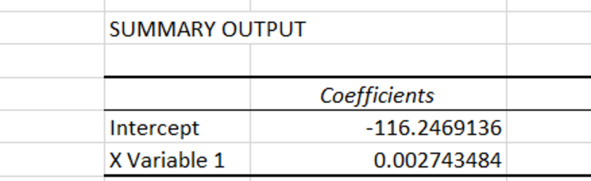
Рис. 4.18. Результаты регрессионного анализа
Задание. Запишите уравнение тренда с точностью до пяти значащих цифр.
4.5. Сезонные колебания цен
Сезонные колебания – это изменения с периодом в один год. То есть двенадцать месяцев, или примерно 365 дней. Сезон – это времена года и всё, что с ними связано.
Причина сезонных колебаний цен – это изменение количества товаров, которое предлагается на рынке. В экономике это называется ПРЕДЛОЖЕНИЕ. Понятно, что сразу после сбора урожая сельскохозяйственной продукции много, и цены обычно снижаются. А вот когда запасы подходят к концу, цена может вырасти. Эта картина повторяется каждый год.
Мы будем моделировать сезонные колебания цен в диапазоне плюс-минус 10% от среднего значения цены. Пусть все цены достигают минимального значения в октябре каждого года. И пусть они меняются по синусоиде.
Пусть минимум будет 1 октября 2018 года. Находим порядковый номер этого дня, как мы уже проделали в предыдущем разделе (рис. 4.19). Получаем число
t (min) = 43104.
Это не наименьшее время.
Это день, когда цены минимальные.

Рис. 4.19. Дата минимальных цен
Определим начало периода синусоидальных колебаний (рис. 4.20). Это будет номер дня 1 октября 2018 года минус 9 месяцев, то есть минус 9*30 = 270 дней:
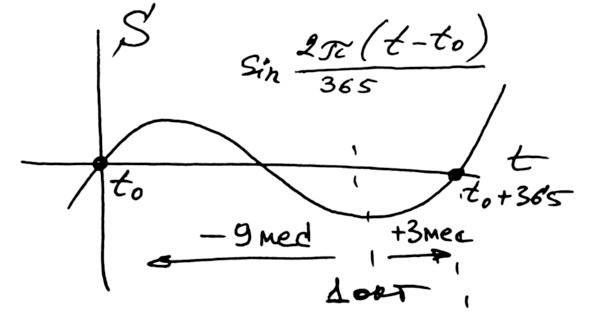
Рис. 4.20. Начало периода колебаний
Таким образом, получаем начало периода колебаний (рис. 4.21).
t0 = 43374 – 270 = 43104.
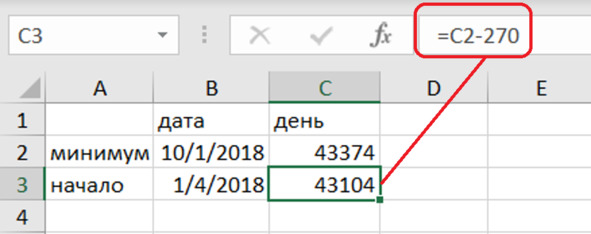
Рис. 4.21. Начало периода колебаний
Мы собираемся моделировать колебания в пределах плюс-минус 10% средней цены. В этом случае придётся использовать мультипликативную модель [3]. Так что в уравнении сезонных колебаний это будут колебания вокруг единицы с амплитудой 0,1 (рис. 4.22).
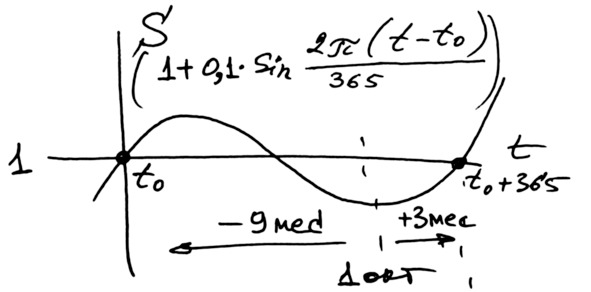
Рис. 4.22. Мультипликативная модель
Конечно, это очень упрощённая модель. Форма колебаний не похожа на синусоиду. А время сбора урожая различается для моркови и для орехов.
В наших упражнениях самое главное – почувствовать саму идею. А если будет желание, можно сделать более реалистичное описание.
Задание. Запишите формулу сезонных колебаний цен с конкретными числовыми параметрами.
4.6. Сезонность спроса
Наша модель будет дополнительно учитывать «рациональное» поведение покупателей. Будем считать, что клиенты стремятся покупать большее количество, когда цены падают. И стараются экономить при повышении цен, то есть покупать меньшее количество товара.
В нашей модели количество покупаемого товара, то есть СПРОС, будет переживать сезонные колебания. Колебания будут в противоположной фазе в сравнении с колебаниями цен. То есть 1 октября будет максимум покупок. Соответственно, начало периода колебаний – это 1 октября минус три месяца:
t0 = 43374 – 3*30 = 43374 – 90 = 43284.
Это начало июля. К началу октября покупки растут. К январю цены выросли, а закупки упали. И так повторяется каждый год.
Задание. Запишите уравнение сезонных колебаний спроса с конкретными значениями коэффициентов.
Мы заложили в нашу модель взаимосвязь между уровнем цен и спросом, то есть количеством купленного товара. Это зависимость в среднем – на фоне случайного разброса, отклонений. Наличие такой зависимости называется КОРРЕЛЯЦИЯ (рис. 4.23). Слово «корреляция» происходит от латинского correlatio – «соотношение, взаимосвязь», где co– — «со-, взаимо-, вместе» и relatio – «отнесение, связь». Если в среднем значение увеличивается, это прямая корреляция, если уменьшается – то обратная.
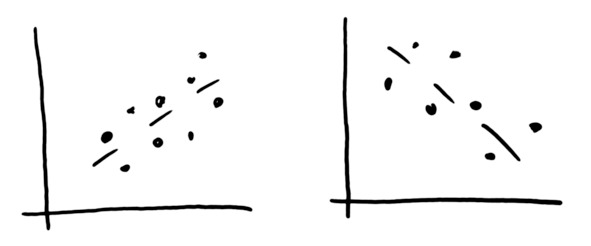
Рис. 4.23. Прямая и обратная корреляция
Задание. Запишите в отчёте ответ на следующий вопрос. Какой вид корреляции между спросом и предложением заложен в нашей модели и насколько это соответствует действительности?
4.7. Случайность
Ко всем значениям спроса и предложения мы добавим случайную составляющую. Это будет разброс вокруг цены и количества товара в каждой покупке. Случайный разброс составит плюс-минус указанное количество процентов. В нулевом варианте это плюс-минус 20%.
Случайную составляющую будем моделировать как числа с нормальным распределением. Значит, разброс в 2 процента составит три сигмы. Находим сигму:
сигма = 20% / 3 = 0,2 / 3 = 0,066667.
Задание. Определите величину сигмы для своего варианта.
5. Имитационное моделирование
У нас всё готово для моделирования исходных данных. Как и в предыдущей работе, мы создаём таблицу транзакций. Во всех вариантах у нас будет 10000 записей, то есть строк.