
Яндекс.Директ. 3 простых главы по настройке. Путь от начинающего до профессионала
Еще несколько примеров правильного сокращения фраз для обобщенного подбора семантического ядра.
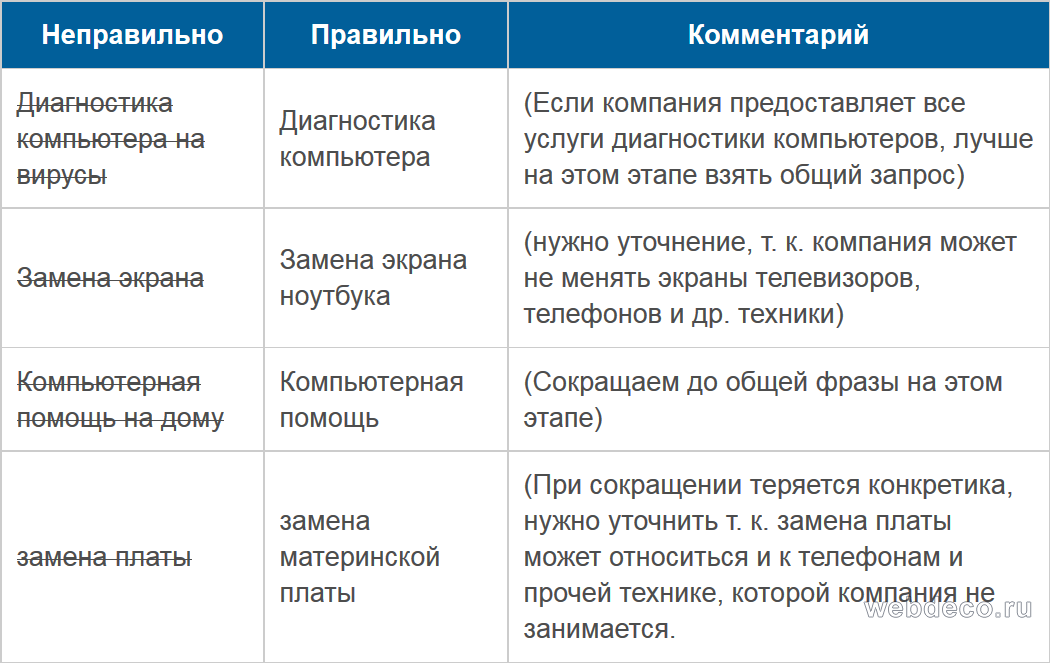
Как вы понимаете, наша цель при составлении обобщенного семантического ядра сайта – максимально сократить ключевые фразы, но в то же время, чтобы они не потеряли смысла и не стали слишком общими. Сокращение фраз необходимо, чтобы потом легче и быстрее работать далее. Более развернутые и точные сочетания, мы получим на 5 этапе для каждого обобщенного запроса.
Все фразы копируем в текстовый редактор, в примере я использовал бесплатный OpenOffice.
2 Этап. Группировка обобщенных фраз
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
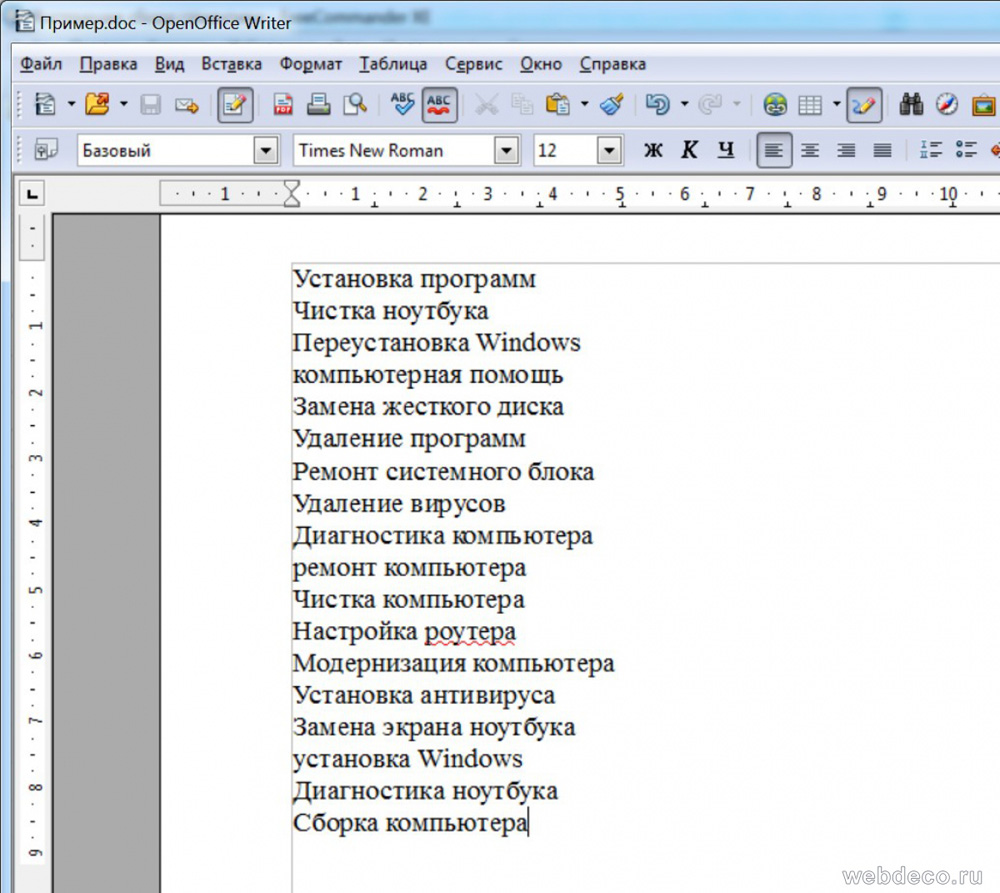
На этом этапе нам нужно сгруппировать полученные фразы по общему смыслу, чтобы потом легче было их сравнивать с новыми. Если группировку не произвести на данном этапе, то в конце она все равно потребуется, но будет уже сложнее из-за большого количества фраз.
Мы должны получить список запросов, сгруппированных по смыслу. Для удобства, сверху я подписал заголовки, чтобы легче было ориентироваться.
3 Этап. Сбор семантического ядра с сайтов конкурентов (обобщенные фразы)
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
Сбор семантического ядра конкурентов – следующий шаг. А конкурентов можно найти в поисковых системах. Наберите несколько самых популярных ключевых словосочетаний, из тех, что вы составили на первом этапе. Например, в нашем случае, достаточно набрать в поисковике: «Ремонт компьютеров», «Компьютерная помощь». Затем:
Заходите на сайты конкурентов, обычно достаточно первых 5—10 сайтов и дописывайте в имеющийся список:
– Заголовки и ключевые слова страницы, куда вы попали из поисковой системы, а также дополнительных страниц, которые посчитаете нужными.
– Ссылки из меню на сайтах конкурентов.
Стараемся дописывать, насколько это возможно, максимально краткими обобщенными фразами, но в то же время полностью подходящими для продвигаемого сайта.
Важно: Если вы находитесь не в Москве, то набирайте поисковые запросы со словом «Москва», даже если вы территориально в другом регионе. Это позволит вам получить самые лучшие сайты, т. к. конкуренция в Москве самая высокая среди др. регионов. Например, если мы находитесь в Самаре, то лучше наберите запрос: «оптимизация сайта в Москве», чем просто «оптимизация сайта», т. к. без слова «Москва» будет региональная выдача результатов.
Обычно хватает пройти 3–5 сайтов конкурентов, чтобы собрать основные продвигаемые фразы.
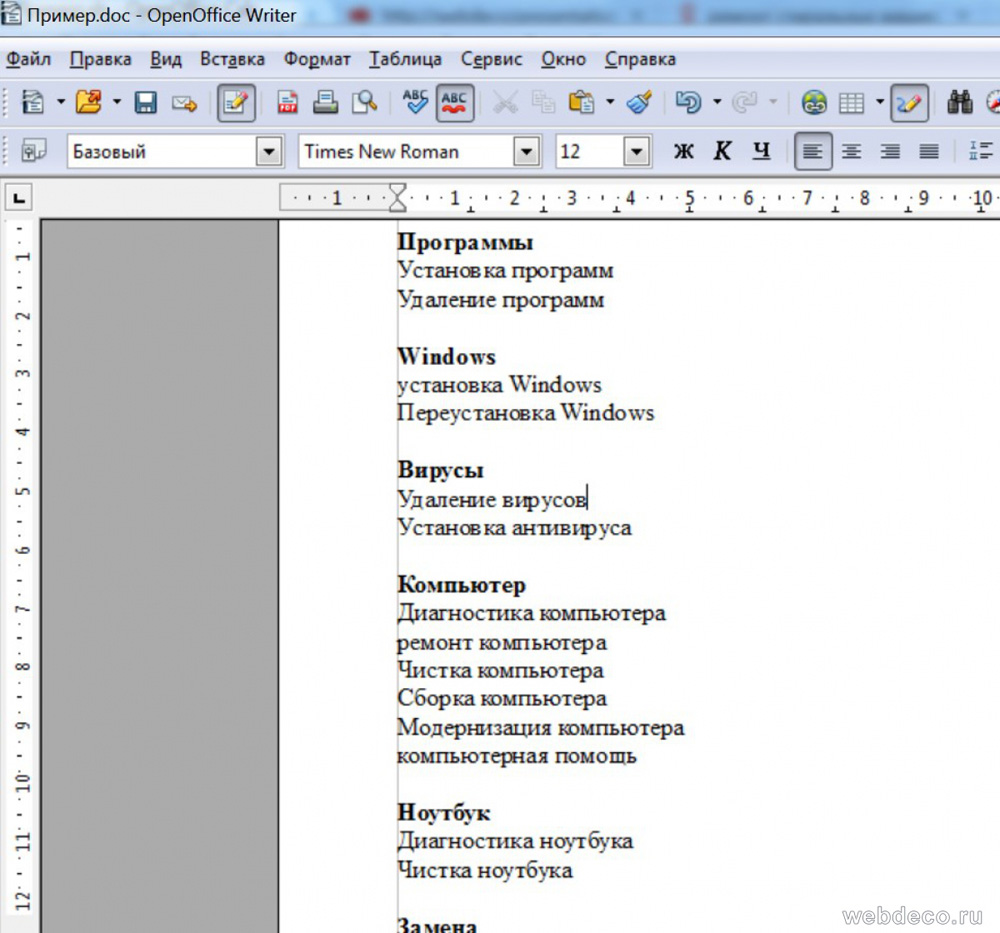
Если вы хорошо сгруппировали запросы на 2 этапе, то на 3 этап уйдет немного времени. Ниже пример, в нем темно-желтый шрифт – запросы, собранные с собственного сайта, а черный шрифт – дополненные фразы конкурентов.
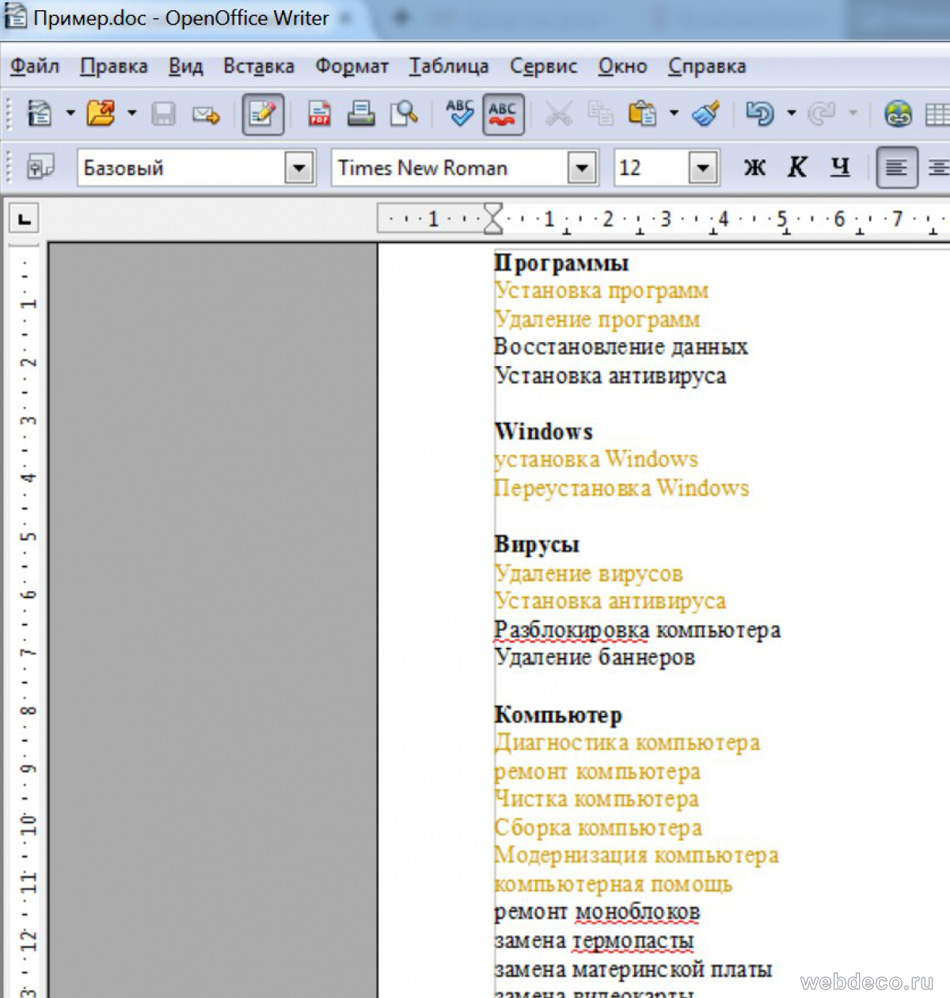
Важно: Если не сгруппировать запросы на 2 этапе, то на 3 этапе нам пришлось бы значительно дольше дополнять список, т. к. перед добавлением новой фразы необходимо убедиться, что ее еще нет в списке.
4 Этап. Сбор семантического ядра с Яндекса и Гугл
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
Первые 2 этапа были базовые, а на 3 этапе мы уже подойдем к завершению составления семантического ядра слов. Именно с помощью статистики Яндекса можно узнать фразы схожие по смыслу и синонимы, иначе говоря, дополнить список, составленный на первых 2 этапах.
4.1. Статистика Яндекса
Основа для сбора семантического ядра – сервис Яндекса wordstat.yandex.ru, предварительно нужно зарегистрироваться или войти в личный кабинет.
В поисковой строке на wordstat.yandex.ru вводите ключевые слова, подготовленные на первых 3 этапах, и вы увидите в правой колонке дополнительные фразы, схожие по своему значению. На левую колонку пока не обращаем никакого внимания.
Выписываем все новые фразы из правой колонки, которых еще нет в нашем списке. Стараемся их сокращать, как на первых этапах, если не теряется смысл.
Например, набрав запрос «ремонт компьютера» в правой колонке, нашлись фразы схожие по смыслу, которых у нас еще нет: «ремонт пк», «компьютер обслуживание», «компьютер настройка», «компьютерный мастер» и другие схожей тематики. Ими и будем дополняем наш список. Таким образом, нужно ввести каждое словосочетание из нашего списка и записать все новые фразы из правой колонки.
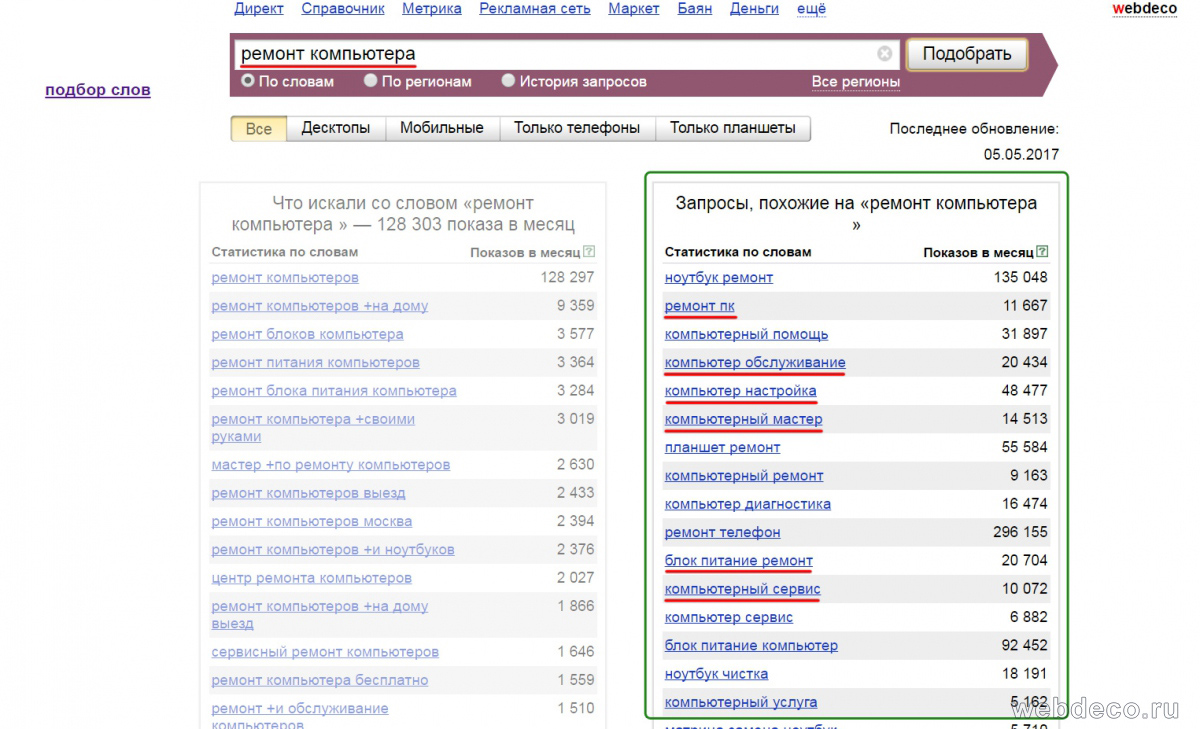
Этот шаг очень важен, т. к. по самым популярным фразам наибольшая стоимость за клик, а по менее популярным кликам цена за клик может быть меньше на порядок, поэтому от того насколько хорошо вы запишите все дополнительные фразы будет зависеть бюджет и эффективность рекламной кампании.
В итоге, подставив каждую фразу в окошко, наш список дополнился из правой колонки Яндекса, схожими по значению и получился примерно такой перечень(красным выделены запросы, собранные из правой колонки Яндекса)

Как видите, список состоит только из общих запросов.
4.2 Левая колонка Яндекса или как собрать детальное семантическое ядро
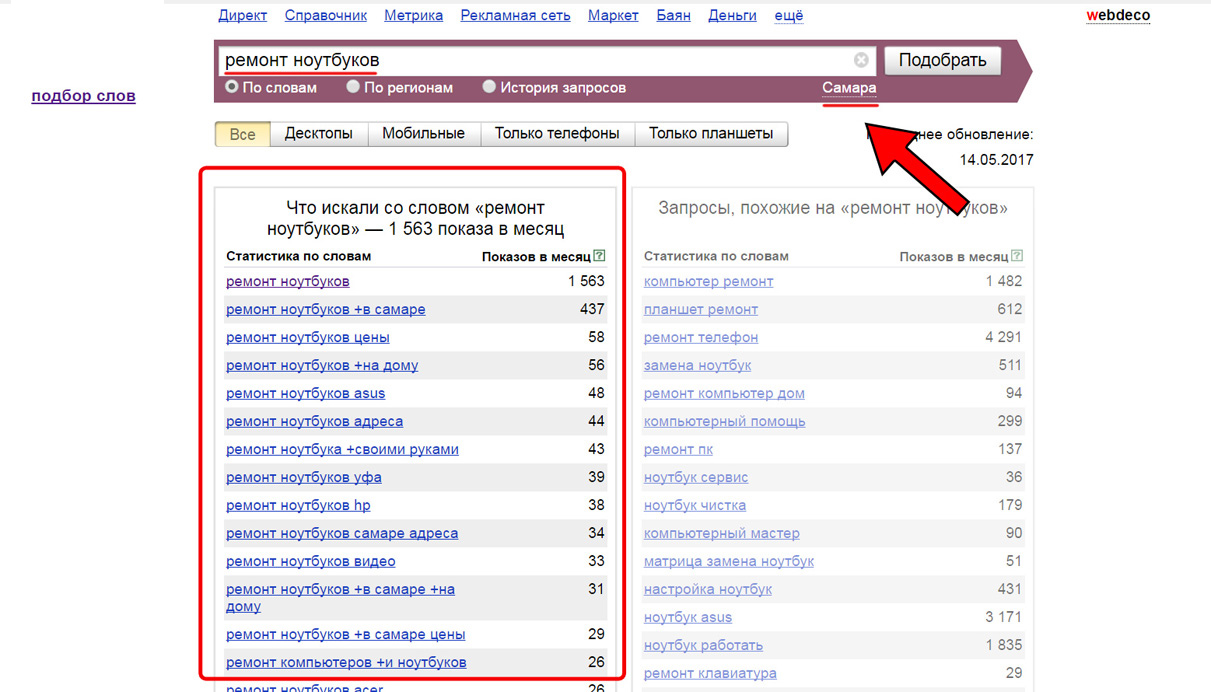
Теперь пришло время, узнать как собрать семантическое ядро со всеми вложенными запросами. Заходим в wordstat.yandex.ru и в окошке набираем ключевую фразу, например: «ремонт ноутбуков». В левой колонке, вы увидите различные вариации поисковой фразы и частоту запросов в течение месяца по Яндексу. Левая колонка нужна в первую очередь, чтобы оценить спрос и получить все основные словосочетания фраз.
Важно: Обязательно выберите регион, в котором планируете давать рекламу, иначе вы получите статистику по всему миру.
Данные по регионам можно получить, если вы под стройкой поиска выберете свой. Например, в Самаре запросы со словами «ремонт ноутбуков» набирают 1563 раза в месяц.
4.3 План по сбору точной статистики семантического ядра с Яндекс wordstat
Переходим к делу: Открываем список ключевых фраз, собранных на первых этапах и делаем следующие шаги:
1. Вводим каждую фразу, собранную на первых этапах в окошко wordstat.yandex.ru, нажимаем «Подобрать».
2. Выделяем все, что в левой колонке и копируем в файл exel и кликаем на следующую страницу снизу. Нужно пройти минимум 5 страниц, в идеале 10 страниц и скопировать с каждой страницы все ключевые фразы. Если страниц меньше, чем 10, ничего страшного, значит копируем, сколько есть.
Повторяем шаги 1—2 для каждого словосочетания, пока вы не получите данные частотности по всем фразам и не пройдете весь список.
В итоге у нас должен получиться большой список с уточнением хвоста запросов по каждой фразе примерно такого вида(в примере указывали регион Самара):

4.4. Статистика Гугл
Если вы все-таки решились изучить сбор ключевиков в Гугл, то сделайте следующее:
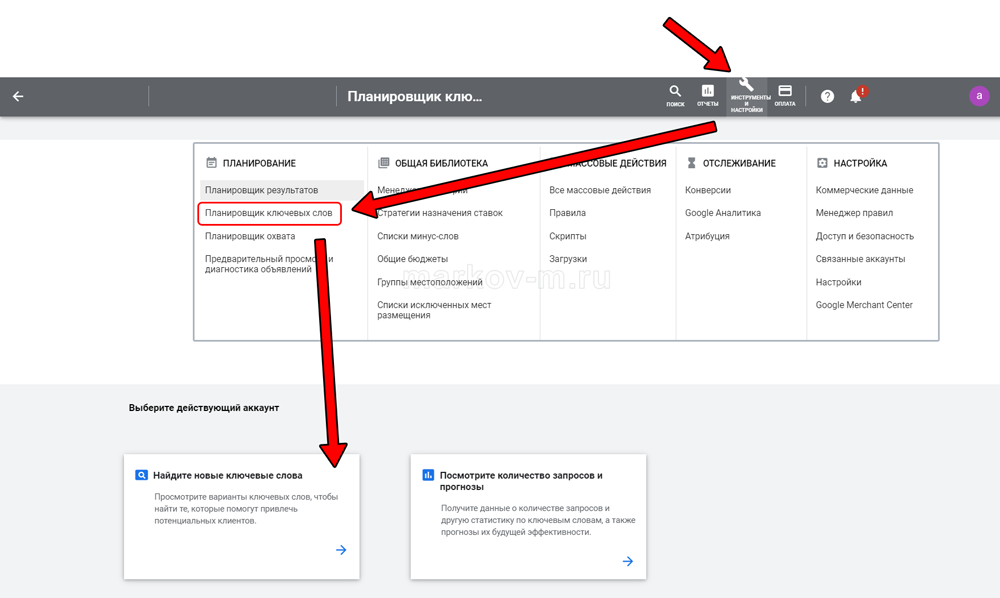
А. Зарегистрируйтесь в https://ads.google.com.
Б. Перейдите в планировщик ключевых слов. Для этого кликните «Инструменты и настройка» -> «Планировщик ключевых слов» -> «Найдите новые ключевые слова».
В. Укажите ключевые слова и местоположение. Для этого введите ключевые запросы, укажите регион, при необходимости язык и кликните «Показать результаты».
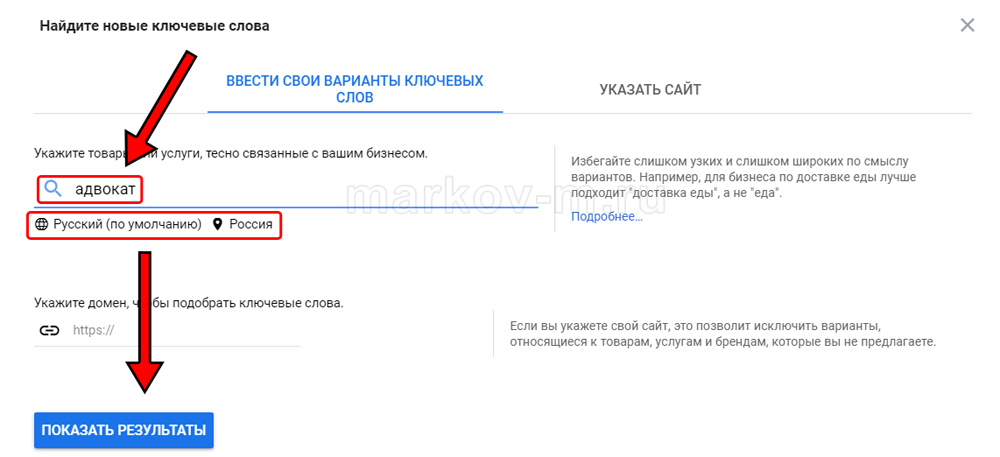
Ниже будет показано количество запросов данной фразы в указанном местоположении в течение месяца. Дополнительно в таблице могут быть указаны другие «Варианты ключевых слов».
Важно: Статистика в Гугл рассчитывается только для заданного ключевого словосочетания без учета дополнительных фраз, включающих указанный запрос. Например, если набрать запрос «адвокат», то в расчет общей суммы запросов не будет браться «адвокат в Москве», как в Яндексе. По сути, это то же самое, как если в wordstat.yandex.ru набрать фразу в кавычках.
В итоге вы получите более бедные данные, чем в Яндексе, т. к. не учитывается сумма всех фраз, включающих данный запрос и статистика по дополнительным фразам тоже сильно уступает.
5 Этап. Автоматическое создание семантического ядра
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
Автоматическое создание семантического ядра значительно проигрывает ручному сбору, т. к. анализ происходит на основе ключевых слов основных страниц конкурентов, а значит, в автоматической статистике может быть упущено большое количество запросов со второстепенных страниц.
Но даже запросы с главных и основных страниц сайта будут неполными, т. к. оптимизацию одной страницы можно сделать всего под 2—3 ключевые фразы с различных хвостом слов, т. е. получаем не более 20-30 различных вариаций.
Важно: Использовать автоматические сервисы сбора ключевых слов имеет смысл только в качестве дополнения, если вы сделали предыдущие этапы вручную, иначе вы можете получить неполные данные статистики.
5.1 Сервис Megaindex
Быстрый и удобный автоматический сервис сбора семантического ядра для сайта онлайн – это Megaindex. Сервис платный, на момент написания статьи, минимальная стоимость составляла 1500 руб. в месяц, хотя ранее был бесплатным.
Чтобы получить статистику зарегистрируйтесь на Megaindex.com, затем перейдите по ссылке «Подбор и кластеризация запросов». Перед вами будет окошко, в которое напишите адрес вашего сайта и выберете регион для продвижения.
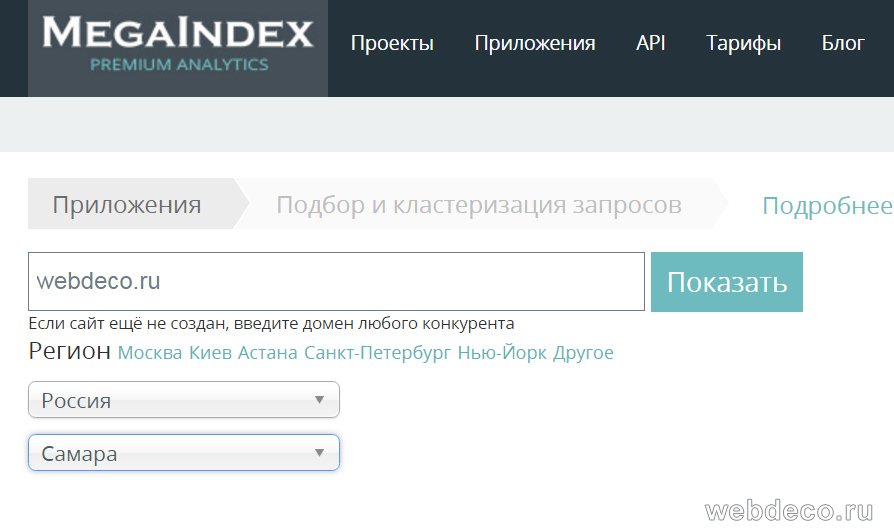
На следующем шаге добавьте конкурентов, желательно не менее 20, можно больше и нажмите продолжить. В итоге вы получите список основных запросов, по которым продвигаются ваши конкуренты.
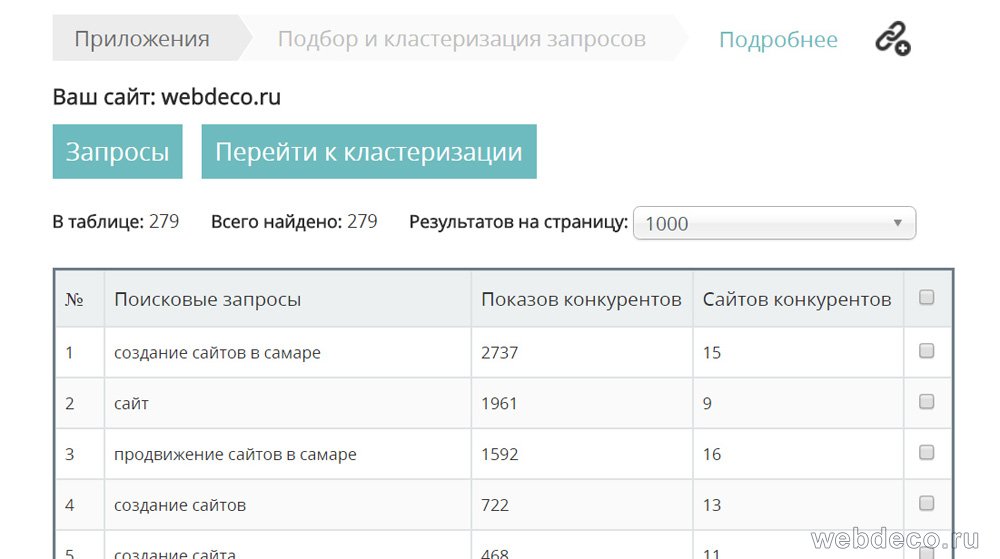
5.2 Программа key collector
Программа для составления семантического ядра key collector – одна из лучших среди профессиональных решений подбора и анализа. Единственный недостаток – это только платные версии. Рекомендую сначала освоиться с ручным подбором семантики, а потом уже пробовать все остальное, в том числе и key collector, т. к. если вы не профессионально занимаетесь продвижением сайтов, то зачастую быстрее сделать все вручную.
6 Этап. Чистка списка
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
Теперь в полученном списке нужно отметить все подходящие и неподходящие фразы.
Важно: Не удаляйте неподходящие фразы, а только помечайте, т. к. они нам еще потребуются для составления списка минус слов.
Быстрая сортировка нужных и ненужных фраз
Быстрее всего отделить нужные фразы от ненужных можно следующим способом:
1. Отмечаем цифрами в соседней колонке Exel:
«1» – если фраза нужная;
«»(ничего не ставим) – ненужная фраза;
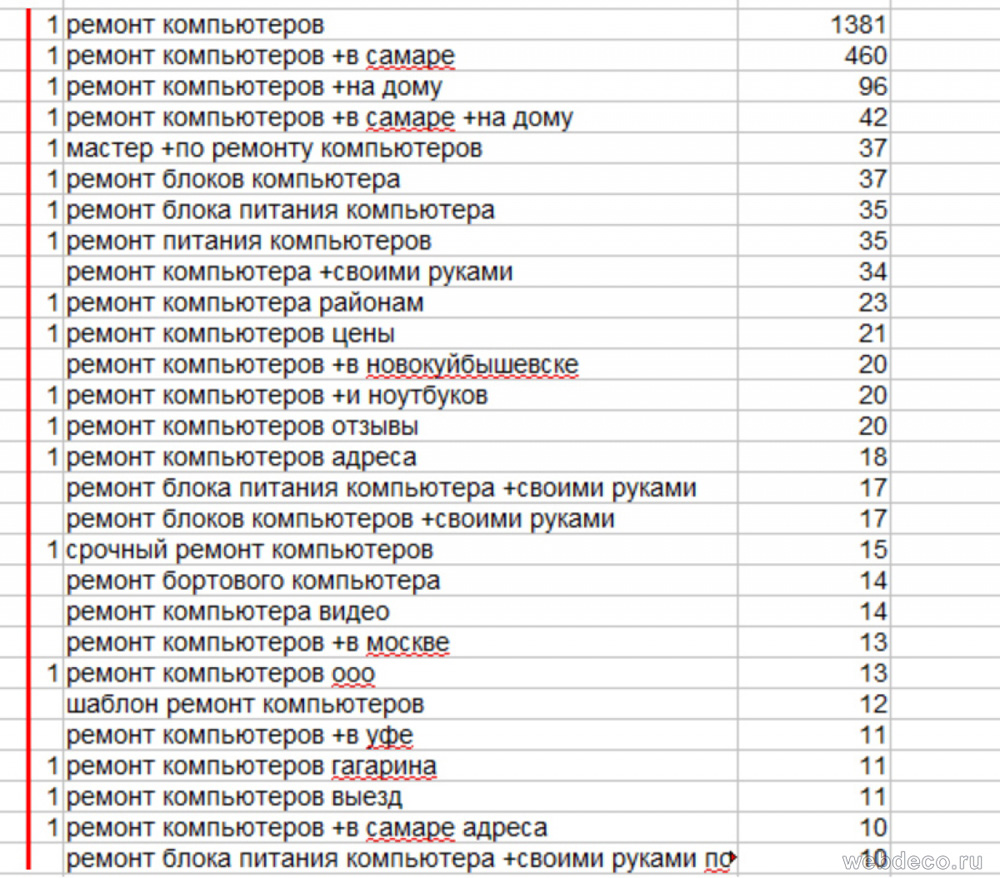
Если смысл фразы неясен, то просто наберите ее в wordstat.yandex.ru и по хвосту запроса в конце поймете ее смысл. Например, фраза «чистка компьютера от мусора» может иметь несколько значений: механическая, программная очистка. Чтобы понять, что пользователи имеют ввиду – вводим это словосочетание и смотрим в левой колонке на распределение хвоста запросов.
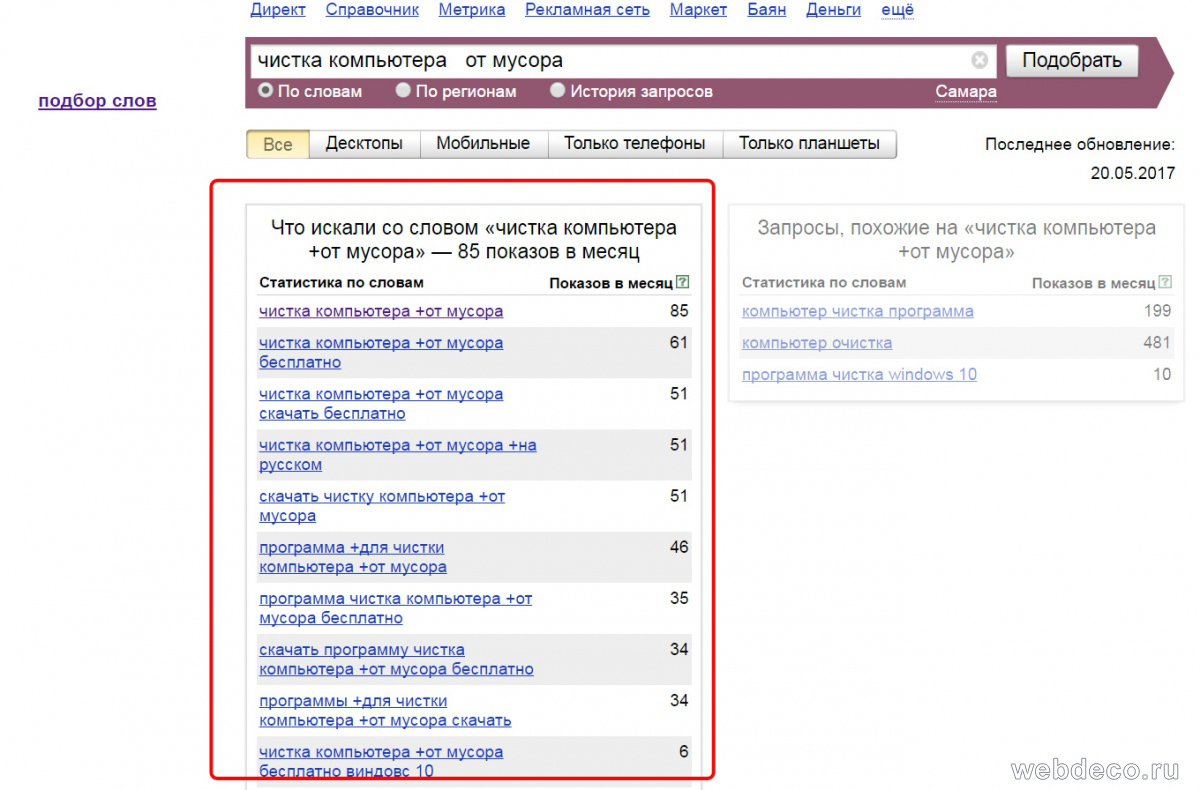
Как видим, по данному запросы пользователи ищут именно программную очистку, поэтому не стоит рекламировать по это фразе услуги по механической чистке.
Проходим весь наш список помечаем единицей все фразы, которым нам интересны и ничего не ставим напротив ненужных запросов.
Важно: При составлении семантического ядра сайта для Яндекс директ или google adwords не удаляйте ненужные запросы, даже если они вам не подходят по смыслу, позже мы их переместим в отдельный список, чтобы подготовить минус-фразы. Подробнее про список минус-фраз описано ниже. Это действие может сэкономить вам 50% бюджета.
Дополню, что есть запросы из семантического ядра, которые вроде бы целевые, но в то же время имеют низкую эффективность, поэтому с целью экономии бюджета их также можно отнести к ненужным. Правильно сематическое ядро сайта НЕ должно содержать следующее:
– Фразы с вопросами: «как», «почему», «зачем» и подобные, т. к. по ним люди еще не определились, будут ли они покупать или нет.
– Ключи с упоминанием ваших конкурентов. Если посетитель вводит название вашего конкурента, то уже отдает свое предпочтение ему, значит, ваше объявление уже проигрывает, поэтому такие запросы менее эффективны.
– Фразы со словами «дешево», «бесплатно», «недорого», «акция», «скидка» тоже являются более низкого качества, т. к. их вводят клиенты, планирующие экономить.
2. Сортируем по цифрам каждый блока фраз.
Важно: Нам нужно чтобы список остался сгруппированным по блокам обобщенных фраз, поэтому поочередно выделяем каждый блок и делаем внутри него сортировку.
Выделив поля и сделав сортировку(Для редактора Calc Openoffice: данные->сортировать->выбираем столбец и пункт «по убыванию»), мы получим список всех фраз, отсортированный по частоте внутри каждого обобщенного блока, пример ниже:
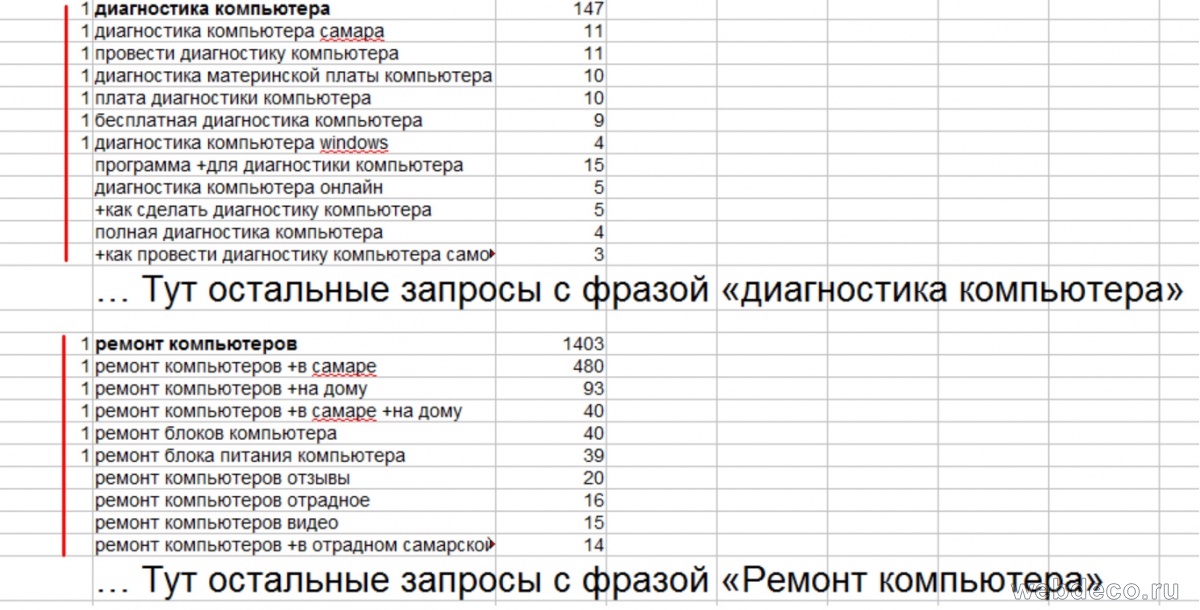
После того как все смысловые блоки будут отсортированы, очень удобно переместить ненужные фразы на отдельный лист.
3. Перемещаем ненужные запросы, но не удаляем т. к. они нам еще понадобятся для составления минус фраз. Удобнее всего в exel создать отдельную вкладку ненужных фраз и переместить туда все ненужные запросы, которые мы не отметили единицей. Для удобства также сохраняем структуру обобщенных блоков. Получится примерно такой список ненужных фраз в отдельной вкладке.
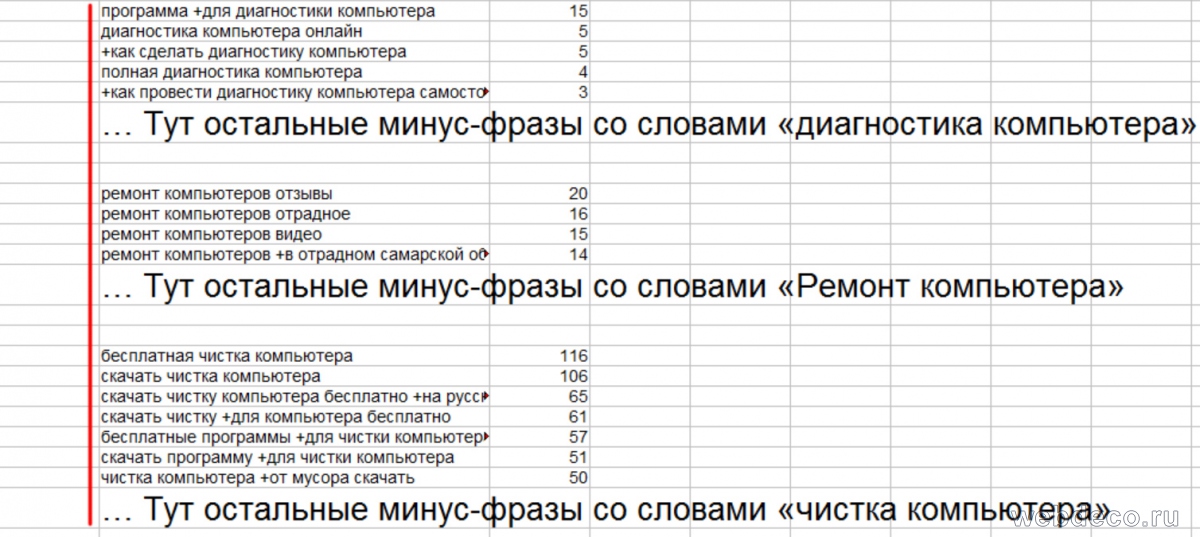
К этому списку мы вернемся на 7 этапе, а пока переходим к списку ключевых запросов
4. Получаем итоговый список ключевиков. После перемещения всех ненужных фраз остается только подчистить список, удалив те из них, которые редко запрашивают.
Если фразу запрашивают мало, то нет смысла по ней продвигаться, т. к. Яндекс директ отключает рекламу по таким запросам и присваивает статус «мало показов» в личном кабинете. Можно ограничиться фразами с частотностью 10, т. е. удалить запросы, у которых количество показов меньше 10 в месяц в выбранном регионе(ах).
У вас может возникнуть вопрос: «Зачем же мы ранее копировали фразы с частотностью менее 10 показов в месяц?». Ответ: «Для минус-фраз», т. к. для их сбора нужно пройти хотя бы 5-10 страниц в wordstat.yandex.ru и скопировать содержимое всей левой колонки независимо от количества показов в течение месяца, это важно. Поэтому удалить малозапрашиваемые ключевики можно только на этом этапе. После удаления фраз с показами менее 10 в месяц – получим наше семантическое ядро, оно будет выглядить примерно следующим образом:
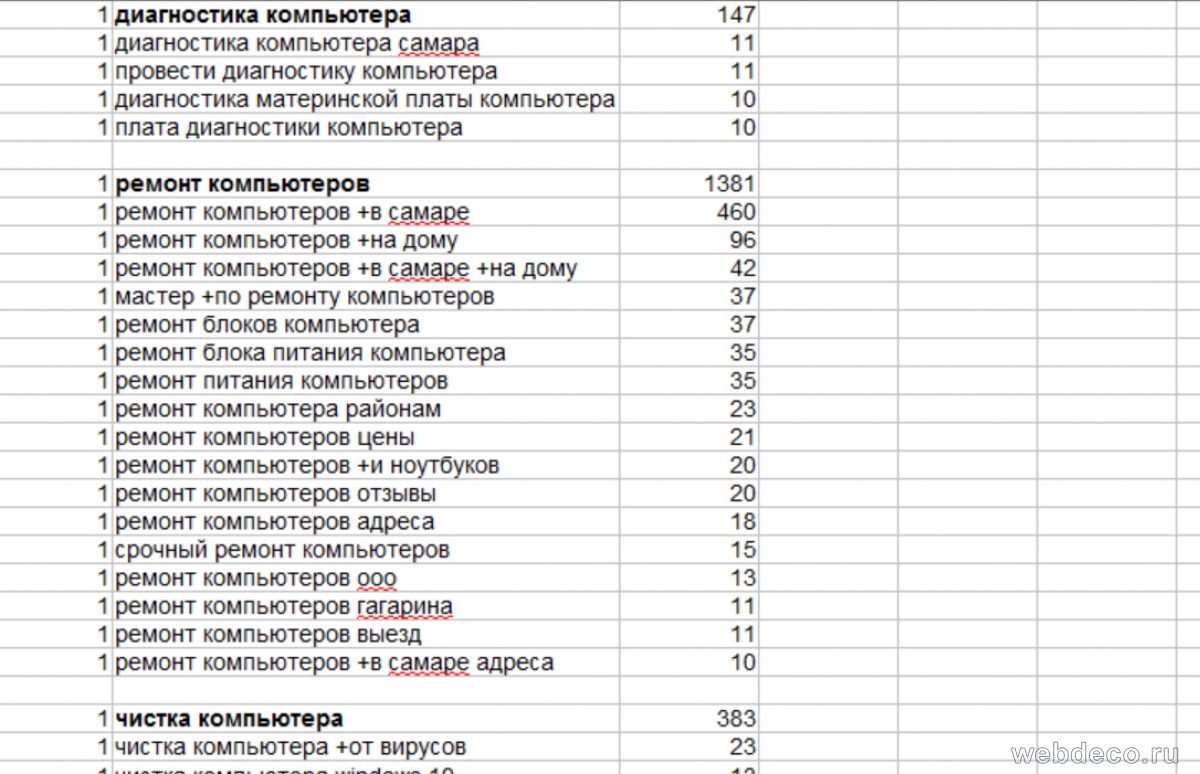
7 Этап. Список минус-слов
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
Список минус-слов содержит перечень фраз, при наборе, которых ваше объявление показываться не будет.
Например, мы составили объявление с ключевой фразой «диагностика ноутбука» и в списке минус-слов указали «самостоятельно». Это означает, что при наборе «диагностика ноутбука самостоятельно» объявление показываться не будет. А при наборе «диагностика ноутбука цена» будет показываться, т. к. «цена» не указано в минус-словах.
Благодаря указанию минус-фраз вы можете сэкономить около 50% бюджета, получив ту же отдачу от рекламы за счет того, что не будет кликов от незаинтересованных пользователей и уменьшится цена клика в объявлении(при повышении CTR).
Итак, у нас имеется составленный список ненужных фраз, именно из него мы и получим минус фразы.
7.1 Как получить минус-слова из списка
1 способ – ручной
Вручную выписываете в соседнюю колонку минус-фразу или минус-слова. Если внутри тематической группы минус-фразы повторяются – пишите только один раз, а остальные поля оставляйте пустыми.
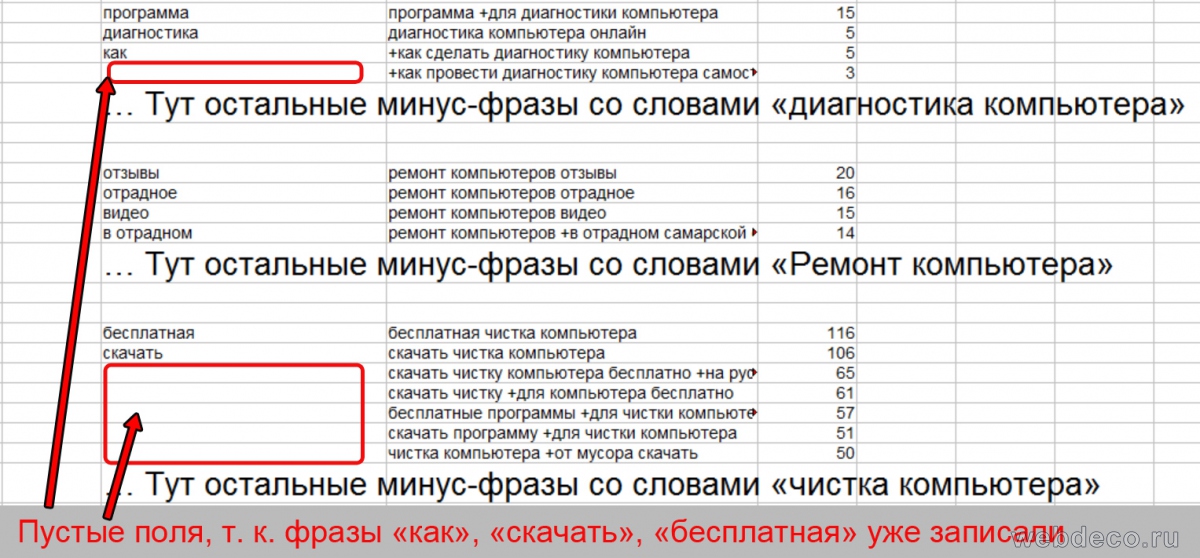
2 способ – полуавтоматический
Если фраз много, например, более чем 100, то можно немного автоматизировать этот процесс. Если из указанных строк мы удалим предлоги и ключевые слова – останутся только нужные нам минус фразы. Причем эту процедуру можно сделать с помощью массового удаления.
В программе Calc (Open office) жмем Ctrl+F(или Правка->Найти и заменить). В поле «Найти» пишем нашу ключевую фразу, например «ремонт компьютеров», поле «заменить на» оставляем пустым и жмем «заменить все». В итоге мы заменили указанное словосочетание на пустое поле, т. е. удалили, таким образом, мы сможем удалить все ненужное и получить список минус фраз.
Конечно, придется сделать несколько десятков замен, чтобы удалить предлоги и ключевые фразы с разными окончаниями. Но если у вас большой список, то данный метод сэкономит время. После массовой замены останутся некоторые фразы, которые нужно будет пройти вручную, но это уже будет небольшая часть. Подчистив список вручную, получим примерно следующий перечень.

7.2 Удаление дублей минус-слов из списка
Много минус фраз могут дублироваться, вследствие придется тратить время на просмотр таких строк. Если список небольшой, то дубли не являются большой проблемой, т. к. их можно вручную удалить, но если список больше 100 фраз, удобнее автоматизировать процесс удаления дублей несколькими кликами.
Удалить все дубли, встроенной функцией «Без повторений» к сожалению, не получиться т. к. одинаковые минус-фразы могут находиться внутри разных запросов. Поэтому рассмотрим более эффективный метод в данном случае.
1 шаг. Удаление дублей общих минус фраз
Если данную минус фразу можно использовать для всех объявлений, то выполняем этот пункт, в другом случае переходите к шагу 2. Например, минус-слово «как» можно использовать для всех запросов, чтобы отсечь нецелевых клиентов, которые хотели бы почитать статью, а не обратиться за услугой. Например, не показываться по фразам «как починить экран» и т. п.
Но если ваша минус фраза не подходит для всех запросов, то переходите к шагу 2. Например, для запроса «бесплатный ремонт компьютера» – «бесплатный» будет минус-словом, т. к. компания не предоставляет услуги даром. А для запроса «бесплатная диагностика компьютера», «бесплатная» уже не всегда будет минус-словом, т. к. многие организации делают бесплатную диагностику неисправности, а сам ремонт уже платно. Поэтому слово «бесплатный» нужно указывать только для части объявлений.
Итак, если вы можете указать данное минус-слово для всех запросов то делаем следующее:
После того как вы выписали минус-фразу в левой колонке на этапе 7.1, вам нужно выделить все строки в таблице, где она есть, кроме самой первой и удалить, чтобы не писать их вновь. В программе Calc (Open office) жмем Ctrl+F(или Правка->Найти и заменить). В поле «Найти» пишем нашу минус-фразу, например, слово «скачать» и жмем «найти все».
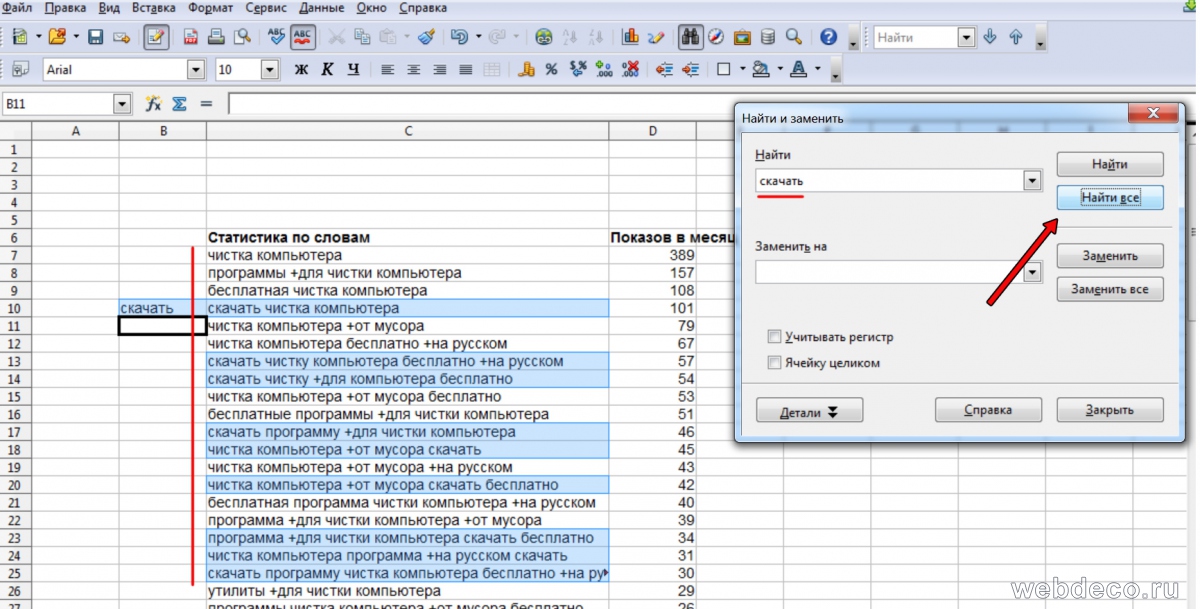
Вы выделили все поля, где есть заданная минус-фраза. Теперь нужно снять выделение с самого первого поля, а остальные строки удалить. Для этого нажимаем и удерживаем кнопку «CTRL» и кликаем левой кнопкой мыши по верхнему полю, чтобы удалить все значения кроме первого. Теперь кликаем на правую кнопку мыши по выделенной части и выбираем пункт «Удалить ячейки»(или в меню сверху «Правка» —> «Удалить ячейки»). В итоге выделенные строки удаляться и нам не нужно будет тратить время на просмотр этих фраз.
Как вы понимаете, такое массовое удаление строк подойдет только для случая, когда для всех запросов можно указать эту минус-фразу.
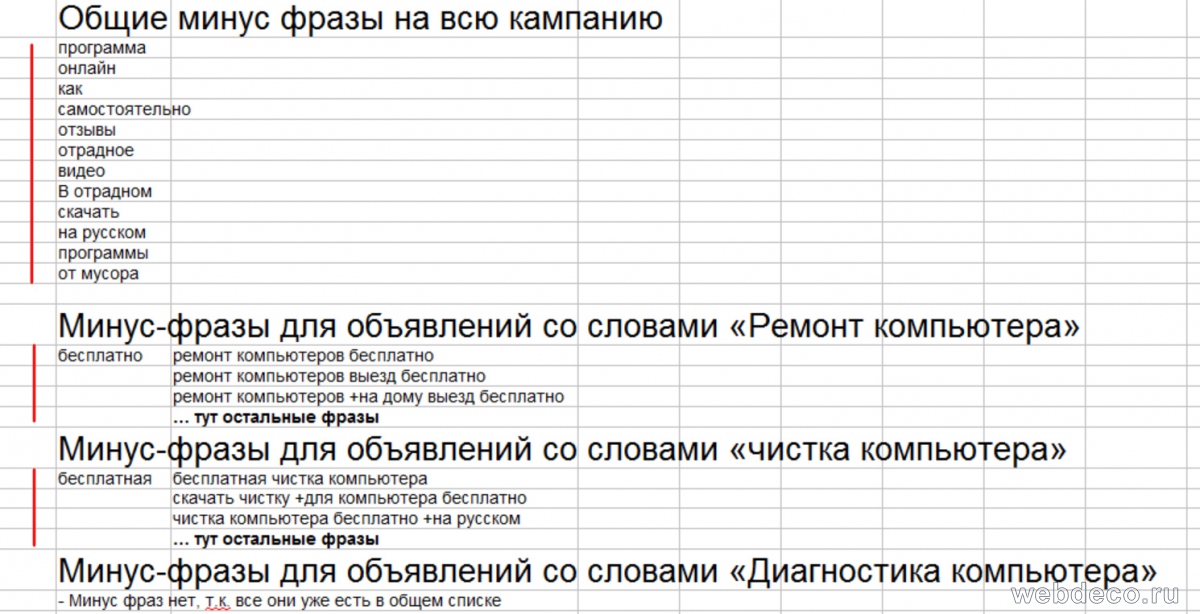
Вам нужно найти все общие минус фразы и переместить их в отдельный список с удалением дубликатов. Если минус фраза не является общей, то ничего не делайте, как с ними работать мы рассмотрим на следующем шаге. Сначала подготовьте список всех общих минус фраз. Получится примерно так:
2 шаг. Удаление дублей индивидуальных минус фраз
На данном шаге мы удалим дубли минус фраз внутри каждого тематического блока. В нашем примере было 3 обобщенных блока: «Диагностика компьютера», «Ремонт компьютера», «Чистка компьютера», соответственно если минус фразу нельзя отнести к общей, нам нужно удалить дубли внутри каждого блока.
Например, слово «бесплатно» в запросе «Диагностика компьютера бесплатно» не всегда будет минус словом, т. к. многие компании действительно не берут денег за диагностику и это словосочетание будет целевым. Поэтому минус-фразу «Бесплатно» нужно оставить только для некоторых блоков запросов, где она является нежелательной, а именно для блоков «Ремонт компьютера», «чистка компьютера» в нашем случае.
Если блок небольшой, например, до 20 фраз, то быстрее будет удалить дубли вручную. В другом случае выделяйте область искомого блока, где нужно удалить дубли, затем в программе Calc(Open office) нажимаем Ctrl+F(или Правка->Найти и заменить), потом в графе «Найти» пишем минус-фразу, нажимаем «Детали» и ставим галочку «Только текущее выделение» и кликаем «найти все». Если галочку не поставить, то поиск будет по всему листу, а не по выделенной области.
Произойдет выделение всех строк, где содержится искомая фраза, теперь нам нужно будет удалить строки, где она дублируется. Снимаем выделение с самой первой, чтобы ее тоже не удалить. Для этого нажимаем и удерживаем на клавиатуре кнопку «CTRL» и кликаем по самому первому значению, чтобы снять с него выделение.
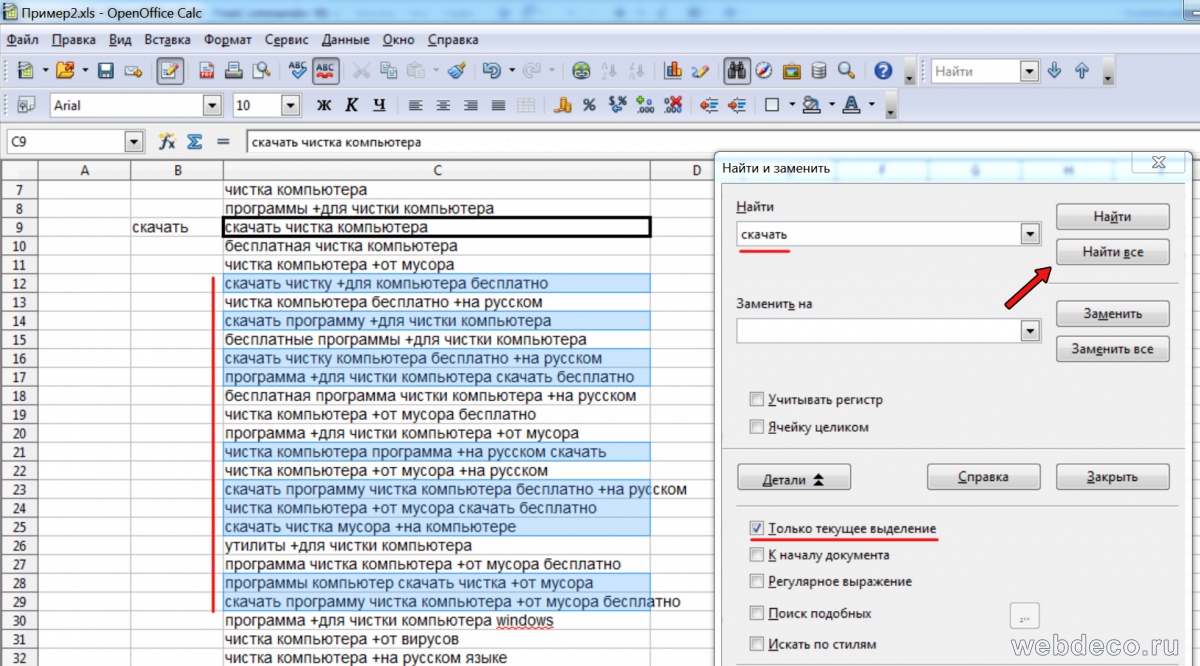
Теперь нажимаем на правую кнопку по выделенной части и выбираем «Удалить ячейки»(или в меню сверху «Правка» —> «Удалить ячейки»). В результате удалим все строки содержащие дубли минус фраз.
В итоге у нас должен быть один общий список минус-слов и индивидуальные для отдельных групп фраз.
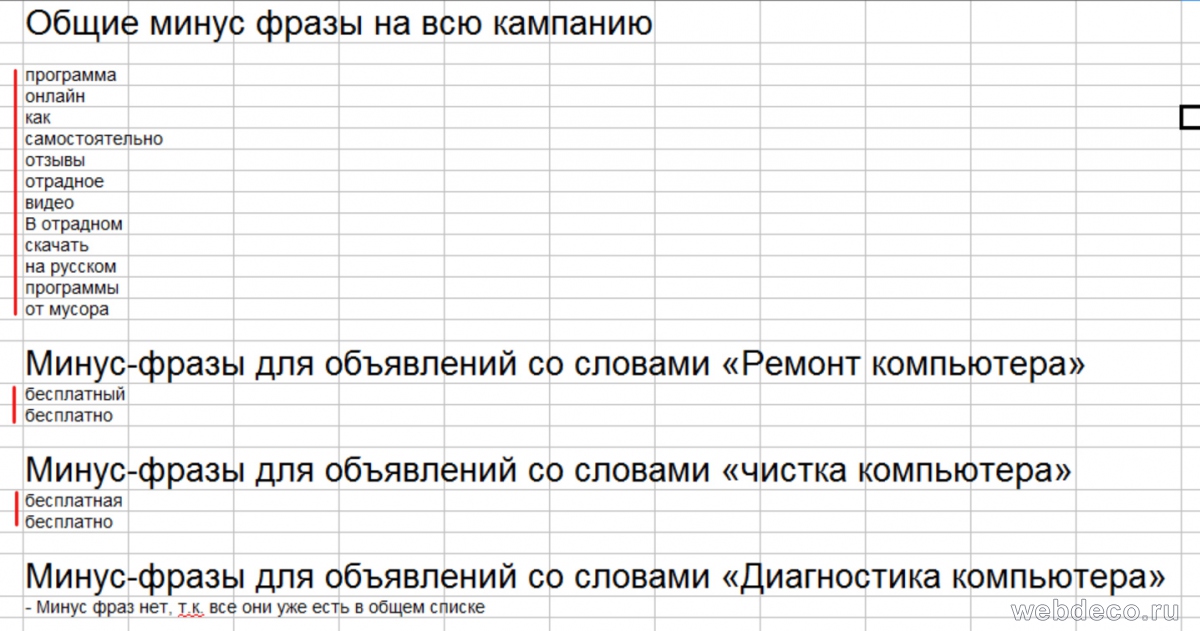
В данном списке только 2 фразы являются индивидуальными: «бесплатно», «бесплатная» и относятся ко всем запросам, в которых нет слова «диагностика». Остальные минус фразы являются общими, т. е. применимы, ко всем запросам.
8 Этап. Оценка спроса
Автор: Марков Александр, интернет-маркетолог, веб мастер. Сайт: markov-m.ru
На 6 этапе мы получили вот такой итоговый список ключевых фраз
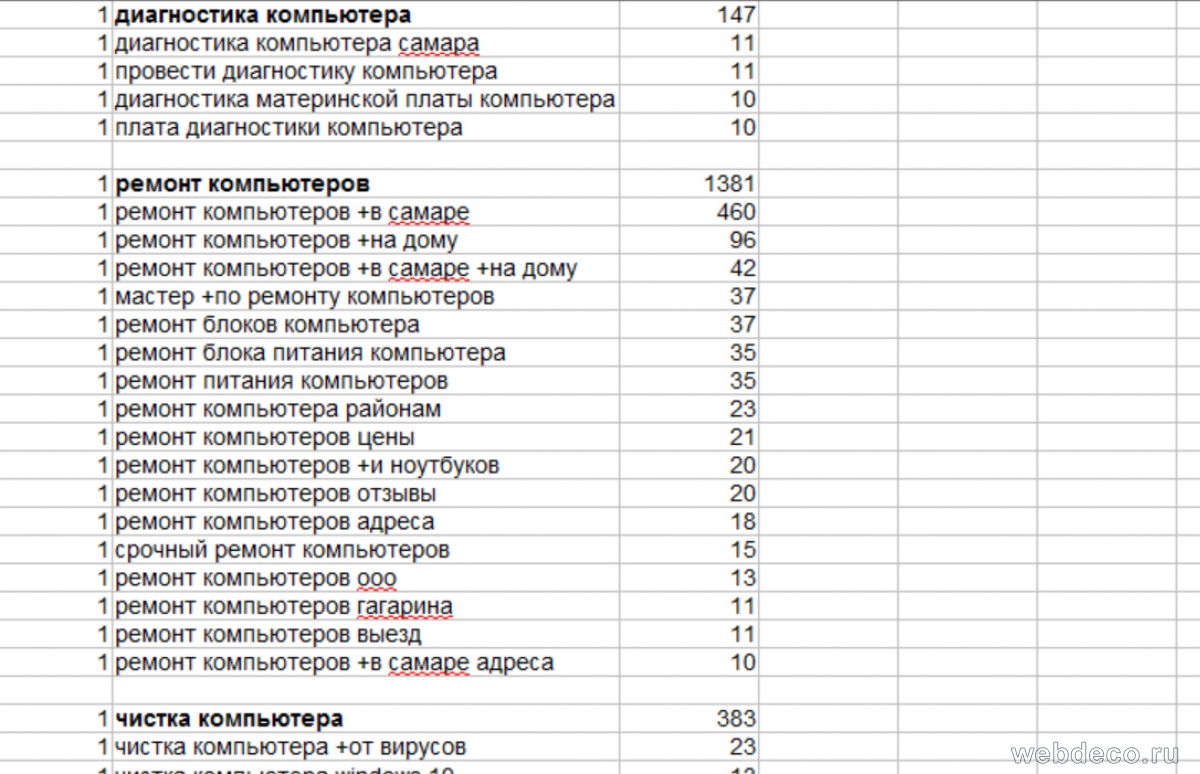
Это данные поисковика Яндекс, чтобы узнать статистку по другим поисковым системам – обратимся к рейтингу популярности. На момент написания статьи популярность поисковых систем была следующая: