
Data Science для карьериста
Эта книга поможет вам пройти путь становления в качестве специалиста по Data Science и построить карьеру. Мы хотим, чтобы вы получили все преимущества работы в этой сфере и избежали большинства подводных камней. Возможно, вы работаете в смежной области вроде маркетинговой аналитики и подумываете сменить сферу деятельности. Или, может быть, вы уже работаете дата-сайентистом, но ищете новое место работы и полагаете, что подошли к предыдущему процессу поиска недостаточно хорошо. Возможно, вы хотите продолжить карьеру, выступая на конференциях, участвуя в разработке open source, или же стать независимым консультантом. Мы уверены, что, каким бы ни был ваш нынешний уровень, эта книга окажется вам полезной.
В первых четырех главах мы описали, как можно начать путь в Data Science и создать портфолио: так мы попытались решить парадокс, когда опыт можно получить только при изначальном владении практическими навыками. В части 2 мы покажем, как составить сопроводительное письмо и резюме, с которыми вас точно пригласят на собеседование, и расскажем, как создать сеть контактов для получения рекомендации. Мы также рассмотрим стратегии переговоров, которые, как показывают исследования, позволят вам получить наилучшие условия оффера.
Как дата-сайентисту вам необходимо будет разрабатывать методы анализа, взаимодействовать со стейкхолдерами и, возможно, даже участвовать в развертывании модели в производство. Часть 3 поможет понять, как устроены все эти процессы и как можно самому настроиться на успех. В части 4 вы найдете стратегии, которые помогут вам собраться с силами в тех неизбежных случаях, когда ваш проект терпит крах. А когда вы будете готовы, мы поможем вам решить, как продолжать свою карьеру – стать менеджером, остаться исполнителем или даже стать независимым консультантом.
Однако прежде, чем начать этот путь, вы должны разобраться в том, кто такие дата-сайентисты и какую работу они выполняют. Data Science – это очень широкое поле деятельности, которое включает в себя много направлений, и чем лучше вы понимаете разницу между ними, тем успешнее вы сможете в них развиваться.
1.1. Что такое Data Science?
Data Science (DS) – это практика использования данных, с помощью которой можно попытаться понять и решить реальные задачи. Эта концепция не нова; люди анализируют объемы и тенденции продаж с тех пор, как изобрели ноль. Однако за последнее десятилетие нам стало доступно экспоненциально большее количество данных, чем прежде. Появление компьютеров помогло генерировать их, и только путем машинных вычислений можно обрабатывать так много информации. С помощью компьютерного кода дата-сайентист может преобразовывать или накапливать данные, проводить статистический анализ или тренировать модели машинного обучения (МО). В результате могут быть созданы отчет, информационная панель или модель МО, которую можно будет запустить в непрерывную работу.
Например, если розничная компания не может определиться с местом для нового магазина, она может пригласить дата-сайентиста для проведения соответствующего анализа. Он соберет статистические данные об адресах доставки онлайн-заказов, чтобы понять, где находится потребительский спрос. Специалист также может совмещать выводы о местонахождении клиентов с информацией о демографической ситуации и доходах в этих местах на основании данных переписи населения. С помощью этих датасетов можно найти оптимальное место для нового магазина и создать презентацию Microsoft PowerPoint, чтобы представить рекомендации вице-президенту компании по коммерческой деятельности.
В другой ситуации та же розничная компания захочет увеличить объем онлайн-заказов с помощью персональных рекомендаций во время шоппинга. Дата-сайентист может загрузить статистику прежних онлайн-заказов и создать модель машинного обучения, которая будет учитывать набор товаров в корзине покупателя и на его основании прогнозировать, что еще ему можно предложить. После этого он будет работать с командой инженеров компании, чтобы каждый раз, когда клиент совершает покупки, новая модель МО показывала рекомендуемые товары.
При попытке освоить сферу DS многие люди сталкиваются с одной проблемой: слишком уж много нужно изучить. Например, программирование (но какой язык?), статистику (но какие методы наиболее важны на практике, а какие в основном академические?), машинное обучение (но чем оно отличается от статистики или ИИ?) и предметную область в той отрасли, в которой они хотят работать (но что, если вы не знаете, где хотите работать?). Кроме того, им необходимо овладеть бизнес-навыками вроде эффективной презентации результатов всем, начиная с других дата-сайентистов и заканчивая генеральным директором. А от вакансий, в которых требуется степень кандидата наук, многолетний опыт работы в Data Science и знание обширного перечня статистических и программных методов, становится только хуже. Как можно приобрести все эти навыки? С чего лучше начать? Что входит в базу?
Если вы изучали различные области DS, возможно, вы знакомы с популярной диаграммой Венна, составленной Дрю Конвеем. По мнению Конвея (на момент создания диаграммы), Data Science находится на пересечении математики и статистики, знаний предметной области и навыков хакинга (то есть программирования). Это изображение часто берется за основу для определения того, кто такой специалист по работе с данными. На наш взгляд, компоненты науки о данных немного отличаются от того, что предложил Дрю Конвей (рис. 1.1).
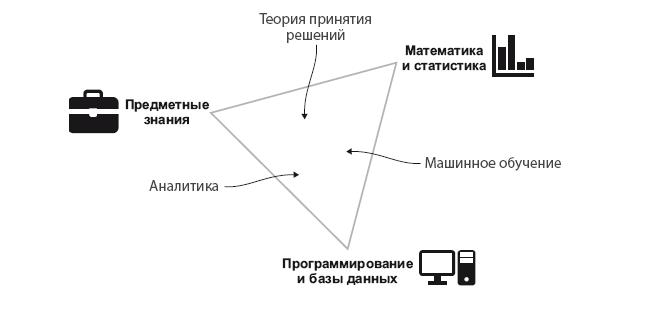
Рис. 1.1. Навыки, которые объединяются в DS, и то, как они сочетаются для выполнения разных функций
Мы изменили исходную диаграмму Венна, составленную Конвеем, на треугольник, потому что дело не в том, есть ли у вас навык или нет, а в том, что вы можете развить его лучше, чем другие специалисты. Действительно, все три навыка являются фундаментальными и вам необходимо владеть каждым в определенной степени, но вам не обязательно быть экспертом во всех. Мы поместили в треугольник разные типы специальностей в сфере Data Science. Они не всегда однозначно соответствуют названиям должностей, а даже если и так, то в разных компаниях их названия могут отличаться. Итак, что означает каждый из этих компонентов?
1.1.1. Математика/статистика
На начальном уровне математика и статистика являются базой в работе с данными. Мы разделяем эту базу на три уровня знания:
• Существование методов. Если вы не знаете о какой-либо возможности, вы не можете ее использовать. Если дата-сайентисту нужно сгруппировать похожих клиентов, знание того, что это можно сделать статистическим методом (с помощью кластерного анализа), станет первым шагом.
• Как применять методы. Специалист по работе с данными должен не просто знать много методов – он должен различать нюансы их применения. Важно писать такой код, где они не только применяются, но и настраиваются. Если дата-сайентист хочет использовать кластеризацию методом k-средних, чтобы сгруппировать покупателей, он должен уметь делать это на языке программирования типа R или Python. Также он должен понимать, как настроить параметры метода, например как выбрать количество создаваемых групп.
• Как выбрать подходящий метод. В DS используется огромное количество методов, поэтому для дата-сайентиста важно быстро оценить, какой из них будет самым эффективным в каждом случае. В нашем примере с группировкой покупателей, даже если специалист сосредоточился на кластеризации, он может применять десятки различных методов и алгоритмов. Вместо того чтобы перебирать все доступные методы, он должен сразу отбросить бо́льшую их часть и сосредоточиться всего на нескольких.
Эти типы навыков постоянно применяются в задачах по работе с данными. Приведем другой пример. Предположим, вы работаете в компании, занимающейся e-commerce. Ваш бизнес-партнер может поинтересоваться, в каких странах у вас самый большой средний чек. Это очень простой вопрос, если у вас есть готовые данные. Но вместо того, чтобы просто предоставить информацию и позволить партнеру делать выводы самостоятельно, вы можете копнуть глубже. Если у вас есть один заказ из страны А на $100 и тысяча заказов из страны Б средней стоимостью $75, то формально в стране А средний чек выше. Но можете ли вы с уверенностью сказать, что ваш бизнес-партнер должен вложиться в рекламу в стране А, чтобы увеличить количество заказов? Вряд ли. У вас есть только одна единица данных из этой страны, и она может оказаться статистически незначимой. А вот если бы у вас было 500 заказов из страны А, можно было бы протестировать разницу в стоимости заказов. Это значит, что, если бы эти показатели для стран А и Б действительно не различались, вы бы не получили прежний результат. В этом длинном примере дается оценка того, какие подходы были разумными, что следует учитывать и какие результаты были признаны несущественными.
1.1.2. Базы данных и программирование
Программирование и базы данных (БД) основываются на извлечении информации из БД компаний и написании чистого, эффективного, легко настраиваемого кода. Эти навыки во многом схожи с тем, что должен знать разработчик программного обеспечения. Вот только дата-сайентисты должны писать код, который выполняет анализ с неизвестным итогом, а не выдает заранее заданный результат. Стек данных каждой компании уникален, поэтому какой-то определенный набор технических знаний специалисту не нужен. В целом вам нужно уметь получать данные из базы, очищать их, обрабатывать, обобщать, визуализировать и обмениваться ими.
R и Python – основные языки программирования для большинства профессий DS. R берет свое начало в статистике и, как правило, лучше всего подходит для статистического анализа, моделирования, визуализации и составления отчетов. Python создавался как язык для разработки программного обеспечения и в дальнейшем приобрел огромную популярность в обработке данных. Python лучше R справляется с обработкой больших датасетов, проводит машинное обучение и поддерживает алгоритмы, работающие в реальном времени (например, модули рекомендаций в Amazon). Но благодаря вкладу многих участников возможности двух языков сейчас почти равны. Специалисты по работе с данными успешно используют R для создания моделей машинного обучения, запускаемых миллионы раз в неделю, а также делают чистый, презентабельный статистический анализ на Python.
R и Python наиболее популярны для обработки данных по нескольким причинам:
• Они бесплатны, и у них открытый исходный код. Это означает, что он создается многими участниками, а не одной определенной компанией или группой пользователей. В этих языках есть много пакетов, или библиотек (готовых блоков кода), которые можно использовать для сбора данных, их обработки, визуализации, статистического анализа и машинного обучения.
• Благодаря большому количеству пользователей каждого из этих языков дата-сайентистам легко найти помощь при возникновении проблем. И хотя в каких-то компаниях до сих пор используют SAS, SPSS, STATA, MATLAB или другие платные приложения, многие из них начинают переходить в своей работе на R или Python.
Хотя бо́льшая часть анализа при обработке данных осуществляется на R или Python, часто приходится извлекать информацию из БД, и здесь на сцену выходит язык SQL. SQL – это язык программирования, который используется в большинстве БД для внутренней обработки данных и извлечения их из базы. Представим для примера дата-сайентиста, которому нужно проанализировать сотни миллионов записей о заказах клиентов компании и спрогнозировать, как со временем будет изменяться ежедневное количество заказов. Для начала он, скорее всего, напишет SQL-запрос для получения количества заказов за каждый день, после чего возьмет полученные данные и запустит статистический прогноз на R или Python. По этой причине SQL очень популярен в Data Science, и без знания этого языка вы далеко не продвинетесь.
Можно ли стать дата-сайентистом без программирования?
С данными можно успешно проделывать много вещей, используя только Excel, Tableau или другие BI-инструменты с графическими интерфейсами. Хотя код в них не пишется, часто заявляется, что этот софт так же функционален, как и программирование на R или Python. На самом деле многие дата-сайентисты действительно порой пользуются этими программами. Но могут ли они быть исчерпывающим набором инструментов? Мы говорим «нет». В реальности компаний, где DS-командам не приходится писать код, очень мало. Но даже если вам повезет оказаться в одной из них, у программирования все же есть ряд плюсов.
Первое преимущество программирования – воспроизводимость. Когда вы пишете код, а не пользуетесь программным обеспечением типа point-and-click, можно повторно запускать его при изменении данных хоть каждый день, хоть через полгода. Это преимущество также связано с контролем версий: вместо того чтобы переименовывать файл каждый раз при изменении кода, можно сохранить один файл и видеть всю его историю.
Второе преимущество – гибкость. Например, если в Tableau нет нужного вам типа графа, вы не сможете его создать. Но с помощью программирования можно написать собственный код, чтобы сделать то, о чем создатели и разработчики программных средств никогда даже не думали.
Третье и последнее преимущество языков с открытым исходным кодом, таких как Python и R, – это вклад в сообщество. Тысячи людей создают пакеты и публикуют их в открытом доступе на GitHub и/или CRAN (для R) и pip (для Python). Этот код можно скачать и использовать для решения своих задач. Так вы не зависите от числа функций, предлагаемых одной компанией или группой людей.
Другой ключевой навык – использование контроля версий для отслеживания изменений кода. Он позволяет организовать хранение файлов, выполнять откат до предыдущих версий и видеть, кто, когда и какие изменения вносил в файл. Этот навык чрезвычайно важен в Data Science и в разработке программного обеспечения. Например, если кто-то случайно изменил файл и испортил ваш код, вы можете восстановить его или посмотреть, что изменилось.
Безусловно, наиболее популярная система для контроля версий – это Git. Он часто используется вместе с GitHub, веб-службой хостинга для Git. Git позволяет сохранять (фиксировать) вносимые изменения, а также видеть всю историю проекта и то, как она менялась с каждой фиксацией. Если два человека по отдельности работают над одним и тем же файлом, Git гарантирует, что чья-либо работа не будет случайно удалена или перезаписана. Если вы захотите поделиться своим кодом или запустить что-то в производство, во многих компаниях вам обязательно потребуется Git, особенно если это компания с сильной командой проектировщиков.
1.1.3. Понимание бизнеса
Любая достаточно развитая технология неотличима от магии.
Артур Чарльз КларкУ компаний, мягко говоря, разное понимание того, как работает Data Science. Часто руководство просто хочет решить определенную задачу и обращается к своим волшебникам DS. Основной навык, необходимый в Data Science, – это умение преобразовать бизнес-ситуацию в вопрос о данных, найти ответ на их основе и предоставить бизнес-решение. Бизнесмен может спросить: «Почему наши клиенты уходят?» Но у Python нет импортируемого пакета «почему уходят клиенты» – вы сами должны понять, как ответить на этот вопрос с помощью данных.
Понимание бизнеса – это та грань, где ваши идеальные представления о Data Science встречаются с условиями реального мира. Недостаточно просто запросить информацию, не зная, как данные хранятся и обновляются в конкретной компании. Если компания предоставляет услуги по подписке, то где хранятся данные? Что произойдет, если кто-то изменит свою подписку? Обновляется ли строка этого пользователя или в таблицу добавляется еще одна? Нужно ли вам исправить какие-либо ошибки или несоответствия в данных? Если вы не знаете всего этого, вы не сможете дать точный ответ на такой простой вопрос, как: «Сколько у нас было подписчиков на 2 марта 2019 года?»
Понимание бизнеса также помогает задавать правильные вопросы. Когда стейкхолдер спрашивает вас, что делать дальше, вероятно, он имеет в виду: «Почему у нас нет больше денег?» Для ответа приходится задавать встречные вопросы. Если вы понимаете основной бизнес (а также вовлеченных лиц), то лучше разбираетесь в ситуации. Вы можете спросить в ответ, по какой линейке продуктов нужны рекомендации, или что-то вроде: «Хотели бы вы видеть большее участие определенного сектора нашей аудитории?»
Исчезнет ли Data Science?
В основе вопроса о том, что будет с Data Science через пару десятилетий, лежат две основные проблемы: автоматизация и перенасыщение рынка труда.
Некоторые этапы процесса обработки данных действительно можно автоматизировать. Автоматическое машинное обучение (AutoML) может сравнивать производительность различных моделей и выполнять определенные части подготовки данных (например, масштабирование переменных). Но эти задачи – лишь малая часть большого процесса. Например, данные часто нужно создавать самостоятельно, поскольку идеально чистыми они бывают очень редко. При этом нужно взаимодействовать с другими людьми, например с UX-специалистами или с инженерами, которые будут проводить опрос или регистрировать действия пользователей.
Что касается пузыря на рынке труда, то хорошим сравнением может послужить разработка программного обеспечения в 1980-х годах. По мере того как компьютеры становились дешевле, быстрее и популярнее, возникали опасения, что вскоре эти машины смогут выполнять все и программисты перестанут быть востребованными. Но все произошло ровно наоборот, и теперь в США работает более 1,2 миллиона разработчиков ПО (http://mng.bz/MOPo). Несмотря на исчезновение таких профессий, как веб-мастер, над разработкой, обслуживанием и улучшением веб-сайтов работает больше людей, чем когда-либо.
Мы полагаем, что в Data Science появится больше специализаций, что может привести к исчезновению самого понятия «дата-сайентист». Но многие компании все еще находятся на ранних стадиях изучения того, как использовать науку о данных, и им предстоит еще много работы в этом направлении.
Другая часть понимания бизнеса – это развитие общих бизнес-навыков вроде умения адаптировать презентации и отчеты для разных аудиторий. Иногда вы будете обсуждать лучшую методологию с кандидатами наук по статистике, а иногда вы будете выступать перед вице-президентом, который не занимался математикой уже 20 лет. Вам нужно донести информацию до слушателей, учитывая их особенности.
Наконец, по мере карьерного роста вы научитесь определять, в каких случаях Data Science может помочь бизнесу. Если вы хотели создать систему прогнозирования, а руководство не поддержало эту идею, можно самому стать частью руководства и решить этот вопрос. Старший дата-сайентист будет искать способы внедрения машинного обучения, так как знает его возможности и ограничения, а также то, какие виды задач выиграют от автоматизации.
1.2. Различные типы вакансий в Data Science
Комбинировать три основных навыка, необходимых в Data Science (и описанных в разделе 1.1), можно на разных по сути должностях. С нашей точки зрения, эти навыки объединяются тремя основными параметрами: аналитикой, машинным обучением и наукой о принятии решений. Каждая из этих областей служит разным целям компании и дает принципиально разные результаты.
При поиске вакансий в сфере Data Science следует меньше обращать внимание на названия должностей – лучше сконцентрируйтесь на описании обязанностей и на вопросах во время собеседования. Посмотрите на опыт работы людей, занимающихся наукой о данных, например какие должности они раньше занимали и на кого учились. Вы можете обнаружить, что должности людей, которые выполняют схожие функции, называются совершенно по-разному, и наоборот, под одним и тем же названием должности «дата-сайентист» может подразумеваться совершенно разная работа. В этой книге мы поговорим о различных типах вакансий, но помните, что названия в разных компаниях могут отличаться.
1.2.1. Аналитики
Аналитик берет данные и передает их нужным людям. После того как компания установит цели на год, их можно поместить на информационную панель, чтобы руководство могло отслеживать прогресс каждую неделю. Можно также встроить функции, которые позволят менеджерам легко разбивать значения по странам или типам продуктов. Эта работа включает в себя много очистки и подготовки данных и, как правило, меньше работы по их интерпретации. Специалист должен уметь находить и устранять проблемы с качеством данных, однако основные решение по ним принимает бизнес-партнер. Таким образом, задача аналитика – взять данные внутри компании, отформатировать, упорядочить и передать их другим специалистам.
Поскольку должность аналитика не связана со статистикой и машинным обучением, некоторые люди и компании считают, что она выходит за рамки Data Science. Однако для большей части работы вроде создания осмысленных визуализаций и принятия решений о конкретных преобразованиях требуются те же навыки, которые нужны и другим специалистам DS. Например, аналитика могут попросить cоздать автоматизированную информационную панель, которая показывает изменение количества подписчиков и позволяет фильтровать данные только по подписчикам определенных продуктов или в определенных географических регионах. Он должен будет найти соответствующие данные в компании, выяснить, как их преобразовать (например, изменив их с ежедневных на еженедельные новые подписки), а затем создать содержательный набор информационных панелей с удобным интерфейсом и ежедневным автоматическим обновлением без ошибок.
Короткое правило: аналитик создает информационные панели и отчеты на основе данных.
1.2.2. Машинное обучение
Инженер по машинному обучению разрабатывает модели МО и разворачивает их в производство для постоянной работы. Такой специалист может оптимизировать алгоритм ранжирования для результатов поиска на сайте интернет-торговли, создать систему рекомендаций или отслеживать модель в производстве, чтобы убедиться, что ее производительность не снизилась с момента запуска. Инженер по машинному обучению уделяет меньше времени таким вещам, как создание визуализаций для убеждения других людей в чем-то, и больше сосредоточен на программировании для анализа данных.
Существенное различие между этой ролью и другими заключается в том, что результаты работы в первую очередь предназначены для машин. Например, вы можете создавать модели МО, которые превращаются в интерфейсы прикладного программирования (API) для других устройств. Во многих отношениях вы будете ближе к разработчику программного обеспечения, чем к другим специалистам Data Science. Любому дата-сайентисту полезно следовать передовым методам программирования, а вы как инженер по машинному обучению просто обязаны это делать. Ваш код должен быть производительным, протестированным и написанным так, чтобы другие люди могли с ним работать. Поэтому многие инженеры по машинному обучению имеют опыт работы в области информатики.
Инженера по машинному обучению могут попросить создать модель МО, которая может в реальном времени прогнозировать вероятность оформления онлайн-заказа. Он должен будет найти архивные данные в компании, обучить на них модель МО, преобразовать ее в API, а затем развернуть API, чтобы веб-сайт мог запускать модель. Если по какой-либо причине эта модель перестанет работать, для решения проблемы пригласят инженера по машинному обучению.
Короткое правило: инженер по машинному обучению создает модели, которые работают непрерывно.
1.2.3. Теория принятия решений
Специалист по принятию решений превращает необработанные данные компании в информацию, которая помогает руководству определяться с дальнейшими действиями. Для этой работы нужно хорошо владеть различными математическими и статистическими методами и процессами принятия бизнес-решений. Кроме того, специалисты по принятию решений должны уметь создавать убедительные визуализации и таблицы, чтобы люди, не имеющие технических знаний, понимали их анализ. Хотя они много программируют, обычно их код одноразовый – он нужен только для конкретного анализа. Поэтому неэффективный или сложный в поддержке код просто сходит им с рук.
Специалист по принятию решений должен понимать потребности других людей в компании и находить способы выдавать нужную информацию. Например, директор по маркетингу может попросить его помочь определить, какие типы продуктов следует выделить в праздничном каталоге компании. Специалист по принятию решений может исследовать, какие продукты хорошо продавались и без каталога, договориться с командой по user research о проведении опроса и использовать принципы поведенческой психологии, чтобы провести анализ и предложить подходящие варианты. Результатом, скорее всего, будет презентация или отчет PowerPoint, который будет представлен продакт-менеджерам, вице-президентам и другим бизнесменам.