
Глоссариум по искусственному интеллекту: 2500 терминов. Том 1
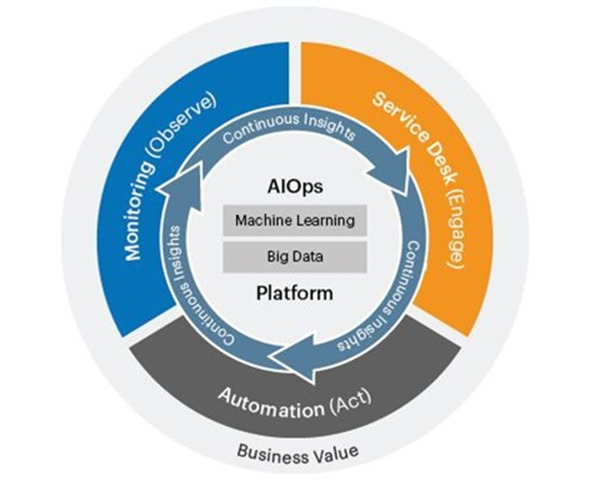
Искусственный интеллект для ИТ-операций (Artificial Intelligence for IT Operations, AIOps) – это использование машинного обучения и других технологий искусственного интеллекта для автоматизации различных рабочих и технологических ИТ-процессов, которые инженерами-программистами выполняются вручную. AIOps похож на MLOps тем, что использует машинное обучение и другие технологии искусственного интеллекта для автоматизации ИТ-процессов. AIOps отличается от MLOps тем, что автоматизация процессов происходит в отделе ИТ-операций организации, а не в группе машинного обучения и искусственного интеллекта. Также AIOps отличается от MLOps тем, что использует искусственный интеллект для автоматизации группы процессов, а не только одной или двух задач, как это делает MLOps. Искусственный интеллект для ИТ-операций – это новая ИТ-практика, которая применяет искусственный интеллект к ИТ-операциям, чтобы помочь организациям разумно управлять ИТ-инфраструктурой, сетями и приложениями для обеспечения высокого качества, производительности, отказоустойчивости и безопасности. Термин AIOps появился в 2016 году, как отраслевая категория, которая помогает улучшить процессы автоматизации ИТ-операций с помощью технологий искусственного интеллекта387,388,389.
Искусственный Интеллект на уровне человека (Human Level Machine Intelligence) – это синоним полного ИИ, завершенного ИИ, сильного ИИ. Этот термин обозначает степень развития искусственного интеллекта на уровне человека. Человеческий мозг является моделью для создания такого интеллекта.
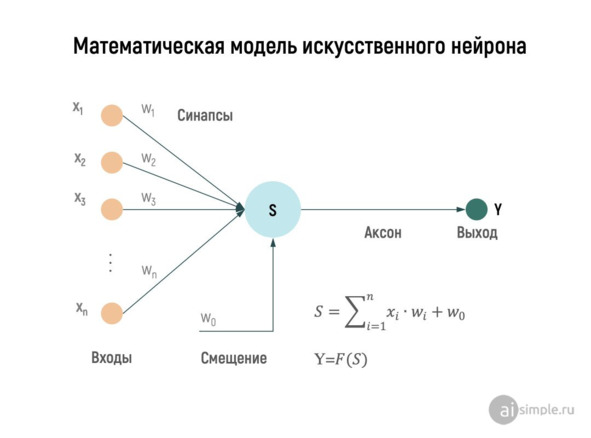
Искусственный нейрон (Artificial neuron) – это математическая функция, задуманная как модель биологических нейронов, нейронная сеть. Разница между искусственным нейроном и биологическим нейроном представлена на рисунке. Искусственные нейроны – это элементарные единицы искусственной нейронной сети. Искусственный нейрон получает один или несколько входных сигналов (представляющих возбуждающие постсинаптические потенциалы и тормозные постсинаптические потенциалы на нервных дендритах) и суммирует их для получения выходного сигнала (или активации, представляющего потенциал действия нейрона, который передается по его аксону). Обычно каждый вход взвешивается отдельно, а сумма проходит через нелинейную функцию, известную как функция активации или передаточная функция. Передаточные функции обычно имеют сигмовидную форму, но они также могут принимать форму других нелинейных функций, кусочно-линейных функций или ступенчатых функций. Они также часто являются монотонно возрастающими, непрерывными, дифференцируемыми и ограниченными390,391.
Искусственный сверхинтеллект (Artificial Super Intelligence, ASI) – это термин, который обозначает наивысшую степень развития искусственного интеллекта, превосходящую человеческие возможности во всех аспектах его жизнедеятельности392. На сегодняшний день систем искусственного сверхинтеллекта также, как и систем сильного или общего искусственного интеллекта не существует. Многие ученые считают, что до создания супер интеллекта пройдет очень много времени, но большинство из них все же сходятся во мнении, что это рано или поздно произойдет.
Исполняемый код (Executable) – это исполняемая программа, иногда называемая просто исполняемым или двоичным файлом, заставляет компьютер «выполнять указанные задачи в соответствии с закодированными инструкциями», в отличие от файла данных, который необходимо интерпретировать (открыть) программой, чтобы получить действие или результат393.
Исследование (Study) – это вся информация, собранная в одно время или для одной цели или одним главным исследователем. Исследование состоит из одного или нескольких файлов394.
Исследования будущего (Futures studies) – это изучение постулирования возможных, вероятных и предпочтительных вариантов будущего, а также мировоззрений и мифов, лежащих в их основе395.
Исходная отметка (Бенчмарк) ИИ (AI benchmark) – это эталонный тест ИИ для оценки возможностей, эффективности, производительности и для сравнения ИНС, моделей машинного обучения (МО), архитектур и алгоритмов при решении различных задач ИИ создаются и стандартизируется специальные эталонные тесты, исходные отметки. Например, Benchmarking Graph Neural Networks – бенчмаркинг (эталонное тестирование) графовых нейронных сетей (ГНС, GNN) – обычно включает инсталляцию конкретного бенчмарка, загрузку исходных датасетов, проведение тестирования ИНС, добавление нового датасета и повторение итераций.
Исчисление высказываний (также логика высказываний и логика нулевого порядка) (Propositional calculus) – это раздел логики, который имеет дело с высказываниями (которые могут быть истинными или ложными) и потоком аргументов. Сложные предложения образуются путем соединения предложений логическими связками. Предложения без логических связок называются атомарными предложениями. В отличие от логики первого порядка, логика высказываний не имеет дело с нелогическими объектами, предикатами о них или кванторами. Однако весь механизм пропозициональной логики включен в логику первого порядка и логику высшего порядка. В этом смысле логика высказываний является основой логики первого порядка и логики высшего порядка396.
Исчисление соединений регионов (Region connection calculus, RCC) – это действие предназначено для качественного пространственного представления и рассуждений. RCC абстрактно описывает регионы (в евклидовом пространстве или в топологическом пространстве) их возможными отношениями друг к другу. RCC8 состоит из 8 основных отношений, которые возможны между двумя регионами397.
Итерация (Iteration) – это обновление весов после анализа пакета входных записей, которое представляет собой одну итерацию обновления параметров модели нейронной сети398.
Исходный код (Source code) – это любой набор кода с комментариями или без них, написанный с использованием удобочитаемого языка программирования, обычно в виде простого текста. Исходный код программы специально разработан для облегчения работы компьютерных программистов, которые определяют действия, которые должны выполняться компьютером, в основном, путем написания исходного кода. Исходный код часто преобразуется ассемблером или компилятором в двоичный машинный код, который может выполняться компьютером. Затем машинный код может быть сохранен для выполнения в более позднее время399.
«К»
Калибровочный слой (Calibration layer) – это корректировка после прогнозирования, обычно для учета смещения прогноза. Скорректированные прогнозы и вероятности должны соответствовать распределению наблюдаемого набора меток400.
Канонические форматы (Canonical Formats) в информационных технологиях канонизация – это процесс приведения чего-либо в соответствие с некоторой спецификацией… и в утвержденном формате. Канонизация иногда может означать создание канонических данных из неканонических данных. Канонические форматы широко поддерживаются и считаются оптимальными для долгосрочного хранения401.
Капсульная нейронная сеть (Capsule neural network) – это архитектура искусственных нейронных сетей, которая предназначена для распознавания изображений. Главными преимуществами данной архитектуры является существенное снижение размеров необходимой для обучения выборки, а также повышение точности распознавания и устойчивость к атакам типа «белый ящик». Ключевым нововведением капсульных нейросетей является наличие так называемых капсул – элементов, являющихся промежуточными единицами между нейронами и слоями, которые представляют собой группы виртуальных нейронов, отслеживающих не только отдельные детали изображения, но и их расположение друг относительно друга. Данная архитектура была задумана Джеффри Хинтоном в 1979 году, сформулирована в 2011 году и опубликована в двух статьях в октябре 2017 года402,403.
Категориальные данные (Categorical data) – это данные, качественно характеризующие исследуемый процесс или объект, не имеющие количественного выражения. В них каждая единица наблюдения назначается определенной группе или номинальной категории на основе некоторого качественного свойства. Обычно представляют собой построчные значения из ограниченного набора категорий (например, названия городов, наименования товаров, имена сотрудников и клиентов и т.д.). В некоторых случаях могут использоваться и числа, кодирующие эти категории. При обработке таких данных применяются только операции сравнения: «равно» и «не равно», производится их упорядочение, например, по алфавиту. Применение арифметических операций к категориальным данным некорректно, даже если они представлены числами404.
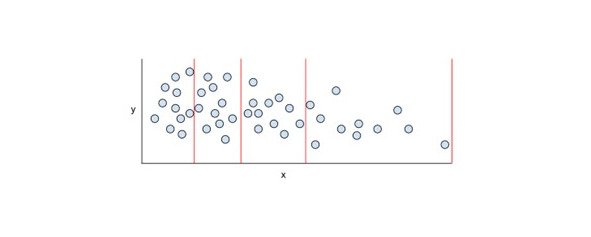
Квантильное группирование (Quantile bucketing) – это распределение значений объекта по сегментам таким образом, чтобы каждый сегмент содержал одинаковое (или почти одинаковое) количество примеров. Например, на следующем рисунке 44 точки разделены на 4 корзины, каждая из которых содержит 11 точек. Чтобы каждый сегмент на рисунке содержал одинаковое количество точек, некоторые сегменты охватывают разную ширину значений x405.
Квантификатор (Quantifier) в логике – это количественная оценка указывает количество экземпляров в области дискурса, которые удовлетворяют открытой формуле. Два наиболее распространенных квантификатора означают «для всех» и «существует». Например, в арифметике квантификаторы позволяют сказать, что натуральные числа продолжаются вечно, записав, что для всех n (где n – натуральное число) существует другое число (скажем, следующее за n), которое на единицу больше, чем n406.
Квантование (Quantization) – это разбиение диапазона отсчётных значений сигнала на конечное число уровней и округления этих значений до одного из двух ближайших к ним уровней407.
Квантовые вычисления (Quantum computing) – это использование квантово-механических явлений, таких как суперпозиция и запутанность, для выполнения вычислений. Квантовый компьютер используется для выполнения таких вычислений, которые могут быть реализованы теоретически или физически408,409.
Квантовые технологии (Quantum technologies) – это технологии создания вычислительных систем, основанные на новых принципах (квантовых эффектах), позволяющие радикально изменить способы передачи и обработки больших массивов данных410.
Киберфизические системы (Cyber-physical systems) – это интеллектуальные сетевые системы со встроенными датчиками, процессорами и приводами, которые предназначены для взаимодействия с физической окружающей средой и поддержки работы компьютерных информационных систем в режиме реального времени411.
Класс (Class) – это термин из набора перечисленных целевых значений меток. Например, в модели бинарной классификации, обнаруживающей спам-рассылку, существует два класса – это спам и не спам. В многоклассовой модели классификации, которая идентифицирует породы собак, классами будут пудель, бигль, мопс и так далее412.
Класс большинства (Majority class) – это метка в наборе данных с несбалансированным классом. Несбалансированные данные относятся к случаям, когда количество наблюдений в классе распределено неравномерно, и часто существует основной класс -класс большинства, который имеет гораздо больший процент набора данных, и второстепенные классы, в которых недостаточно примеров413.
Класс меньшинства (Minority class) – это метка в несбалансированном по классам наборе данных. Например, учитывая набор данных, содержащий 99% ярлыков, не относящихся к спаму, и 1% ярлыков для спама, ярлыки для спама относятся к классу меньшинства в наборе данных с несбалансированным классом414.
Класс сложности NP (недетерминированное полиномиальное время) (NP) – в теории вычислительной сложности – это класс, используемый для классификации проблем принятия решений. NP – это множество проблем решения, для которых экземпляры проблемы, где ответ «да», имеют доказательства, проверяемые за полиномиальное время с помощью детерминированной машины Тьюринга415.
Классификация (Classification). В задачах классификации используется алгоритм для точного распределения тестовых данных по определенным категориям, например, при отделении яблок от апельсинов. Или, в реальном мире, алгоритмы обучения с учителем можно использовать для классификации спама в отдельной папке из вашего почтового ящика. Линейные классификаторы, машины опорных векторов, деревья решений и случайный лес – все это распространенные типы алгоритмов классификации416.
Кластеризация (Clustering) – это метод интеллектуального анализа данных для группировки неразмеченных данных на основе их сходства или различия. Например, алгоритмы кластеризации K-средних распределяют сходные точки данных по группам, где значение K представляет размер группировки и степень детализации. Этот метод полезен для сегментации рынка, сжатия изображений и т.д.417.
Кластеризация временных данных (Temporal data clustering) – это разделение неразмеченного набора временных данных на группы или кластеры, где все последовательности, сгруппированные в одном кластере, должны быть согласованными или однородными. Хотя для кластеризации различных типов временных данных были разработаны различные алгоритмы, все они пытаются модифицировать существующие алгоритмы кластеризации для обработки временной информации418.
Кластеризация на основе центроида (Centroid-based clustering) – это категория алгоритмов кластеризации, которые организуют данные в неиерархические кластеры. Алгоритм k средних (k-means) – это наиболее широко используемый алгоритм кластеризации на основе центроидов, один из алгоритмов машинного обучения, решающий задачу кластеризации419.
Кластерный анализ (Cluster analysis) – это тип обучения без учителя, используемый для исследовательского анализа данных для поиска скрытых закономерностей или группировки в данных; кластеры моделируются с мерой сходства, определяемой такими метриками, как евклидово или вероятностное расстояние.
Ключевые точки (Keypoints) – это координаты определенных объектов на изображении. Например, для модели распознавания изображений в задачах компьютерного зрения, такие как оценка позы человека, обнаружение лиц и распознавание эмоций, обычно работают с ключевыми точками на изображении420
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.
Примечания
1
.Чесалов А. Ю. Глоссариум по искусственному интеллекту и информационным технологиям.-М.: Ridero. 2021.-304c. [Электронный ресурс] // Ridero.ru. URL: https://ridero.ru/books/glossarium_po_ informacionnym_tekhnologiyam_i_iskusstvennomu_intellektu/
2
A/B Testing [Электронный ресурс] https://vwo.com URL: https://vwo.com/ab-testing/ (дата обращения: 28.01.2022)
3
Abductive Logic Programming (ALP) [Электронный ресурс] https://engati.com URL: https://www.engati.com/glossary/abductive-logic-programming (дата обращения 14.02.2022)
4
Abductive reasoning [Электронный ресурс] https://msrblog.com URL: http://msrblog.com/science/mathematic/about-abductive-reasoning.html (дата обращения 14.02.2022)
5
Abstract data type [Электронный ресурс] https://embeddedartistry.com URL: https://embeddedartistry.com/fieldmanual-terms/abstract-data-type/ (дата обращения 14.02.2022)
6
Abstraction [Электронный ресурс] https://riskfirst.org URL: https://riskfirst.org/thinking/Glossary
7
Auto Associative Memory [Электронный ресурс] www.tutorialspoint.com URL: artificial_neural_network/artificial_neural_network_associate_memory.ht https://www.tutorialspoint.com/m#:~:text= These%20kinds%20of%20neural %20networks, with%20the %20given%20input%20pattern (дата обращения: 07.07.2022)
8
Autoencoder [Электронный ресурс] https://neurohive.io URL: https://neurohive.io/ru/osnovy-data-science/avtojenkoder-tipy-arhitektur-i-primenenie/ (дата обращения: 28.01.2022)
9
Automation [Электронный ресурс] https://tis-eg.com URL: https://tis-eg.com/en/what-is-automation-mean/ (дата обращения: 24.03.2023)
10
Автоматизированная обработка персональных данных [Электронный ресурс] URL: https://10.rkn.gov.ru/docs/10/Pravila_obrabotki_PD.pdf (дата обращения: 24.03.2023)
11
Автоматизированная система [Электронный ресурс] https://prezi.com URL: https://prezi.com/p/kjuyqjgiuaux/presentation/ (дата обращения: 24.03.2023)
12
Автоматизированная система управления [Электронный ресурс] https://safe-surf.ru URL: https://safe-surf.ru/glossary/ru/599613 (дата обращения: 24.03.2023)
13
Automated reasoning [Электронный ресурс] https://techtarget.com URL: https://www.techtarget.com/searchenterpriseai/definition/automated-reasoning#:~:text= Automated%20reasoning%20is %20the%20area, inferences%20towards %20that%20goal%20automatically (дата обращения: 18.02.2022)
14
Автономное транспортное средство [Электронный ресурс] https://ru.wikipedia.org URL: https://ru.wikipedia.org/wiki/Автономный_транспорт (дата обращения: 24.03.2023)
15
Autonomous [Электронный ресурс] https://www.telusinternational.com URL: https://www.telusinternational.com/insights/ai-data/article/50-beginner-ai-terms-you-should-know (дата обращения: 26.03.2023)
16
Autonomic computing [Электронный ресурс] https://www.accenture.com URL: https://www.accenture.com/us-en/insights/applied-intelligence/artificial-intelligence-glossary (дата обращения: 26.03.2023)
17
Autonomous car [Электронный ресурс] https://synopsys.com URL: https://www.synopsys.com/automotive/what-is-autonomous-car.html (дата обращения: 28.01.2022)
18
Offline inference [Электронный ресурс] https://www.facebook.com URL: https://www.facebook.com/primeclasses.in/photos/a.1765059106881298/3674394015947788/?type=3 (дата обращения: 26.03.2023)
19
Автономный искусственный интеллект https://stepik.org URL: https://stepik.org/lesson/292708/step/2 (дата обращения: 26.03.2023)
20
Autonomous artificial intelligence [Электронный ресурс] https://books.google.ru URL: https://books.google.ru/books?id=_R5XEAAAQBAJ&pg=PT217&lpg=PT217&dq= Autonomous+artificial+intelligence+a+biologically +inspired+system+that+tries+to+reproduce+the +structure+of+the+brain&source=bl&ots=NKsVUXEkc6&sig =ACfU3U23DpeuDH11ONrGFufhEpuVkLGsCw&hl= ru&sa=X&ved=2ahUKEwiz0bqhnPn9AhUCt4sKH Q5RCDoQ6AF6BAgvEAM#v=onepage&q=Autonomous %20artificial%20intelligence%20a%20biologically %20inspired%20system%20that%20tries%20to %20reproduce%20the%20structure%20of%20the %20brain&f=false (дата обращения: 26.03.2023)
21
Autonomous robot [Электронный ресурс] https://techopedia.com URL: https://www.techopedia.com/definition/32694/autonomous-robot (дата обращения: 28.01.2022)
22
Autoregressive Model [Электронный ресурс] https://wiki.loginom.ru URL: https://wiki.loginom.ru/articles/autoregressive-model.html (дата обращения: 08.02.2022)
23
Agent [Электронный ресурс] https://developers.google.com URL: https://developers.google.com/machine-learning/glossary/rl#agent (дата обращения: 26.03.2023)
24
Aggregate [Электронный ресурс] www.umich.edu (дата обращения: 07.07.2022) URL: https://www.icpsr.umich.edu/web/ICPSR/cms/2042#A
25
Aggregator [Электронный ресурс] www.techopedia.com (дата обращения: 07.07.2022) URL: https://www.techopedia.com/definition/2502/feed-aggregator
26
Агломеративная кластеризация [Электронный ресурс] https://biconsult.ru URL: https://biconsult.ru/products/aglomerativnaya-klasterizaciya-v-mashinnom-obuchenii (дата обращения: 26.03.2023)
27
Адаптивная система [Электронный ресурс] https://ru.wikipedia.org URL: https://ru.wikipedia.org/wiki/Адаптивная_система (дата обращения: 26.03.2023)
28
Adaptive neuro fuzzy inference system (ANFIS) [Электронный ресурс] https://hrpub.ru URL: https://www.hrpub.org/download/20190930/AEP1-18113213.pdf (дата обращения 14.02.2022)
29
Adaptive algorithm. [Электронный ресурс] https://dic.academic.ru (дата обращения: 27.01.2022)
30
Сжатие без потерь. [Электронный ресурс] https://dic.academic.ru URL: https://dic.academic.ru/dic.nsf/ruwiki/38681 (дата обращения: 27.01.2022)
31
Adaptive Gradient Algorithm. [Электронный ресурс] https://jmlr.org URL: https://www.jmlr.org/papers/volume12/duchi11a/duchi11a.pdf (дата обращения: 18.02.2022)
32
Аддитивные технологии [Электронный ресурс] https://books.google.ru URL: https://books.google.ru/books?id=6EYkEAAAQBAJ&pg (дата обращения: 27.03.2023)
33
Isaac Asimov [Электронный ресурс] https://www.techopedia.com URL: https://www.techopedia.com/definition/32134/isaac-asimov (дата обращения: 27.03.2023)
34
Isaac Asimov [Электронный ресурс] https://www.techopedia.com URL: https://www.techopedia.com/definition/32134/isaac-asimov (дата обращения: 27.03.2023)
35
Active Learning/Active Learning Strategy [Электронный ресурс] https://developers.google.com URL: https://developers.google.com/machine-learning/glossary (дата обращения: 27.03.2023)
36
Active Learning, Monica Nicolette Nicolescu, «A framework for learning from demonstration, generalization and practice in human-robot domains,» University of Southern California, 2003.
37
Active Learning, Brenna D and Chernova, Sonia and Veloso, Manuela and Browning, Brett Argall, «A survey of robot learning from demonstration,» Robotics and autonomous systems, vol. 57, pp. 469 – 483, 2009
38
Алгоритм [Электронный ресурс] https://intuit.ru URL: https://intuit.ru/studies/courses/1122/167/lecture/4566 (дата обращения: 27.03.2023)
39
BLEU (Bilingual Evaluation Understudy) [Электронный ресурс] https://developers.google.com URL: https://developers.google.com/machine-learning/glossary/language (дата обращения: 27.03.2023)
40
Q-learning [Электронный ресурс] https://towardsdatascience.com URL: https://towardsdatascience.com/a-beginners-guide-to-q-learning-c3e2a30a653c (дата обращения: 07.07.2022)
41
Junction tree algorithm (also Clique Tree) [Электронный ресурс] https://ai.stanford.edu URL: https://ai.stanford.edu/~paskin/gm-short-course/lec3.pdf (дата обращения: 27.03.2023)