
Самоучитель. Курс SQL. Базы данных. ORACLE
На третьем шаге выбираем «Use Virtual Account» и также нажимаем «Next».
На шаге 4 необходимо сначала выбрать путь установки Oracle.

Сделать это можно кликом по верхней кнопке «Browse» («Обзор»). В открывшемся окне выбора пути установки Oracle нужно выбрать пустой каталог, который ты заранее создал (или можно создать папку непосредственно в окне выбора пути установки). Важно, чтобы полный путь до этой папки не содержал символов кириллицы, спецсимволов и пробелов. Полный путь установки может быть таким: «D:\ORCL» или «C:\ORACLE», или, например, «D:\OracleBase». Путь установки ORACLE не может быть вида: «D:\Новая папка».
Когда мы выберем путь установки СУБД Oracle в верхней строке, путь расположения непосредственно создаваемой базы данных в нижней строке изменится автоматически.
В выпадающем списке «Character set» («Набор символов») сейчас нужно выбрать «Unicode AL32UTF8».
В текстовом окне «Global database name» нужно указать имя базы данных. Можно назвать, например, «work», «study», «mybase» или оставить предлагаемое Ораклом значение по–умолчанию – «orcl».
Далее необходимо установить самый главный пароль системного пользователя ORACLE. Его нельзя забывать. Для нашей базы данных мы можем сейчас выбрать самый простой пароль, даже 123, и в поле «Confirm» еще раз его продублировать. Нажимаем «Next» и получаем сообщение, что пароль администратора ORACLE не соответствует рекомендациям ORACLE. Конечно, ведь он такой простой и короткий. Но мы работаем не с реальными данными какой–либо компании, а устанавливаем ORACLE для тренировок. Поэтому, простота пароля нас волновать не должна и Ораклу на вопрос о том, действительно ли мы хотим продолжить с таким легким паролем системного администратора, мы отвечаем «Yes».

На следующем шаге Oracle проверяет настройки операционной системы и оценивает производительность нашего компьютера (или ноутбука) и, если для комфортной работы СУБД будет каких–либо параметров недостаточно, то Oracle даст об этом знать. Например, может сообщить, что недостаточно оперативной памяти. В этом случае, в окне устанавливаем галочку «Ignore All» («Игнорировать все замечания») и нажимаем появившуюся кнопку «Next».
На этом, практически последнем шаге, Оракл показывает, что сейчас будет выполнено. Нажимаем заветную кнопку «Install» («Установить»).
Во время установки могут появиться дополнительные окна с запросом разрешений, например, от брандмауэра операционной системы. В появляющихся окнах нужно всегда нажимать «Разрешить».
Через некоторое время установка будет завершена. Поздравляю! Мы сделали первую одну из самых сложных задач по подготовке нашего собственного рабочего места – мы установили СУБД Oracle!
5.2. Установка программы SQL Developer и подключение к базе данных
Программа SQL Developer – стандартная программа производства фирмы Oracle для работы с базами данных СУБД Oracle. После установки этой программы, с помощью нее мы подключимся к нашей СУБД и зайдем на первую и единственную пока базу данных. Иными словами, с помощью нее мы будем видеть объекты базы данных, к которой подключились (например, таблицы), а также выполнять SQL запросы. Ввиду наличия всего нужного функционала и отсутствия дополнительной платы, эта программа стала одной из самых популярных для работы с базами данных Oracle. Примерно такой же популярностью пользуются и программы сторонних разработчиков, предназначенные для работы с Оракловыми базами данных: PL/SQL Developer и TOAD.
В последних версиях СУБД Oracle, программа SQL Developer не идет в комплекте поставки – ее нужно устанавливать дополнительно. Но, если ты устанавливаешь СУБД Oracle версию 12, то программа SQL Developer будет установлена автоматически. Ты можешь найти ее в меню «Пуск».
Итак, если ты установил Oracle новой версии, то, скорее всего, программа SQL Developer у тебя отсутствует. Ты можешь проверить это. Попробовать найти ее в меню Пуск. Отсутствует? Тогда устанавливаем ее дополнительно! Снова идем на сайт Oracle: https://www.oracle.com/tools/downloads/sqldev–downloads.html и выбираем программу для нашей операционной системы. Если у нас шестидесяти четырёх битная Windows 10, то и нажимаем на кнопку «Download» напротив нее. Снова соглашаемся с лицензионными соглашениями и загружаем архив с программой. Загрузив zip–архив, его осталось только распаковать в нужный каталог.
После распаковки архива с программой в удобный каталог, можно сразу запустить SQL Developer! При первом запуске, он установит необходимые настройки в операционную систему и сразу можно начинать пользоваться. После того, как SQL Developer полностью запустится, нужно создать новое подключение. Создав и сохранив новое подключение, далее будем его только выбирать, не нужно будет его больше настраивать. Для создания нового подключения, нажимаем кнопку как на рисунке ниже.

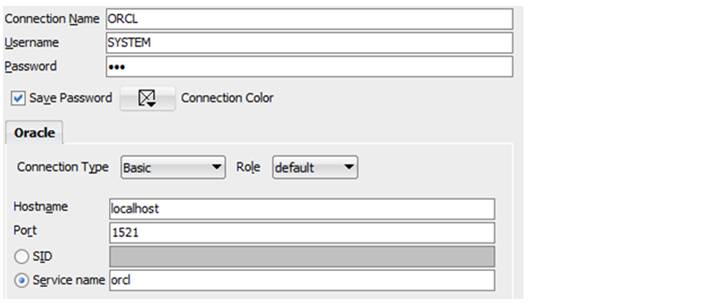
В открывшемся окне заполняем поля:
«Connection name» («Название подключения») – любое понятное Вам название, например, «Моя база»;
«Username» («Имя пользователя») – имя пользователя базы данных (см. ниже);
«Password» («Пароль») – пароль пользователя базы данных.
В качестве имени пользователя сейчас можно указать SYSTEM (это системный пользователь–администратор) и пароль, который мы придумали при установке СУБД.
Далее можем установить галочку «Save password» («Сохранить пароль»), чтобы, в последствии, подключаясь каждый раз к нашей базе данных, не вписывать пароль.
В предыдущей главе мы установили ORACLE. По–умолчанию, СУБД создает трех системных пользователей–администраторов, наделенных нужными правами: SYSTEM, SYS и SYSMAN. В последствии мы сможем сами создавать на нашей базе данных дополнительные новые учетные записи (пользователей) и давать им нужные привилегии. Так обычно и делается. Никто не работает в системных учетных записях, кроме самих администраторов баз данных, так как системные учетные записи имеют слишком много привилегий. Системные учетные записи нужны для обслуживания базы данных, выполнения важных административных настроек, управления. Так, например, с помощью них можно даже удалить всю базу данных целиком. Обычные пользователи таких привилегий не имеют. Заполняем дальше:
«Connection type» («Тип подключения») – выберем «Basic»;
«Role» («Роль») – полномочия, с которыми мы будем подключаться к базе данных, выберем «default» (то есть «по–умолчанию»);
«Hostname» («Имя сервера») – имя компьютера или адрес в Интернете, где расположен сервер базы данных. В нашем случае, сервер – это и есть наш локальный компьютер, поэтому напишем localhost (как на фото выше);
«Port» («Порт») – порт сервера (если ты мало знаком с айти, то порт – это, в нашем случае, как бы «номер сетевой двери», в которой Оракл ожидает прием команд извне для выполнения их в базе данных) – установим стандартный порт 1521, так как мы его при установке СУБД не меняли;
«SID» или «Service name» – можно установить переключатель в любой из двух положений и указать имя базы данных, которое мы дали при установке. В нашем случае это «orcl».
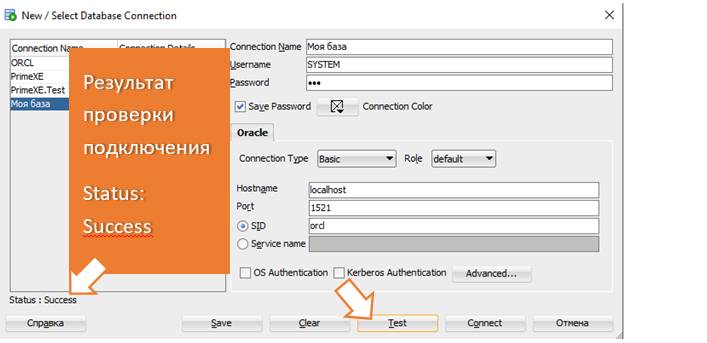
После того, как указали все настройки подключения, нажимаем кнопку «Test», чтобы проверить подключение. В результате мы должны увидеть «Status: Success» («Состояние: Успех»). Теперь нажимаем кнопку «Save» («Сохранить»), чтобы сохранить новое подключение и потом кнопку «Connect» («Подключиться»).
Теперь у нас установлена одна из самых востребованных систем управления базами данных, специалисты в области которой имеют высокооплачиваемую зарплату – это СУБД ORACLE! У нас также уже установлена программа SQL Developer, через которую мы будем работать с нашей базой данных и даже настроено подключение к нашей пока пустой базе данных.
Осталось только закачать в нашу пока пустую базу данных тестовые данные.
5.3. Создание тестовой базы данных
Итак, с помощью кнопки «Connect» мы соединились с нашей базой данных, иначе говоря, зашли в нее.
Слева, в дереве объектов базы данных активного подключения, мы можем видеть все объекты базы данных, разделенные по группам (папкам). Например, таблицы расположены в группе «Tables».

Большое окно, занимающее почти весь экран – это окно написания SQL–запросов. Здесь мы будем проводить почти все наше рабочее время и создавать исключительно шедевры на языке SQL! Можно одновременно работать с более чем одним запросом. Например, составляя и продумывая один большой SQL–запрос, мы можем открыть еще одно SQL–окно и написать некоторый другой запрос на проверку некоторых сторонних данных.
Чтобы открыть новое (или первое) SQL окно (если мы его закрыли), нужно сверху в главном меню нажать «Tools» («Инструменты») – «SQL Worksheet» («SQL окно»). Или, по–умолчанию, Alt+F10. Далее, в появившемся окне, нужно выбрать к какой базе будем писать SQL запросы – выберем наше единственное подключение и нажмем «OK».

Если бы у нас было бы несколько подключений, то в одном SQL–окне мы могли бы работать с одной базой данных, например, с тестовой, а во втором SQL–окне мы могли бы работать с боевой базой данных. Получив запросами данные из разных баз данных в разных окнах, мы могли бы их, например, сравнивать. Хотя для этого можно было бы использовать более удобные средства.
Открыть новое SQL–окно можно, также, нажав кнопку на панели инструментов.

Приступим к загрузке в нашу базу данных тестовых данных. Вначале закачиваем скрипт на компьютер:
https://prime–soft.biz/download/dbscript1.sql
Теперь нажимаем «File» («Файл») – «Open» («Открыть») или одноименную кнопку на панели инструментов (в виде открывающейся папки) и выбираем скаченный файл. В открывшемся окне нажимаем кнопку на панели инструментов «Run Script» («Выполнить скрипт»).
После выполнения скрипта наша база данных будет готова!

В группе объектов «Tables» («Таблицы») в дереве объектов базы данных появятся новые объекты. Если хотим видеть их прямо сейчас, а не дожидаться перезапуска программы SQL Developer, – нужно щелкнуть правой кнопкой мыши по объектам «Tables» («Таблицы») и выбрать «Refresh» («Обновить»).
В группе объектов «Tables» («Таблицы») мы видим сейчас достаточно много объектов и большая часть из них системные, то есть они не были добавлены нашим скриптом и мы с ними работать не будем. Почему же тогда они отображаются? Потому, что мы сейчас используем системную учетную запись. Мы администраторы. По–хорошему, уже бизнес (тестовые) объекты (таблицы с данными) мы могли прогрузить в отдельной схеме данных, а не в системном пользователе, чтобы слева в дереве объектов не отображались «лишние» таблицы. Но мы итак уже проделали слишком много работы для подготовки нашего рабочего места. Поэтому, пока остановимся на том, что будем работать (практиковаться, учиться) из–под пользователя SYSTEM. И ничего, что мы видим «лишние» таблицы в дереве объектов. Мы просто скоро запомним некоторый набор таблиц, которые мы будем использовать и с которыми будем практиковаться при написании SQL–запросов. Системные таблицы трогать не будем!
Мы установили ORACLE, программу SQL Developer, настроили (создали и сохранили) подключение к установленной СУБД и еще загрузили тестовые данные для выполнения практических задач! Мы подготовили рабочее место!
Сейчас самое время сделать небольшую паузу. Заслуженно отдохнуть. Со следующей главы мы продолжим изучать SQL, и теперь, в конце каждой главы, мы будем выполнять самостоятельные практические задачи! Итак, начинаем наш курс!
6. Операторы сравнения IN, LIKE и BETWEEN
Помимо основных операторов сравнения (больше, меньше, равно, меньше или равно, больше или равно) в языке SQL есть операторы, упрощающие выборку данных по диапазону или множеству. Например, если нужно из таблицы банковских операций отобрать те, у которых код операции 12, 23, 48, 49, 54 или один из еще некоторого множества чисел, то, чтобы не перебирать все эти значения при сравнении со столбцом через оператор OR, можно делать запросы вида:

Отберутся операции, у которых в столбце «OPER_CODE» значение входит в перечисленное множество, иначе говоря, одно из них. Символ звездочки после слова SELECT указывает на то, что будут выбраны все столбцы таблицы «Oper».
Отберем сотрудников, работающих в первом филиале в первом, втором или третьем департаменте.

Надеюсь, что применение оператора IN достаточно хорошо стало понятно. Теперь рассмотрим следующий оператор. В начале выберем сотрудника, зная его точное ФИО:

Получаем результат:

Выбралась конкретная строчка из таблицы, у которой в столбце NAME строгое соответствие запрашиваемому текстовому значению.
Для того, чтобы искать не по точному соответствию, а по фрагменту или маске, можно использовать оператор LIKE (like – это не только с англ. «нравиться», но и «как», в смысле «похож»).

В результате из таблицы сотрудников будут отобраны Анны, а точнее те строчки, у которых в столбце NAME есть фрагмент «Анна». Значки процентов в начале и конце слова означают, что в этом месте может быть еще текст. То есть слово «Анна» должно быть в NAME, но оно может сопровождаться в начале и в конце еще текстом. И такие совпадения будут отобраны. Если в начале или в конце текста не будет, а также, если NAME состоит целиком только из «Анна», то такие строчки тоже будут отобраны. Результат:

Попробуем отобрать всех сотрудников с именем «Иван»:

Сколько много данных вернулось! Похоже, здесь есть что–то лишнее:

Мы видим, что помимо сотрудников с именем «Иван» отобрались еще и те, у кого в столбце NAME есть этот фрагмент не в составе имени, а является частью фамилии или отчества. Что же делать? Мы можем в качестве фрагмента поиска указать « Иван » с пробелами в начале и конце! Таким образом это будет означать, что слева и справа есть еще слова, отделенные от «Иван» пробелами – это фамилия и отчество.

Теперь всех отобранных сотрудников точно зовут «Иван»:

Если бы нам нужно было найти всех сотрудников, чья фамилия начинается со слова «Иван», то оператору LIKE необходимо было быть дать значение:

Найдутся сотрудники, у которых в графе NAME значение начинается с «Иван»:

Помимо знака «%» при поиске с LIKE можно использовать символ нижнего подчеркивания – «_». Он означает обязательно один любой символ (буква, цифра, символ). Например, при поиске автомобиля по регистрационному номеру, мы хотим найти тот у которого в номере буква «в», «а» и «а», но между первой и второй буквой идут три цифры, тогда мы можем использовать «маску» поиска, указав после первой «в» три нижних подчеркивания:

Так как в таблице «PersonCars» («Автомобили сотрудников») в столбце CARREGNUMBER регистрационный номер указан с кодом региона и страны, то после букв «а» мы указали «%». Отобранные автомобили имеют номера, начинающиеся на букву «в» и соответствующие маске поиска:

По–умолчанию, поиск с LIKE, а также по точному совпадению, регистрозависимый, то есть, если в таблице PersonCars был бы автомобиль, с большими буквами в регистрационном номере, то мы бы его не отобрали. Упустили. Существуют настройки СУБД, позволяющие делать поиск регистронезависимым, но это, почти всегда, не практикуется. Чуть позже мы сами немного доработаем наш запрос, и он будет работать на любых базах регистронезависимо. Мы будем находить строчки из таблицы, соответствующие маске, и будет не важно, какими буквами написан текст в сравниваемом столбце – мы научимся всегда отбирать нужные данные!
Теперь посмотрим, как можно отбирать данные, где значение в столбце входит в некоторый диапазон. Например, может потребоваться отобрать платежи, совершенные за некоторый временной промежуток. Или мы можем отобрать сотрудников, чьи даты рождения попадают в определенный диапазон. По–простому, мы можем написать так:

Отберутся все строчки из Persons, для которых в столбце BIRTHDATE значение больше или равно начальной дате и одновременно меньше или равно конечной дате. Каждая отбираемая строчка будет проверена одновременно на два условия. Чтобы упростить выбор данных за диапазон, мы можем использовать оператор BETWEEN:

Выглядит проще, не так ли? Теперь имя столбца в условие пишется только один раз. Отберутся строки, для которых дата рождения между «01.01.1980» и «31.12.1989».
Чтобы воспользоваться оператором BETWEEN, его нужно написать сразу после названия столбца, значение которого необходимо принимать для сравнения, затем первую границу диапазона, потом AND и последнюю границу диапазона:

Отлично! Теперь мы можем выбирать данные с условием за диапазон. Первое, что нужно поправить, это правильную подачу дат в SQL–запрос. Почему данная вставка дат не корректная и к чему это может привести? Если мы попробуем выполнить на нашей базе данных один из запросов в котором есть даты в условии, приведенных выше, то мы даже можем получить ошибку от Oracle. И это будет правильно! Сейчас в запрос в кавычках мы пишем дату, но то, что пишется в кавычках для СУБД – это текст. Согласно полученному от нас SQL–запросу, Oracle «понимает», что необходимо отбирать данные, опираясь на столбец, в котором лежат даты и что нас интересуют такие строчки из таблицы, где дата в определенном диапазоне (дат). Чтобы понять, входит ли дата в строке в определенный диапазон (дат), необходимо сначала текст, содержащий начальную и конечную дату диапазона, преобразовать в даты. И Oracle до выполнения запроса, выполняет неявное преобразование текста в даты. Такое преобразование текста в дату называется неявным, так как оно осуществляется без нашего явного на то указания. Но Ораклу нужно выполнить запрос чтобы сравнить даты рождения сотрудников и понять, попадают ли они в диапазон, вот он и выполняет такое преобразование!
Как писать запросы с включенными в них датами, мы узнаем из следующей темы.
7. Преобразование данных
7.1 Функция to_date
Итак, мы поняли, что при написании дат в SQL–запросах в виде текста (то есть дат в кавычках, так как все, что в кавычках – это текст), перед выполнением SQL–запросов, даты из текста будут автоматически распознаны. Текст будет неявно преобразован в дату. Неявно, означает, что без явной нашей команды на преобразование. ORACLE, на основании своего понимания как должна выглядеть дата, делает ее извлечение из текста.
Например, в SQL запросе указана дата вида: '01.03.1980'. На одном компьютере, ORACLE может «понять», что первые две цифры – это номер дня, затем, после точки, идет номер месяца и в конце указан четырехсимвольный номер года. На другом компьютере СУБД распознает дату с предшествующим месяцем, затем с днем. То есть, наоборот.
В первом случае, будут отобраны данные за первое марта, во втором случае – за третье января. Такое использование дат в SQL запросах крайне опасно. Особенно в описанном выше случае – ORACLE «смог» из текста распознать дату, но мы не узнали, что он распознал ее неправильно. СУБД не выдала ошибку. На основе полученных данных мог строиться анализ и приниматься важное решение.
Если бы в запрос передавалась дата '21.01.1980', а Оракл ожидал бы в начале месяц, а потом день, то при выполнении запроса, мы бы получили ошибку о некорректном номере месяца. Получение явной ошибки от Оракла – это лучше, чем ее скрытое наличие. Теперь самое время научиться вписывать даты в запрос правильно.
Для того, чтобы правильно вписать дату в SQL–запрос, необходимо ее явно преобразовать из текста в дату с указанием того, как она должна быть преобразована. Что из написанного день, а что – месяц. Для этого воспользуемся функцией Oracle – to_date.
В функции to_date вначале нужно указать какой текст должен быть преобразован в дату, а затем нужно указать маску (формат) преобразования.

Пример использования функции to_date:

Приведенный выше запрос выбирает из таблицы Persons сотрудников, родившихся в 80–е.
Напишем запрос, выводящий все заказы в платной столовой (расположенной на пятом этаже в нашей компании), сделанные 10 марта 2019 года:

Получаем результат (на скриншоте ниже показаны не все отобранные данные – в целях экономии места):

В колонке PersonID идентификатор сотрудника, сделавшего заказ. В колонке DateOrder дата заказа, и в колонке DishID – идентификатор заказанного блюда.
7.2. Функция to_char
Еще одна функция преобразования Oracle. В отличии от рассмотренной предыдущей функции, функция to_char делает обратное – преобразовывает в текст. Имеет два главный входных параметра: первый параметр – число или дата, которую нужно преобразовать в текст; и второй параметр – формат преобразования (как именно нужно преобразовать в текст). Есть еще и третий необязательный параметр, который мы пока опустим – это языковые параметры.
Сначала рассмотрим преобразование даты в текст. Проиллюстрируем преобразование даты в текст на примере дат рождения сотрудников. Напишем запрос, выводящий дату рождения, например, в формате месяц прописью и год цифрой. На такое способна только функция to_char!

Получим результат:

После ключевого слова SELECT мы указали вывод данных столбца NAME, BIRTHDATE и преобразованного столбца BIRTHDATE с помощью функции to_char. Функция привела выводимые даты к запрашиваемому во втором параметре формату – месяц прописью и год числом. Если в качестве формата преобразование указать буквенное обозначение месяца, написанное в нижнем регистре, то функция to_char выведет результат с именем месяца также в таком же регистре:

Получим:

Если укажем в верхнем регистре, то и получим тоже в верхнем.
Значение месяца мы также можем вывести числом, если укажем это в формате:

Получим:

И теперь придумаем совсем хитрый формат:

Выведем день, через точку, месяц и потом через слэш номер года, состоящий из двух символов: