
Data Science для новичков

Data Science для новичков
Руслан Назаров
© Руслан Назаров, 2025
ISBN 978-5-0060-2886-9
Создано в интеллектуальной издательской системе Ridero
От автора
В этой книге я собрал все 1) важные и 2) базовые знания по Data Science.
В книге код дан так, как вы его увидите в Visual Studio Code.
По тексту много ссылок на другие книги, учебники, пособия в онлайне. Рекомендуется ознакомиться с этими материалами. Моя книга может служить только своеобразным путеводителем на начальном уровне для всех, кто желает стать специалистом по Data Science.
Принципы образования
Здесь я собрал несколько практических советов, принципов самообразования.
1. Прежде, чем начинать изучение новой науки, надо понять зачем вы это делаете. Карьера, деньги? Да, многие учатся ради этого. Но это слишком незначительно для человека. Деньги и карьера могут быть побочным продуктом от учебы, но не должны быть основными причинами. Ставьте себе великие цели. Если беретесь за математику, то ваша цель – решить одну из задач Гилберта. Если беретесь за DS, то ваша задача – изобрести искусственный интеллект. Не меньше этого. Пускай даже в итоге это у вас не получится, но идти надо по пути великих целей. Только так вы сможете убедить себя, что огромные усилия, которые вы будете прикладывать, стоят того. Только так вы сможет сделать учебу интересной для себя.
2. Ваш план образования должен иметь два направления: сложное и простое. Например, сложное – математика, простое – публицистические книги про ИИ, основы программирования. Почему? Чтобы мозг не скучал. И чтобы мозг понимал, что вы занимаетесь сложной задачей и поэтому мозг должен работать максимально эффективно. Кроме того, пока мозг не ощущает опасность, он не начинает работать на максимальном уровне. Теория вероятностей вполне может быть такой опасностью. Делить учебу на сложные и простые занятия важно еще и потому, что так можно эффективно расходовать время. Если вы слишком заняты другими делами, вы болеете или устали, то можно взять легкие дела из плана учебы. Когда вы освободитесь, то можно будет заняться максимально сложными делами. Вы все время учитесь, а это очень важно. Помните, что нельзя тратить время.
3. Не пытайтесь все понять и запомнить с первого раза. Не надо себя насиловать. Пока вы учите новую науку, ваша задача не запомнить, а понять. Если вы поняли дифференциальное исчисление, а затем забыли половину теорем дифференциального исчисления, то ничего страшного. Понимание прежде всего!
4. Учитесь «слоями». Прочитайте книгу, например, по математике. Попытайтесь понять максимально много, но без насилия над собой. Не пытайтесь запомнить все теоремы, формулы. Ваша задача – понять, повторюсь. Теперь возьмите следующую книгу по математике. Попытайтесь понять максимально много. В этот раз вы поймете уже гораздо больше. Продолжайте, не останавливайтесь. Запомните, нельзя полностью выучить математику, Data Science или любую науку. Ваша цель – тренировать способность понимать. Чем больше будет «слоев» понимания, тем лучше.
5. Новый «слой» должен быть чуть сложнее предыдущего. Например, начните с учебника по математике для школы, затем возьмите учебник для университетов. Не останавливайтесь на этом «слое». Возьмите специальные книги, например подробное изложение линейной регрессии.
6. Не перечитывайте книги, которые вы уже прочитали. Если вы не понимаете какую-то тему, то лучше взять другую книгу по этой теме (или почитать пост в каком-то блоге). Однако у вас должна быть «опорная книга», например по математике, DS, программированию. Это такая книга, которая, на ваш взгляд и для вас, содержит самое простое и полное изложение темы. Это будет ваш справочник. Перечитывать такие книги можно.
7. Не бойтесь сложных книг. Даже если из всей книги вы поняли только 90%, польза огромная. Вы учите свой мозг чувствовать себя как дома в той теме, которой посвящена книга. Вы учите мозг не бояться этой темы. Вы учите термины, теоремы, формулы, алгоритмы.
8. Никогда себя не ругайте. Если что-то не получается сейчас, то это получится потом. Главное – это идти по правильному пути. Это не означает, что вы не должны заниматься самоанализом. Почему что-то не понятно? Что можно сделать, прочитать, чтобы лучше это понять?
9. Создавайте теории. Всегда создавайте теории, идеи. Не ждите, когда станете профессионалом. Ищите необычные решения, делайте безумные предположения, даже если только начали читать первые книги по математике. Главное помнить, что любая идея должна быть проверена. Пусть такой проверкой будет следующая книга или ваш личный проект.
10. Не соглашайтесь с идеями типа «математика это сложно». Не позволяйте себя этим пугать. Для человека нет ничего сложного. Что такое «сложно»? Любое знание – это объекты и связи между ними. «Сложно» – это значит много объектов, много связей. Базовый принцип для приготовления бутерброда и решения математических задач один: возьмите элементы и свяжите их. Нет никакой абстрактной «сложности». Если все дело в количестве элементов и связей, то вам просто нужно время. Базовый принцип вы уже знаете и даже блестяще им владеете (бутерброды же хорошо у вас получаются!).
11. Если вы не понимаете книгу по математике или DS, то причина просто в том, что у вас нет навыка и вы не знаете всех предпосылок. Почему, например, книги по экономике не кажутся такими сложными? Потому что многие понятия из экономики знакомы нам: безработица, прибыль и т. п. Но элементы математики, особенно абстрактной, мы встречаем в жизни редко. Возьмем теорему математики. В том учебнике, который вы читаете, нельзя рассказать все причины, по которым возникла эта теорема. Поэтому вы можете не понять эту теорему. Это не ваша вина. Вы поймете эту теорему, пускай и в следующем «слое». И еще, помните, что формулы на самом деле очень упрощают жизнь! Не обращайте внимание на слова «это очевидно» и т. п. Возможно, это очевидно автору, но не вам. В этом нет проблемы!
12. Создавайте контекст. Что такое контекст? Вы читаете учебники по математике. Но вы должны также читать книги по истории математики, по философии математики и т. п. Чем больше разных знаний у вас будет, тем лучше. Так нашему мозгу легче запоминать и так мозг лучше понимает. Помните, наш мозг воспринимает информацию из контекста, потому что мир тоже состоит из связей.
13. Делайте упражнения. Но только, когда нет других более важных дел. Упражнения, как правило, это искусственные примеры, которые являются скучными и мало применяются в жизни. Например, в обучении языку давно уже поняли, что искусственные примеры – это плохой способ учить язык. Кроме того, упражнения из учебника часто пытаются вас запутать. Это плохо. Зачем? Вам должны объяснять. Опыт придет на конкретных примерах из жизни. Поэтому создавайте свои проекты. Пускай это будут примеры, которые основаны на понятных для вас проблемах. Может быть, вам интересно применить методы математики и DS для изучения экологических проблем. Займитесь этим!
14. Ищите хорошие книги. Как это сделать? Возьмите пять книг по одной теме наугад. В этих книгах будут ссылки на другие учебники, книги. Дальше собирайте библиотеку и читайте эти книги. И добавьте в эту библиотеку классические книги по теме. Это всегда хорошее решение!
15. Не смешивайте занятия. Если сейчас вы учите математику, то не пытайтесь вспомнить код из последнего проекта.
16. Старайтесь объяснять все своими словами. Вы учитесь, накапливаете знания. Расскажите о своих знаниях! Это может быть блог или подкаст. Если можете своими словами объяснить, значит хорошо все поняли.
17. Не бойтесь, что вы медленно учитесь. Главное учиться.
18. Найдите хобби. Пускай ваше хобби будет способом отвлечься от учебы. Это тоже необходимо. Умейте отдыхать! Возьмите пару недель или месяц, чтобы отдохнуть. Пока вы отдыхаете, мозг приводит ваши знания в порядок и находит неожиданные связи.
Глава 1. Подготовка данных
Data Science содержит три больших отдела:
1) получение и подготовка данных;
2) статистическая обработка данных;
3) машинное обучение.
Статистическая обработка нацелена на:
1) описание сгруппированных данных (медиана, среднее и т.п.);
2) описание взаимодействия между различными группами данных (корреляция и т.п.).
Другими словами, статистическая обработка требует понять данные, а значит и те реальные процессы, которые стоят за данными. Это важно учитывать. В конечном счете моя задача не просто получить корреляцию, а понять данные. Что это означает? Во-первых, я должен проверять как корреляцию, так и другие статистики, на вменяемость, на соответствие действительности. Во-вторых, именно в действительности я должен искать подсказки, какие тесты применить, какие метрики получить. Так, например, понимание данных можно получить и из других источников, не только за счет применения статистических тестов. Можно сделать предположения о процессах, отраженных в данных, на основании опыта, а уже затем проверить предположения с помощью статистики. Важно помнить, что математика – это только язык, который используют, чтобы описать действительность. Не надо подменять математикой саму действительность.
Машинное обучение нацелено на создание алгоритма, который позволит предсказывать целевой признак на основании заданных признаков в автоматизированном режиме. Другими словами, статистическая обработка позволяет понять процессы, а машинное обучение – предсказать процессы.
Однако начинается все с предварительной подготовки данных. В самом деле, если не подготовить данные, не убрать пропуски, дубликаты и т.п., то это повлияет на качество как статистической обработки, так и машинного обучения (или даже не позволит их выполнить). В этом разделе я займусь именно подготовкой данных.
Подготовка данных включает, но не ограничивается, следующие элементы:
1) проверка правильности формирования индекса, наименования столбцов (признаков). Например, может быть обнаружено, что в наименовании столбцов есть лишние пробелы;
2) проверка типа данных. Например, численные данные могут быть отмечены как объекты или наоборот;
3) поиск дубликатов;
4) очистка строковых данных от лишних символов. Например, наличие слэша там, где это очевидно неуместно;
5) обработка значений, которые очевидно являются ошибочными. Например, в столбце с количеством страниц указан жанр книги и т.п.;
6) создание новых признаков. Например, по значениям двух уже имеющихся столбцов можно создать третий;
7) укрупнение категорий в категориальных признаках;
Предупреждение об источнике данных
Источник данных находится на Kaggle. Мне неизвестна процедура, которую применял автор для сбора данных. Поэтому всегда надо помнить, что особенности именно данного набора могут оказать влияние на выводы. Идеально было бы самостоятельно собрать данные или использовать дополнительно иные сборки данных, но пока в этой методичке такая задача не стоит.
Почему при таких ограничениях я выбрал именно данный набор? Как я указывал выше, прежде всего, надо основываться на действительности, чтобы понять данные. А значит я должен разбираться или хотя бы понимать те объекты, тот предмет, которого касаются данные. Так как я много читаю, полагаю, что неплохо понимаю, за что можно поставить книге ту или иную оценку, как на это влияет количество страниц и прочее. Поэтому я выбрал именно эти данные.
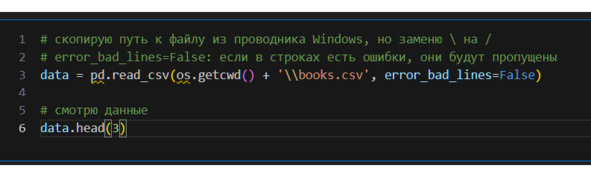
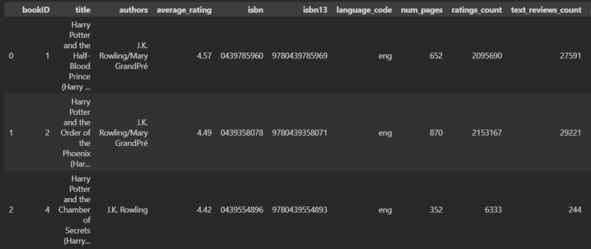
Вижу, что данные можно разбить на две категории:
1) сведения о книге (название, автор, isbn, язык, количество страниц, дата публикации и издательство);
2) сведения о реакции читателей (средний рейтинг, количество отзывов, количество оценок).
Данные рассказывают не просто про книгу и не просто про реакцию на книгу, а про реакцию читателей, измеренную конкретными признаками, на книгу, также измеренную конкретными признаками. Если у меня нет специального задания по анализу, то я могу наметить стратегию исследования по имеющимся признакам. Так, например, может быть интересно, каким книгам чаще ставят положительные оценки? как зависит оценка книги от количества страниц в ней?
Сформулирую для себя общую цель – изучить от чего зависит оценка книги.
Таблица задает две оси: вертикальная – наблюдения, горизонтальная – признаки.
Метка для наблюдений – индекс, метка для признаков – название признаков (название столбцов). Поэтому, естественно, что подготовка данных должна начинаться с обследования меток. Однако индекс формируется автоматически в порядке возрастания от 0 до n (это поведение по умолчанию можно изменить). Названия столбцов были предоставлены вместе с данными, поэтому их-то отдельно и надо обследовать.
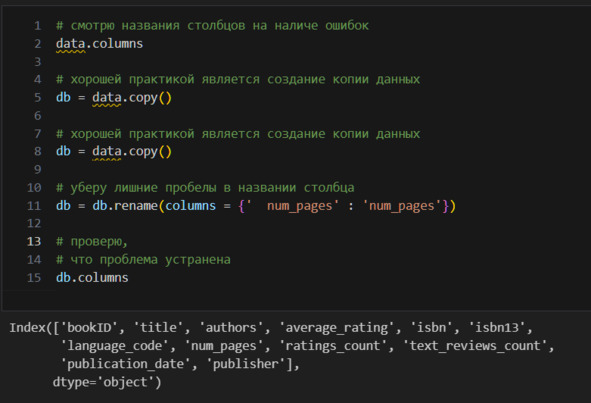
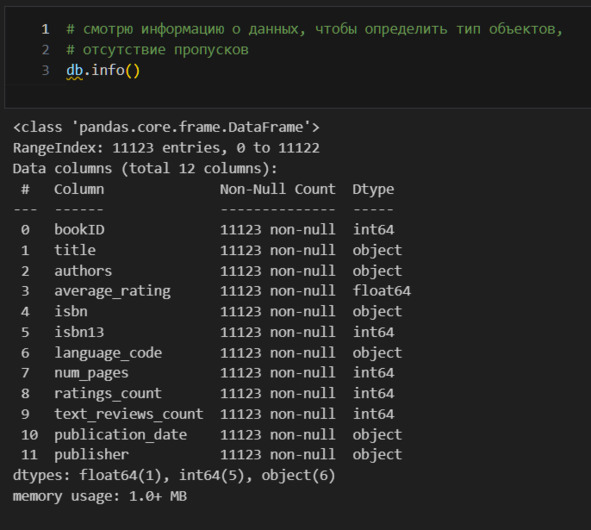
Вижу, что есть 12 признаков (нумерация начинается с 0 и продолжается до 11) и 11123 наблюдений (строк). Пропусков нет (количество объектов по столбцам одинаковое). Индекс у нас это RangeIndex. По типам данных заметно две проблемы. isbn помечен как объект, а isbn13 как int64. Кроме того, publication_date помечен как объект, хотя это очевидно дата. Изменю тип данных.
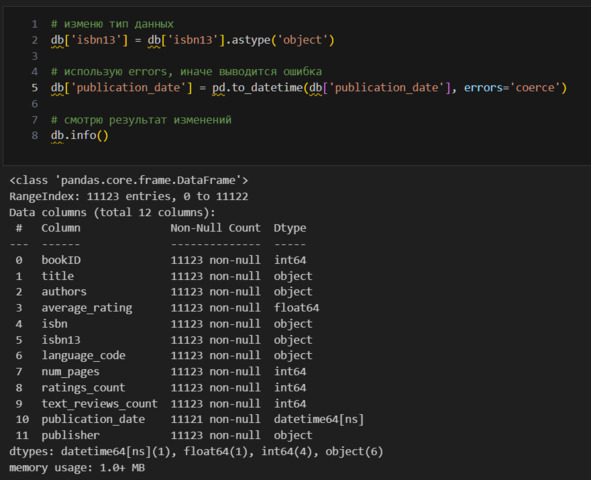
Вижу, что в publication_date появилось два пропущенных значения. Так как подобных строк всего две, я могу их удалить.
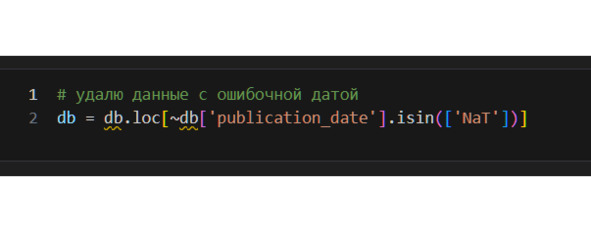
Запись выше надо читать так. В таблице db выбрать только те строки, у которых в столбце «publication_date» нет значения NaT. Значок тильды ~ означает «не». Метод isin проверяет наличие указанных данных в ячейке.
Здесь также важно, что я могу взять изначальную таблицу, отфильтровать ее, как мне это необходимо, а затем заменить изначальную таблицу отфильтрованной. Другими словами, изначально у меня была таблица db, после изменений я получаю таблицу с тем же названием db, но уже отфильтрованную.
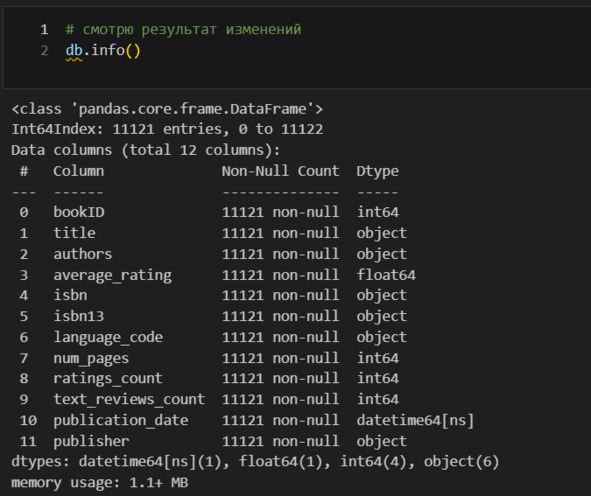
Теперь я должен заняться дубликатами строк. Я могу искать либо полные дубликаты (данные в каждом столбце для строки полностью совпадают), либо искать дубликаты выборочно. Здесь надо обратить внимание, что isbn является уникальным идентификатором каждой изданной книги. Поэтому логично искать дубликаты только по этому признаку, так как книги вполне могут совпадать по иным признакам и это нормально.
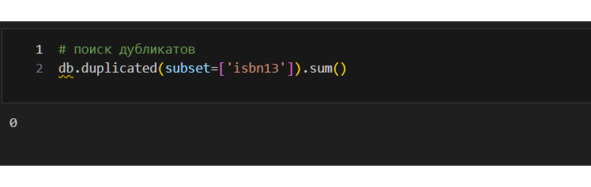
Дубликатов по isbn13 нет. Но все-таки посмотрю дубликаты по названию и имени автора.
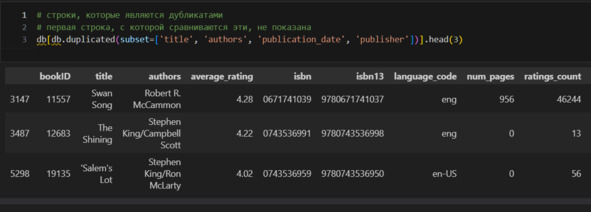
Такой подход позволяет понять, почему могут совпадать имя автора и название при различных isbn. Вижу, что, как правило, такие дубликаты – это аудиокниги. С этим придется разобраться отдельно. Для начала посмотрю, есть ли нулевое количество страниц у книг.
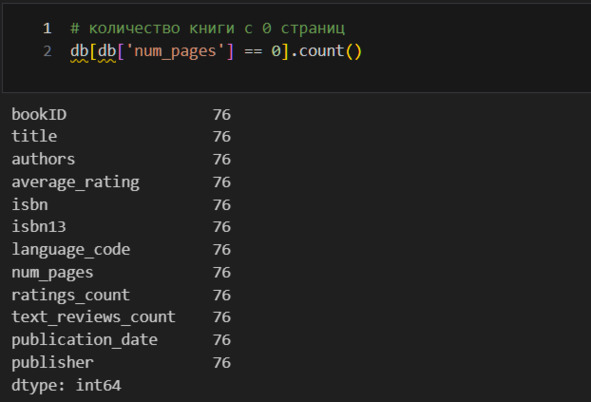
Таких книг 76. Что их объединяет? Посмотрю издательства.
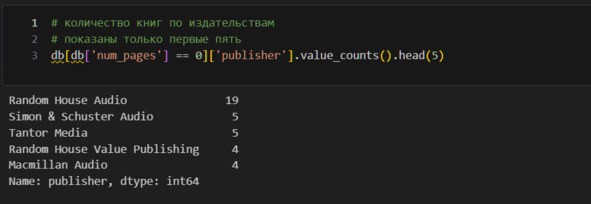
Вижу, что в основном это издательства, которые выпускают аудиокниги. Это логично. Если у книги нет страниц, то это просто аудиокнига. Но посмотрим количество страниц для тех книг, которые выпускали эти издательства.
Код выше весьма любопытен. Как его прочитать? Берем таблицу db. В этой таблице ищем такие строки, в которых столбец равен 0. Далее, в отфильтрованной таким образом таблице, берем столбец ’publisher’. После этого вызываем value_counts для подсчета количества и head для ограничения вывода результатов.
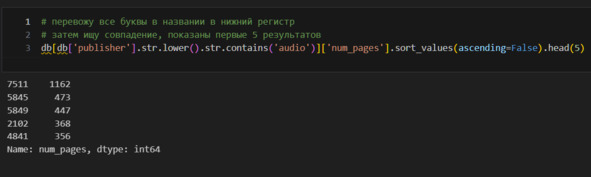
Вижу, что аудиоиздательства издают нечто, что имеет страницы, даже 1162 страницы! Посмотрю на это.
*Заметка к коду*
Код выше очень похож на предыдущий и может быть аналогично прочитан. Однако обращает внимание, что при первоначальной фильтрации таблицы я могу добавить дополнительные методы, например str и т. п.
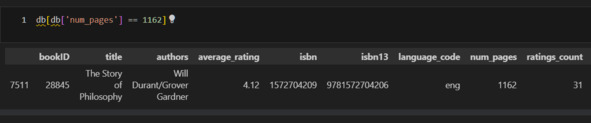
В интернете, например, на сайте Amazon, можно обнаружить эту книгу. И она оказывается аудиокнигой! Таким образом, количество «страниц» еще не говорит нам, что это бумажная книга. Это может быть, например, вес дисков. Более верный признак – это именно издательство. Как же поступить? Ведь сравнить книги аудио и бумажные по количеству страниц не получится. Следовательно, в одном признаке смешаны различные числа – количество страниц и вес дисков. Удалю все аудиокниги, но сначала сравню оценки по бумажным и аудиокнигам.
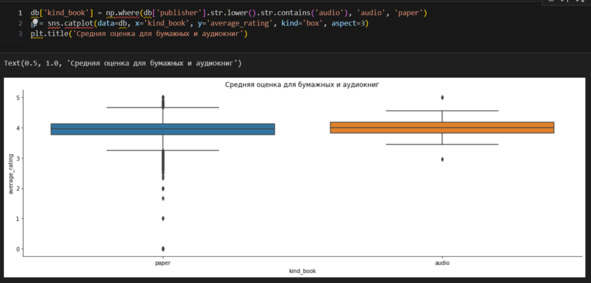
Вижу, что медиана не отличается, хотя разброс оценок для бумажных книг больше, чем для аудиокниг. Удалю вспомогательный признак, а также все аудиокниги. Надо учитывать, что такой подход, когда сравниваются две категории книг по графикам, является довольно грубым. Здесь бы стоило применить, например, t-тест. Но у меня нет специальной задачи исследовать аудио- и бумажные книги, поэтому ограничусь графиками.
*Заметка к коду*
Как прочитать np. where? Здесь я беру исходные данные признака, нахожу один из них, например названия с «audio», и присваиваю значение «audio», а если это не выполняется, то присваиваю значение «paper».
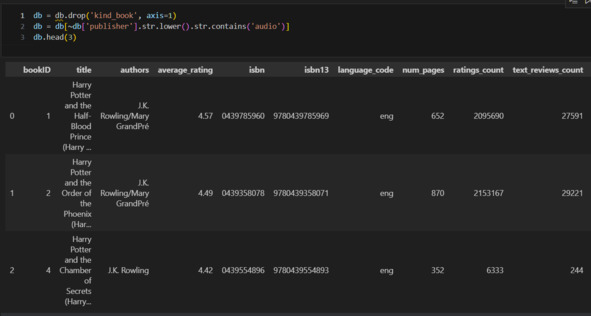
Еще раз посмотрю на таблицу, но выберу только количество страниц до 10. Посмотрю издательства.
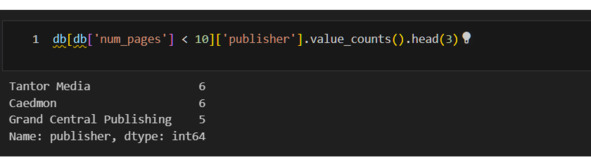
Если изучить полный список, то можно заметить, что там есть издательства Listening Library и ряд других, которые очевидно выпускают аудиокниги. Прихожу к выводу, что книги с количеством страниц 10 – это аудиокниги. Удалю их.
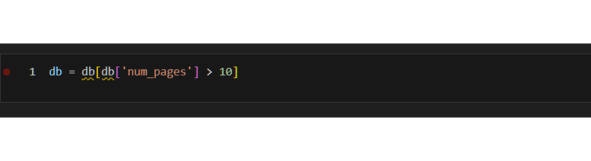
Добавлю два дополнительных признака в таблицу:
1) десятилетие, в котором вышла книга,
2) квартал, в котором вышла книга.
Это называется конструированием признаков, исходя из целей исследования. Специальных целей передо мной не ставили, я ищу их для себя сам. Меня будет интересовать, как распределяются книги по десятилетиям и в какой квартал их чаще выпускают. Почему именно эти признаки? Потому что десятилетия отражают развитие рынка книготорговли, изменение форматов и т. п. Кварталы же зависят от праздников, сезонности, что также может оказывать влияние на оценку книги.
Конструирование признаков возможно двумя путями:
1) самостоятельно определить новый признак,
2) признак создается автоматически, например простым возведением каждого числового признака в квадрат или перемножением каждой пары таких признаков.
Если затруднительно самостоятельно определить признаки, которые было бы интересно изучить, то можно применить второй метод. В этом случае можно и не создавать признаки на этапе обработки данных, можно использовать специальные методы, например полиномиальную регрессию.
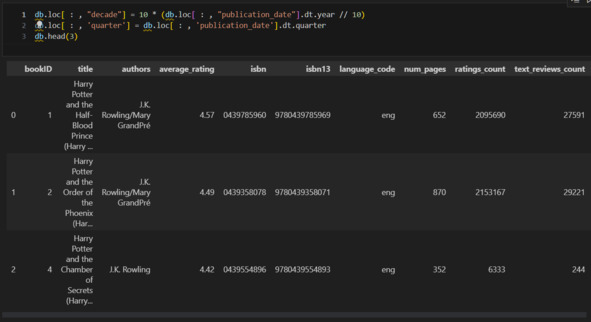
Теперь посмотрю на признак authors. Вижу, что здесь есть случаи, когда указано несколько имен через /. Сколько таких случаев?
*Заметка к коду*
Чтобы получить значение десятилетия, я использовал код 10 * (db. loc [:, «publication_date»].dt. year // 10). Почему? В этом коде я сначала делю год на 10, причем оставляю только целую часть. Например, если год 2001, то получаю 200. А затем уже умножаю на 10 это «целое» число, что и дает декаду.
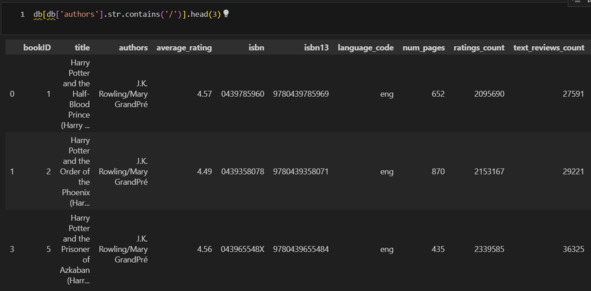
Из примеров видно, что, как правило, через слеш указаны переводчики. Однако возможны и другие ситуации. Это могут быть соавторы или вариант написания имени. Без дополнительного исследования внешних источников это определить нельзя. В этой ситуации можно сделать следующее. Заменю слеш на запятую. Создам колонку tra_co (переводчик или соавтор) и присвою 1 тем случаям, где есть запятая, и 0 остальным.
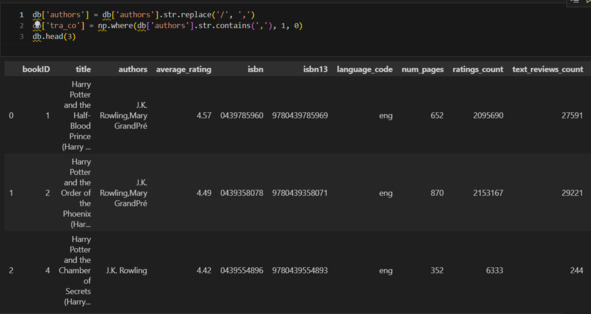
Теперь разберусь с книгами, у которых слишком большие значения количества страниц. Посмотрю на них повнимательнее.
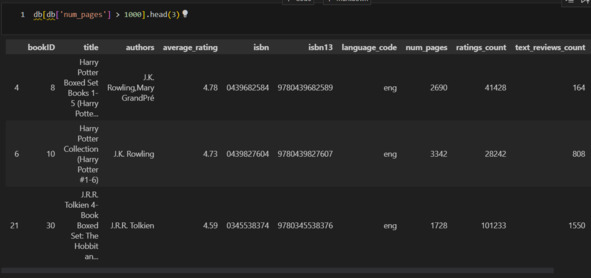
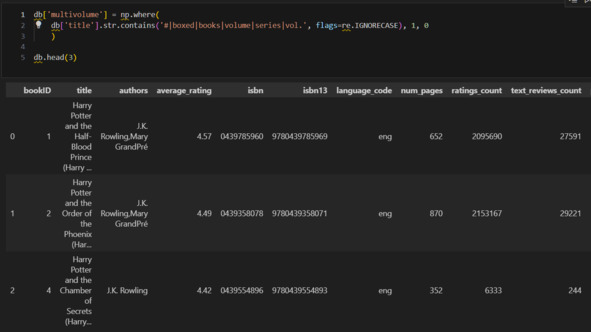
Как правило, книги с количеством страниц больше 1000 – это многотомные издания. Очевидно, что просто убрать такие книги, как я сделал с книгами, у которых было 0 страниц, нельзя. Что же тогда? Я должен найти все такие книги и пометить их. Для этого надо определить маркеры, которые позволят найти многотомные издания. Уже представленный выше список дает идеи:
1) книги с наличием знака #,
2) книги со словами Boxed Set.
Кроме того, под подозрением все книги со словами «books», «vol.», «volume», «series».
См. хорошее руководство по регулярным выражениям https://developers.google.com/edu/python/regular-expressions.
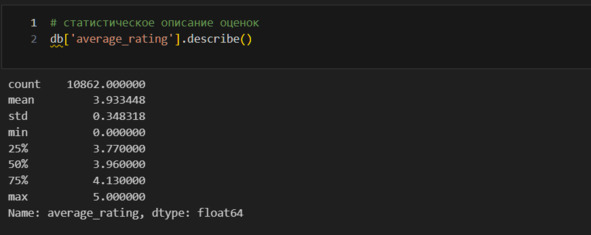
Минимальная оценка это 0. Но на сайте нельзя поставить такую оценку. Поэтому 0 означает отсутствие оценки, то есть это категориальный признак, который «пробрался» в числовой. Посмотрю количество и удалю, так как такое смешение недопустимо. Однако, если оценка 0, но количество оценок не 0, то это просто ошибка. Проверю это.
Удалю редкие категории. Для этого можно применить следующий код к каждой категориальной переменной.
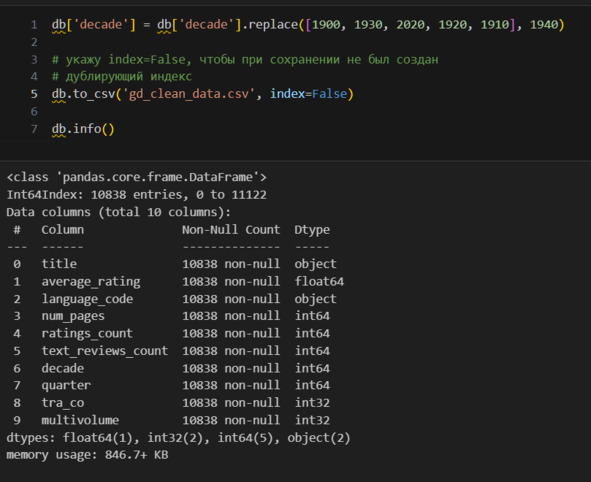
Здесь не привожу вывод по каждой категории. Однако общий вывод такой: редкие категории встречаются в **decade**, поэтому объединю все года, у которых менее 20 значений в год 1940.
Почему необходимо укрупнений категорий? Потому что маленькие категории несут мало информации, в то же время увеличение размерности данных ведет к тому, что известно как «проклятие размерности».
Глава 2. Статистическое исследование

Введение
Статистическое исследование данных может быть осуществлено двумя основными способами – это либо классический статистический анализ, либо то, что известно как Exploratory Data Analysis (EDA).
Понять отличие можно по следующим схемам.
Классический анализ идет по схеме: Проблема => Данные => Модель => Анализ => Выводы. В свою очередь EDA строится чуть иначе: Проблема => Данные => Анализ => Модель => Выводы.