
Глоссариум по искусственному интеллекту: 2500 терминов. Том 1
Глубокая модель (Deep model) – это тип нейронной сети, содержащий несколько скрытых слоев219.
Глубокая нейронная сеть (ГНС) (Deep neural network) многослойная сеть, содержащая между входным и выходным слоями несколько (много) скрытых слоёв нейронов, что позволяет моделировать сложные нелинейные отношения. ГНС сейчас всё чаще используются для решения таких задач искусственного интеллекта, как распознавание речи, обработка текстов на естественном языке, компьютерное зрение и т.п., в том числе в робототехнике220.
Глубоко разделяемая сверточная нейронная сеть (Depthwise separable convolutional neural network) – это архитектура сверточной нейронной сети, основанная на Inception (раздел с данными на GitHub), но в которой модули Inception заменены свертками, отделяемыми по глубине. Также известен как Xception221.
Глубокое обучение (Deep Learning) – это разновидность машинного обучения на основе искусственных нейронных сетей, а также глубокое (глубинное) структурированное или иерархическое машинное обучение, набор алгоритмов и методов машинного обучения (machine learning) на основе различных видов представления данных. Обучение может быть контролируемым, полу контролируемым (semi-supervised) или неконтролируемым. Использование в глубоком обучении рекуррентных нейронных сетей (recurrent neural networks), позволяет эффективно решать задачи в областях компьютерного зрения, распознавания речи, обработки текстов на естественном языке, машинного перевода, биоинформатики и др.222.
Государство-как-Платформа (State-as-Platform) – это концепция трансформации государственного управления с использованием возможностей, которые нам дают новые технологии. Целевой функцией реализации идеи «Государство-как-Платформа» является благополучие граждан и содействие экономическому росту, основанному на внедрении технологий. В фокусе развертывания Платформы находится гражданин в условиях новой цифровой реальности. Государство должно создать условия, которые помогут человеку раскрыть свои способности, и сформировать комфортную и безопасную среду для его жизни и реализации потенциала, а также для создания и внедрения инновационных технологий223,224.
Градиент (Gradient) – это вектор, своим направлением указывающий направление наибольшего возрастания некоторой скалярной величины (значение которой меняется от одной точки пространства к другой, образуя скалярное поле), а по величине (модулю) равный скорости роста этой величины в этом направлении225.
Градиентная обрезка (Gradient clipping) – это метод, позволяющий справиться с проблемой взрывающихся градиентов путем искусственного ограничения (отсечения) максимального значения градиентов при использовании градиентного спуска для обучения модели226.
Градиентный спуск (Gradient descent) – это метод минимизации потерь путем вычисления градиентов потерь по отношению к параметрам модели на основе обучающих данных. Градиентный спуск итеративно корректирует параметры, постепенно находя наилучшую комбинацию весов и смещения для минимизации потерь227.
Граница решения (Decision boundary) – это разделитель между классами, изученными моделью в задачах классификации двоичного класса или нескольких классов228.
Граница решения или поверхность решения (в статистико-классификационной задаче с двумя классами) (Decision boundary) – это гиперповерхность, разделяющая нижележащее векторное пространство на два множества, по одному для каждого класса. Классификатор классифицирует все точки на одной стороне границы принятия решения как принадлежащие одному классу, а все точки на другой стороне как принадлежащие другому классу.
Граф (Graph) – это таблица, составленная из данных (тензоров) и математических операций. TensorFlow – это библиотека для численных расчетов, в которой данные проходят через граф. Данные в TensorFlow представлены n-мерными массивами – тензорами229.
Граф (абстрактный тип данных) (Graph) – в информатике граф – это абстрактный тип данных, который предназначен для реализации концепций неориентированного графа и ориентированного графа из математики; в частности, область теории графов230.
Граф (с точки зрения компьютерных наук и дискретной математики) (Graph) – это абстрактный способ представления типов отношений, например дорог, соединяющих города, и других видов сетей. Графы состоят из рёбер и вершин. Вершина – это точка на графе, а ребро – это то, что соединяет две точки на графе231.
Графический кластер (Graphics Processing Cluster, GPC) – это доминирующий высокоуровневый блок, включающий все ключевые графические составляющие232.
Графический процессор (Graphical Processing Unit) – это отдельный процессор, расположенный на видеокарте, который выполняет обработку 2D или 3D графики. Имея процессор на видеокарте, компьютерный процессор освобождается от лишней работы и может выполнять все другие важные задачи быстрее. Особенностью графического процессора (GPU), является то, что он максимально нацелен на увеличение скорости расчета именно графической информации (текстур и объектов). Благодаря своей архитектуре такие процессоры намного эффективнее обрабатывают графическую информацию, нежели типичный центральный процессор компьютера233.
Графический процессор-вычислитель (Computational Graphics Processing Unit) (ГП-вычислитель cGPU) – это многоядерный ГП, используемый в гибридных суперкомпьютерах для выполнения параллельных математических вычислений; например, один из первых образцов ГП этой категории содержит более 3 млрд транзисторов – 512 ядер CUDA и память ёмкостью до 6 Гбайт234.
Графовая база данных (Graph database) — это база, предназначенная для хранения взаимосвязей и навигации в них. Взаимосвязи в графовых базах данных являются объектами высшего порядка, в которых заключается основная ценность этих баз данных. В графовых базах данных используются узлы для хранения сущностей данных и ребра для хранения взаимосвязей между сущностями. Ребро всегда имеет начальный узел, конечный узел, тип и направление. Ребра могут описывать взаимосвязи типа «родитель-потомок», действия, права владения и т. п. Ограничения на количество и тип взаимосвязей, которые может иметь узел, отсутствуют. Графовые базы данных имеют ряд преимуществ в таких примерах использования, как социальные сети, сервисы рекомендаций и системы выявления мошенничества, когда требуется создавать взаимосвязи между данными и быстро их запрашивать235.
Графовые нейронные сети (Graph neural networks) – это класс методов глубокого обучения, предназначенных для выполнения выводов на основе данных, описанных графами. Графовые нейронные сети – это нейронные сети, которые можно напрямую применять к графам и которые обеспечивают простой способ выполнения задач прогнозирования на уровне узлов, ребер и графов. GNN могут делать то, что не смогли сделать сверточные нейронные сети (CNN). Также под Графовыми нейронными сетями понимают нейронные модели, которые фиксируют зависимость графов посредством передачи сообщений между узлами графов. В последние годы варианты GNN, такие как сверточная сеть графа (GCN), сеть внимания графа (GAT), рекуррентная сеть графа (GRN), продемонстрировали новаторские характеристики во многих задачах глубокого обучения236.
Графы знаний (Knowledge graphs) – это структуры данных, представляющие знания о реальном мире, включая сущности люди, компании, цифровые активы и т.д.) и их отношения, которые придерживаются модели данных графа – сети узлов (вершин) и соединения (ребер/дуг)237.
Гребенчатая регуляризация (Ridge regularization) – синоним «Регуляризации L2». Термин гребенчатая регуляризация чаще используется в контексте чистой статистики, тогда как регуляризация L2 чаще используется в машинном обучении238.
«Д»
Данные (Data) – это информация собранная и трансформированная для определенных целей, обычно анализа. Это может быть любой символ, текст, цифры, картинки, звук или видео.
Данные тестирования (Testing Data) – это подмножество доступных данных, выбранных специалистом по данным для этапа тестирования разработки модели.
Данные ограниченного использования (Restricted-use data) – это данные, которые содержат конфиденциальную информацию (обычно о людях), которая может позволить идентифицировать людей. Наличие конфиденциальной информации в депонированном цифровом контенте представляет собой проблему управления для долгосрочного хранения, чтобы гарантировать, что требования к архивному хранилищу для достижения распределенной избыточности учитывают, например, требования конфиденциальности239.
Дартмутский семинар (Dartmouth workshop) – Дартмутский летний исследовательский проект по искусственному интеллекту – так назывался летний семинар 1956 года, который многие считают основополагающим событием в области искусственного интеллекта240.
Датамайнинг (Datamining) – это процесс обнаружения и интерпретации значимых закономерностей и структур в исходных данных, которые могут быть использованы для решения сложных бизнес-вопросов и высокоинтеллектуального прогнозирования241.
Даунсэмплинг (downsampling) — это уменьшение количества информации в функции для более эффективного обучения модели. Например, перед обучением модели распознавания изображений, субдискретизация изображений с высоким разрешением до формата с более низким разрешением; Обучение на непропорционально низком проценте чрезмерно представленных примеров классов, чтобы улучшить модель обучения на недопредставленных классах242.
Движок искусственного интеллекта (Artificial intelligence engine) (также AI engine, AIE) – это движок искусственного интеллекта, аппаратно-программное решение для повышения скорости и эффективности работы средств системы искусственного интеллекта.
Двоичное число (Binary number) – это число, записанное в двоичной системе счисления, в которой используются только нули и единицы. Пример: Десятичное число 7 в двоичной системе счисления: 111243.
Двоичный формат (Binary format) – это любой формат файла, в котором информация закодирована в каком-либо формате, отличном от стандартной схемы кодирования символов. Файл, записанный в двоичном формате, содержит информацию, которая не отображается в виде символов. Программное обеспечение, способное понимать конкретный метод кодирования информации в двоичном формате, должно использоваться для интерпретации информации в файле в двоичном формате. Двоичные форматы часто используются для хранения большего количества информации в меньшем объеме, чем это возможно в файле символьного формата. Их также можно быстрее искать и анализировать с помощью соответствующего программного обеспечения. Файл, записанный в двоичном формате, может хранить число «7» как двоичное число (а не как символ) всего в 3 битах (т.е. 111), но чаще используется 4 бита (т.е. 0111). Однако двоичные форматы обычно не переносимы. Файлы программного обеспечения записываются в двоичном формате. Примеры файлов с числовыми данными, распространяемых в двоичном формате, включают двоичные версии IBM файлов Центра исследований цен на ценные бумаги и Национального банка торговых данных Министерства торговли США на компакт-диске. Международный валютный фонд распространяет международную финансовую статистику в смешанном формате и двоичном (упакованно-десятичном) формате. SAS и SPSS хранят свои системные файлы в двоичном формате244.
Двоичная, бинарная или дихотомическая классификация (Binary classification) – это задача классификации элементов заданного множества в две группы (определение, какой из групп принадлежит каждый элемент множества) на основе правила классификации245.
Двунаправленная языковая модель (Bidirectional language model) – это языковая модель, которая определяет вероятность того, что данный маркер присутствует в заданном месте в отрывке текста на основе предыдущего и последующего текста246.
Двунаправленность (Bidirectional) – это термин, используемый для описания системы оценки текста, которая одновременно исследует предшествующий и последующий разделы текста от целевого раздела247.
Двусмыссленная фраза (Crash blossom) – это предложение или фраза с двусмысленным значением. Crash blossom представляет серьезную проблему для понимания естественного языка. Например, заголовок «бить баклуши» является Crash blossom, потому что нейронная сеть с пониманием естественного языка может интерпретировать заголовок буквально или образно248.
Дедуктивный классификатор (Deductive classifier) – это тип механизма вывода искусственного интеллекта. Он принимает в качестве входных данных набор деклараций на языке кадра об области, такой как медицинские исследования или молекулярная биология. Классификатор определяет, являются ли различные описания логически непротиворечивыми, и если нет, то выделяет конкретные описания и несоответствия между ними249.
Дедукция (Deductive Reasoning) – это способ рассуждения и доказательства на основе перехода от более общих положений к частным, один из способов прогнозирования развития и изложения материала; эффективен, когда у исследователя уже накоплен определенный опыт и знания в изучаемой области250.
Действие (Action) (в обучении с подкреплением) – это механизм, с помощью которого агент переходит между состояниями среды. Агент выбирает действие с помощью политики251.
Декларативное программирование (Declarative programming) – это парадигма программирования, в которой задаётся спецификация решения задачи, то есть описывается ожидаемый результат, а не способ его получения. Противоположностью декларативного является императивное программирование, при котором на том или ином уровне детализации требуется описание последовательности шагов для решения задачи252,253.
Демографический паритет (Demographic parity) – это метрика справедливости, которая удовлетворяется, если результаты классификации модели не зависят от данного конфиденциального атрибута254.
Дерево поведения (Behavior tree) – это ориентированный ациклический граф, узлами которого являются возможные варианты поведения робота. «Ширина» дерева указывает на количество доступных действий, а «длина» его ветвей характеризует их сложность. Деревья поведения имеют некоторое сходство с иерархическими конечными автоматами с тем ключевым отличием, что основным строительным блоком поведения является задача, а не состояние. Простота понимания человеком делает деревья поведения менее подверженными ошибкам и очень популярными в сообществе разработчиков игр255.
Дерево проблем (решений) или логическое дерево (Issue tree) – это денотативное (отражающее ситуацию) представление процесса принятия решений, представленное в виде графической разбивки задачи, разделенное на отдельные компоненты по вертикали и горизонтали. Деревья решений в искусственном интеллекте используются для того, чтобы делать выводы на основе данных, доступных из решений, принятых в прошлом. Деревья решений – это статистические алгоритмические модели машинного обучения, которые интерпретируют и изучают ответы на различные проблемы и их возможные последствия. В результате деревья решений знают правила принятия решений в конкретных контекстах на основе доступных данных256.
Дерево решений (Decision Tree) – это метод представления решающих правил в иерархической структуре, состоящей из элементов двух типов – узлов (node) и листьев (leaf). В узлах находятся решающие правила и производится проверка соответствия примеров этому правилу по какому-либо атрибуту обучающего множества257,258,259.
Декомпрессия (Decompression) – это функция, которая используется для восстановления данных в несжатую форму после сжатия260.
Децентрализованное управление (Decentralized control) – это процесс, при котором существенное количество управляющих воздействий, относящихся к данному объекту, вырабатываются самим объектом на основе самоуправления261.
Децентрализованные приложения (Decentralized applications, dApps) – это цифровые приложения или программы, которые существуют и работают в блокчейне или одноранговой (P2P) сети компьютеров, а не на одном компьютере. DApps (также называемые «dapps») находятся вне компетенции и контроля одного органа. DApps, которые часто создаются на платформе Ethereum, можно разрабатывать для различных целей, включая игры, финансы и социальные сети262.
Дешифратор (декодер) (Decoder) – это комбинационное устройство с несколькими входами и выходами, у которого определенным комбинациям входных сигналов соответствует активное состояние одного из выходов. Дешифраторы преобразуют двоичный или двоично-десятичный код в унитарный код263.
Диагностика (Diagnosis) – это термин, связанный с разработкой алгоритмов и методов, способных определить правильность поведения системы. Если система работает неправильно, алгоритм должен быть в состоянии определить с максимально возможной точностью, какая часть системы дает сбой и с какой неисправностью она сталкивается. Расчет основан на наблюдениях, которые предоставляют информацию о текущем поведении264.
Диалоговые системы (Dialogue system) – это компьютерные системы, предназначенные для общения с человеком. Они имитируют поведение человека и обеспечивают естественный способ получения информации, что позволяет значительно упростить руководство пользователя и тем самым повысить удобство взаимодействия с такими системами. Диалоговую систему также называют разговорным искусственным интеллектом или просто ботом. Диалоговая система может в разной степени являться целеориентированной системой (англ. goal/task-oriented) или чат-ориентированной (англ. chat-oriented)265.
Дизайн-центр (Design Center) – это организационная единица (вся организация или ее подразделение), выполняющая полный спектр или часть работ по созданию продукции до этапа ее серийного производства, а также обладающая необходимыми для этого кадрами, оборудованием и технологиями266.
Диктовка (Dictation) – это речевой (голосовой) ввод текста.
Динамическая модель (Dynamic model) – это теоретическая конструкция (модель), описывающая изменение состояний объекта. Она может включать в себя описание этапов или фаз или диаграмму состояний подсистем. Часто имеет математическое выражение и используется главным образом в общественных науках (например, в социологии), имеющих дело с динамическими системами, однако современная парадигма науки способствует тому, что данная модель также имеет широкое распространение во всех без исключения науках, в том числе в естественных и технических. Динамическая модель обучается онлайн в постоянно обновляемой форме. То есть данные непрерывно поступают в модель267,268.
Динамическая эпистемическая логика (Dynamic epistemic logic, DEL) – это логическая структура, связанная с изменением знаний и информации. Как правило, DEL фокусируется на ситуациях с участием нескольких агентов и изучает, как меняются их знания при возникновении событий269.
Дискретная система (Discrete system) – это кибернетическая система, все элементы которой, а также связи между ними (т.е. обращающаяся в системе информация) имеют дискретный характер. Содержит в себе понятие дискретного сигнала. Т.е., это любая система в замкнутом контуре управления в которой используются дискретные сигналы270.
Дискретные признаки (Discrete feature) – это количественные признаки, принимающие отдельные, иногда только целочисленные значения. Например, число жителей города, заболевших гриппом за год271.
Дискриминатор (Discriminator) – это функциональная группа, выполняющая сравнение двух одноименных входных величин (мгновенных значений или амплитуд, частот, фаз, задержек электрических сигналов; дальностей, направлений, скоростей объектов и т.п.), выходной сигнал которой пропорционален разности значений этих величин. В контуре управления служит датчиком рассогласования своих входных величин, формирующим сигнал ошибки. Это система, которая определяет, являются ли примеры реальными или поддельными272.
Дискриминационная модель (Discriminative model) – это модель, предсказывающая метки на основе набора из одного или нескольких признаков. Более формально, дискриминационные модели определяют условную вероятность выхода с учетом характеристик и весов273.
Дикий код (Wild code) – это коды, которые не разрешены для конкретного вопроса. Например, если вопрос, в котором указывается пол респондента, имеет задокументированные коды «1» для женского пола и «2» для мужского пола и «9» для «отсутствующих данных», код «3» будет «диким». код, который иногда называют «недокументированным кодом»274.
Длинный Хвост (Long Tail) означает разнообразную, но малообъемную часть ассортимента продукции. Интернет сделал возможным получение прибыли от продажи продуктов с длинным хвостом. Концепция была представлена Крисом Андерсоном в 2004 году275.
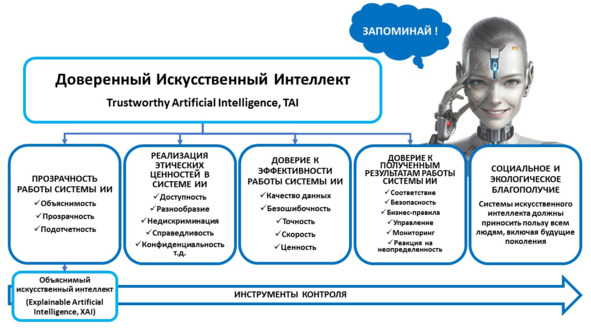
Доверенный или надежный искусственный интеллект (Trustworthy Artificial Intelligence, TAI) – это прикладная система искусственного интеллекта, обеспечивающая выполнение возложенных на нее задач с учетом ряда дополнительных требований, учитывающих этические аспекты применения искусственного интеллекта, а также обеспечивающая доверие к результатам работы системы ИИ, которые включают в себя: Достоверность (надежность) и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах. Безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий. Приватность и верифицируемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы276.
Документация (Documentation) как правило, – это любая информация о структуре, содержимом и макете файла данных. Иногда называется «технической документацией» или «кодовой книгой». Документацию можно рассматривать как специализированную форму метаданных277.
Документированная информация (Documented information) – это зафиксированная на материальном носителе путем документирования информация с реквизитами, позволяющими определить такую информацию, или в установленных законодательством Российской Федерации случаях ее материальный носитель278.
Дистанционное медицинское обслуживание (Remote Medical Care) – это телемедицинский сервис, позволяющий осуществлять постоянный мониторинг состояния пациента и проведение профилактических и контрольных осмотров вне медицинских учреждений. Эта форма ухода стала возможной благодаря использованию мобильных устройств, которые измеряют основные показатели жизнедеятельности. Результаты передаются в Центр дистанционного медицинского обслуживания, где они автоматически анализируются. При обнаружении каких-либо отклонений медицинский персонал связывается с пациентом и вызывает скорую помощь в случае возникновения экстренной ситуации279.
Долгая краткосрочная память (Long short-term memory, LSTM) – это разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям, скрытым марковским моделям и другим методам обучения для последовательностей в различных сферах применения. Также, – это тип ячейки рекуррентной нейронной сети, используемой для обработки последовательностей данных в таких приложениях, как распознавание рукописного ввода, машинный перевод и субтитры к изображениям. LSTM решают проблему исчезающего градиента, которая возникает при обучении RNN из-за длинных последовательностей данных, сохраняя историю во внутренней памяти на основе новых входных данных и контекста из предыдущих ячеек в RNN280.