
Data Science для новичков
Отличие в том, что в классическом подходе сначала идет модель, а затем анализ, а в EDA сначала анализ данных, а затем уже модель. Другими словами, классический анализ как бы навязывает определенную модель данным, в то время как EDA пытается по данным определить, какая модель больше подходит.
Как итог, в EDA больше используют графики, например гистограммы, ящики с усами и т. п. Классический же подход больше использует тесты, проверку гипотез. Например, это ANOVA, t-tests, chi-squared tests, и F-tests.
В этой методичке я использую элементы каждого из подходов. Поэтому я провожу деление всех способов статистического анализа на:
1) количественные (тестирование гипотез, анализ распределения и прочее);
2) графические (гистограммы, скаттерплоты и прочее).
Вот типичные вопросы, на которые старается ответить статистический анализ данных:
1) Какие значения являются типичными?
2) Каким распределением можно описать данные?
3) Как данный фактор влияет на целевой признак?
4) Какие факторы самые важные?
5) Есть ли в данных выбросы?
Важно всегда помнить, что большинство способов статанализа предполагает, что данные получены случайным образом. Если это предположение не выполняется, то результаты тестов, модели перестают быть достоверными.
Теперь еще раз, но уже больше с привязкой к данным. Статанализ (математическая статистика) работает с данными. Но что такое данные? Как правило, данные – это совокупность строк и столбцов. Пускай их будет только два. Вот такие например.
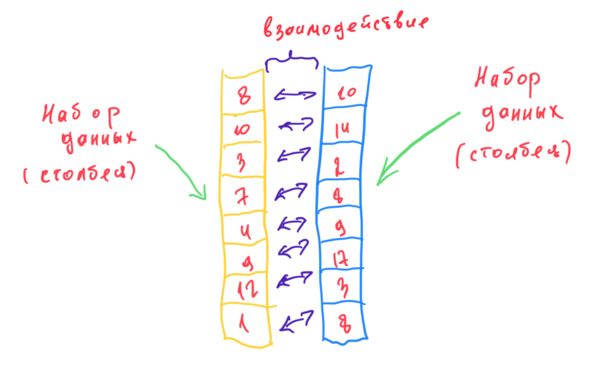
Что я могу с этим сделать? Как я могу «раскрутить», «покрутить» эти данные? Я могу, например, заинтересоваться только одним из столбцов. Какое среднее значение? А как отличаются от среднего фактические значения? Насколько вероятно появление одного из значений или нового значения? Но меня может заинтересовать и взаимодействие столбцов. Если растет значение в одном столбце, то растет ли значение в другом? Связаны ли эти столбцы? И если связаны, то насколько сильно? И вот еще что важно. Данные, которые я здесь использую, – это только небольшая выборка всех книг, изданных в мире. Поэтому те данные, которые видны выше на рисунке, – это тоже только выборка из генеральной совокупности. А раз так, то стоит также задача оценить по этим выборочным данным генеральную совокупность (или же наоборот, если известны характеристики генеральной совокупности).
Все это можно сделать со столбцами. И математическая статистика как раз пытается ответить на вопросы выше. Итак, математическая статистика:
1. дает математическое описание набора данных (столбца);
2. определяет вид распределения (для определения вероятности новых значений и не только);
3. дает описание того, как взаимодействуют два и более набора данных (столбцы).
Глядя на рисунок выше надо также учитывать, что, как правило, набор данных далеко не отражает всех данных. Например, в данных приведена только небольшая выборка из всех книг. Это ставит перед математической статистикой дополнительные задачи.
В качестве учебника по математической статистике я рекомендую учебник Гмурмана «Теория вероятностей и математическая статистика» (далее – Гмурман). Вот как этот автор описывает, чем занимается матстат (стр. 187 Гмурман):
1. «оценка неизвестной вероятности события; оценка неизвестной функции распределения; оценка параметров распределения, вид которого неизвестен; оценка зависимости случайной величины от одной или нескольких случайных величин и др.»;
2. «проверка статистических гипотез о виде неизвестного распределения или о величине параметров распределения, вид которого неизвестен».
Некоторые важные концепции математической статистики
«Математическим ожиданием дискретной случайной величины называют сумму произведений всех ее возможных значений на их вероятности» (Гмурман, стр. 76).
Математическое ожидание примерно равно среднему значению. Причем «математическое ожидание приближенно равно (тем точнее, чем больше число испытаний) среднему арифметическому наблюдаемых значений случайной величины» (Гмурман, стр. 78). Поэтому – чем больше данных, тем лучше.
Понятие «центрированная величина» возникает из-за того, что такая величина получается как «разность между случайной величиной и ее математическим ожиданием» (Гмурман, стр. 87). Само же математическое ожидание принимается за центр распределения набора данных.
«Дисперсией (рассениянием) дискретной случайной величины называют математическое ожидание квадрата отклонения случайной величины от ее математического ожидания» (Гмурман, стр. 88).
Вот формула:
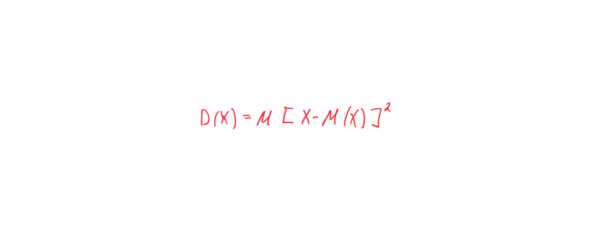
В этой записи надо учитывать, что прописная X означает весь набор данных, например 3, 8, 19 и т. д. То есть формулу надо читать так, что из каждого из единичных значений X производится вычитание. Например, вычитаем матожидание из 3, из 8, из 19 и т. д.
Подробнее про компоненты дисперсии можно посмотреть в учебнике для инженеров [7.4.4. What are variance components?] (https://www.itl.nist.gov/div898/handbook/prc/section4/)
Совет
«В тех случаях, когда желательно, чтобы оценка рассеяния имела размерность случайной величины, вычисляют среднее квадратическое отклонение, а не дисперсию. Например, если X выражается в линейных метрах, то среднее квадратическое отклонение будет также выражаться в линейных метрах, а дисперсия – в квадратных метрах» (Гмурман, стр. 94).
Теперь разберу концепцию начальных и центральных моментов, очень важную для математической статистики. Для этого возьму произвольный набор данных, в котором для каждого значения известна вероятность.

Вот как считается математическое ожидание:
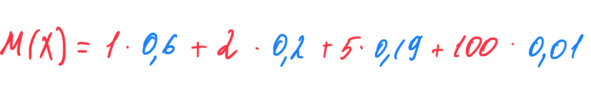
Еще раз, важно запомнить, что в записи M (X) вот это X означает случайную величину, скажем измерения линейкой. Отдельное значение из этой случайной величины (верхняя строка в таблице выше) обозначается как x. Когда же есть запись с X, то имеются ввиду все значения x.
Итак, теперь возведу в квадрат случайную величину.

Вероятность не изменилась. Это можно понять так. Возведением в квадрат изменяется масштаб, но не вероятность. Каким будет математическое ожидание?

Какой вывод я могу сделать? Второе математическое ожидание гораздо больше первого. Почему? Потому что в первом случае я умножал вероятность 0,01 на 100, а во втором ту же вероятность 0,01 я умножил уже на 10000. Это позволило «лучше учесть влияние на математическое ожидание того возможного значения, которое велико и имеет малую вероятность» (Гмурман, 98). В зависимости от количества подобных величин, того, насколько они «маленькие», может потребоваться возведение не только в квадрат, но и в более высокие степени.
Начальным моментом порядка k называют математическое ожидание случайной величины, возведенной в степень (k, это может быть и степень k=1). Центральным моментом порядка k называют математическое ожидание степени разности между случайной величиной и математическим ожиданием случайной величины.
[Не так строго понять это можно следующим образом. Сначала я нахожу среднее значение набора данных (это будет математическим ожиданием). Затем я вычитаю из каждого значения набора данных это среднее значение. У меня получится новый набор данных. Теперь я могу найти среднее этого нового набора данных (это также будет математическим ожиданием, но для нового набора данных).]
Применение закона больших чисел разъясняется в главе 9 Гмурмана. Здесь я не буду останавливаться на этом подробнее.
Выборкой «называют совокупность случайно отобранных объектов» (Гмурман, стр. 188). Выборка осуществляется по специальным правилам. Подробнее об этом можно узнать здесь (https://www.itl.nist.gov/div898/handbook/ppc/section3/ppc333.htm), а также в [7.2.4.2. Sample sizes required] (https://www.itl.nist.gov/div898/handbook/prc/section2/prc242.htm).
Генеральной совокупностью «называют совокупность объектов, из которых производится выборка» (там же).
В теории вероятностей
«под распределением понимают соответствие между возможными значениями случайной величины и их вероятностями, а в математической статистике – соответствие между наблюдаемыми вариантами и их частотами или относительными частотами» (Гмурман, стр. 192).
В случае, который разбираю я на данных, имеющиеся у меня данные – это выборка, по которой я хочу оценить генеральную совокупность – все книги на сайте.
Вот как это работает.
«Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Естественно возникает задача оценки параметров, которыми определяется это распределение. Например, если наперед известно, что изучаемый признак распределен в генеральной совокупности нормально, то необходимо оценить (приближенно найти) математическое ожидание и среднее квадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение; если же есть основания считать, что признак имеет, например, распределение Пуассона, то необходимо оценить параметр лямбда, которым это распределение определяется» (Гмурман, стр. 197).
Например, генеральная совокупность – все книги на сайте. Параметр, который нас интересует, – это количество страниц. Количество страниц в каждой книге – это и есть количественный признак генеральной совокупности.
Итак, есть оцениваемые параметры, а есть статистические оценки таких параметров. Такие оценки должны соответствовать определенным требованиям. Буду делать выборки из генеральной совокупности книг. Для каждой выборки оценю параметр, например среднее значение страниц в книге. Каждая такая выборка даст свое значение, совокупность таких значений и будет набором данных, у которого также может быть математическое ожидание (среднее). Отсюда появляется понятие несмещенной оценки.
«Несмещенной называют статистическую оценку, математическое ожидание которой равно оцениваемому параметру при любом объеме выборки» (Гмурман стр. 198).
Соответственно, если оценка не соответствует указанным свойствам, то она является смещенной.
Вот еще пояснение из учебника «Теория и методы эконометрики», авторов Дэвидсона, Мак-Кинона (далее – Дэвидсон), который я также рекомендую.
«На интуитивном уровне это означает, что если мы станем использовать метод оценивания, дающий несмещенные оценки для расчета оценок по очень большому числу выборок, то среднее значение получаемых с его помощью оценок будет приближаться к оцениваемой величине. При прочих равных статистических свойствах двух методов оценивания несмещенный метод всегда предпочтительнее смещенного».
Однако, даже если оценка является несмещенной, все-таки дисперсия в наборе данных, на основе которых посчитана оценка, может быть большой. Поэтому еще одним требованием к оценке является эффективность.
«Эффективной называют статистическую оценку, которая (при заданном объеме выборки n) имеет наименьшую возможную дисперсию» (Гмурман, стр. 199).
Кроме того, если количество объектов в выборке стремится к бесконечности, то устанавливают требование о состоятельности.
«Состоятельной называют статистическую оценку, которая при [стремлении количества объектов к бесконечности] стремится по вероятности к оцениваемому параметру».
Про доверительные интервалы см. параграфы 14—16 гл. 16 Гмурмана.
Отдельные важные концепции математической статистики можно изучить по следующим ссылкам:
1. Про виды распределений – гл. 4 Дэвидсона. Хорошая галерея графиков с видами распределений находится здесь (https://www.itl.nist.gov/div898/handbook/eda/section3/eda366.htm), там же можно найти компактное описание распределений. Еще одно описание можно найти в том же учебнике [8.1.6. What are the basic lifetime distribution models used for non-repairable populations?] (https://www.itl.nist.gov/div898/handbook/apr/section1/apr16.htm). Почему важно правильно определить вид распределения? Потому что от этого зависит как применение тестов, так и проверка гипотез. Распределения также применяются для определения доверительных интервалов.
Подробнее остановлюсь на нормальном распределении.
Нормальное распределение определяется двумя параметрами: математическим ожиданием (a) и средним квадратическим отклонением. Про график нормального распределения, который выглядит как колокол и близок к приведенному выше, нужно помнить три правила:
1) «Изменение величины параметра a (математического ожидания) не изменяет форму нормальной кривой, а приводит лишь к ее сдвигу вдоль оси Ox: вправо, если a возрастает, и влево, если a убывает» (Гмурман, стр. 131).
2) «С возрастанием параметра средего квадратического отклонения максимальная ордината нормальной кривой убывает, а сама кривая становится более пологой, то есть сжимается к оси Ox; при убывании – нормальная кривая становится более „островершинной“ и растягивается в положительном направлении оси Oy» (там же).
3) Площадь под кривой всегда остается равной 1.
[Математическое ожидание показывает среднее значение в наборе. Поэтому, если такое среднее значение «двигается», то двигается и график, который построен ведь вокруг этого среднего значения. Среднее отклонение показывает разброс отдельных значений данных вокруг среднего. Если такой разброс увеличивается или уменьшается, то соответственно изменяется и график.]
В связи с нормальным распределением есть центральная предельная теорема (теорема Ляпунова). Вот ее формулировка:
«Если случайная величина X представляет собой сумму очень большого числа взаимно независимых случайных величин, влияние каждой из которых на всю сумму ничтожно мало, то X имеет распределение, близкое к нормальному» (Гмурман, стр. 135).
Таким образом, все распределения оцениваются применительно к нормальному. Поэтому нужны инструменты, которые бы показывали, что данное распределение отличается и насколько отличается от нормального. Для этого используют показатели эксцесса и ассиметрии. Для нормального распределения ассиметрия и эксцесс равны нулю. Если у данного набора эти значения сильно больше 0, то его распределение тем сильнее отличается от нормального, и наоборот. Ниже я покажу также иные способы определения нормальности распределения.
2. Проклятие размерности – гл. 2 «Основы статистического обучения» Тревор Хасти, Роберт Тибширани, Джером Фридман. Важность этой проблемы можно понять из следующей цитаты тех же авторов:
«С увеличением размерности сложность функций многих переменных может расти экспоненциально, и если мы хотим иметь возможность оценивать такие функции с той же точностью, что в пространствах малой размерности, то нам необходимо, чтобы размер нашего обучающего множества также рос экспоненциально» (стр. 24 английского издания).
Здесь же объясняется разложение среднеквадратической ошибки (MSE) на дисперсию и смещение. Привожу только вывод формулы для примера:
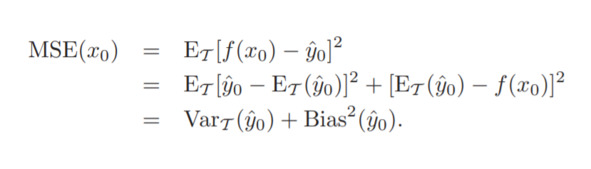
В учебнике Машинное обучение указывается следующее.
«В контексте моделей МО [машинного обучения] дисперсия измеряет постоянство (либо изменчивость) прогноза модели для классификации отдельного образца при многократном обучении модели, например, на разных подмножествах обучающего набора данных. Мы можем сказать, что модель чувствительна к случайности обучающих данных. Напротив, смещение измеряет, насколько далеко прогнозы находятся от коррективных значений в целом при многократном обучении модели на разных обучающих наборах данных; смещение представляет собой меру систематической ошибки, которая не является результатом случайности».
3. Z-оценка часто используется, например для определения выбросов. Вот формула для расчета:
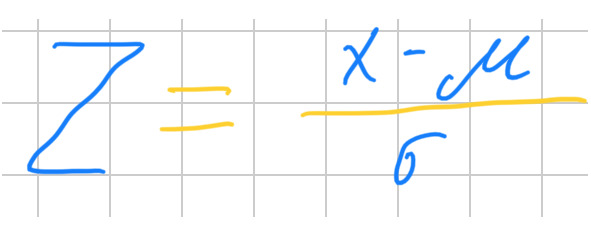
В этой формуле: x – это единичное значение из набора данных; мю – среднее набора данных; сигма – стандартное отклонение.
4. Доверительные интервалы, см. подробнее в [1.3.5.2. Confidence Limits for the Mean] (https://www.itl.nist.gov/div898/handbook/eda/section3/eda352.htm)
5. Дисперсия, ковариация, корреляция. Разница между дисперсией, ковариацией и корреляцией:
1) дисперсия – это мера изменчивости конкретного значения от среднего значения по всему набору данных;
2) ковариация – это мера взаимосвязи между изменчивостью двух переменных. Ковариация зависит от масштаба, поскольку она не стандартизирована;
3) корреляция – это связь между изменчивостью двух переменных. Корреляция стандартизирована, что делает ее не зависящей от масштаба.
Справочное руководство [Engineering statistics handbook] (https://www.itl.nist.gov/div898/handbook/eda/eda.htm) содержит пример схемы анализа данных:
1. Посчитать базовые статистики:
a) среднее;
b) стандартное отклонение. При этом надо помнить следующие эмпирические правила. Приблизительно 60—78% данных находятся в пределах одного стандартного отклонения от среднего. Приблизительно 90—98% данных находятся в пределах двух стандартных отклонений от среднего. Более 99% данных находятся в пределах трех стандартных отклонений от среднего;
c) коэффициент автокорреляции для проверки данных на случайность;
d) коэффициенты корреляции, коэффициенты, показывающие, что распределение является нормальным, например Wilk-Shapiro test.
2. Построить график для нормального распределения.
3. Линейная аппроксимация данных в зависимости от времени для оценки дрейфа (тест на фиксированное положение).
4. Тест Барлетта для дисперсии.
5. Критерий Anderson-Darling для нормального распределения.
6. Теста Граббса для определения выбросов.
Можно ознакомиться с примером анализа по указанной схеме [1.4.2.1.3. Quantitative Output and Interpretation] (https://www.itl.nist.gov/div898/handbook/eda/section4/eda4213.htm)
Загрузка и описание данных
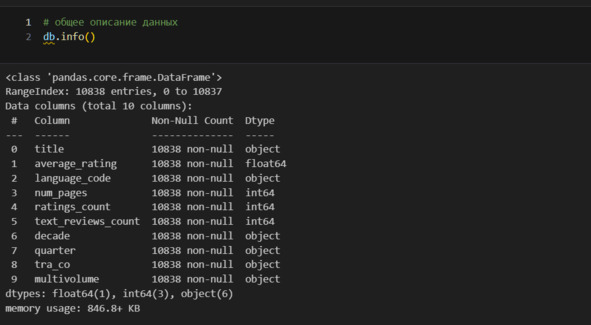
Теперь мне надо определить, что я хочу узнать из данных. Специальных целей передо мной никто не ставил, поэтому определю их самостоятельно. Что интересного могут рассказать данные? Здесь же я сразу укажу, какими методами буду решать эти задачи. Надо помнить, что не всегда можно заранее знать, какой метод подойдет. Например, мне нужно сначала проверить распределение на нормальность, чтобы применить корреляцию. Поэтому в этот список можно вносить изменения по ходу анализа.
Как указывалось ранее, я могу разделить статистическое обследование на изучение набора данных и изучение отношений между наборами данных. С учетом этого и разделю задачи.
Изучение каждой группы данных отдельно:
* Характеристики центрального положения для количественных признаков. Метод describe;
* Характеристики категориальных данных. Тот же describe;
* Какой тип распределения у средних оценок для книг, для количества страниц в книгах? (здесь не рассматривается).
Изучение отношений между группами данных:
* Как распределены книги по десятилетиям? Использую график;
* Какие книги получили высокие оценки? Использую график;
* Как распределены книги по кварталам? Использую график;
* Какие книги чаще всего издавались в рамках набора данных? Использую график;
* Если у книги есть соавтор или переводчик, как это влияет на оценку? Использую дисперсионный анализ;
* От каких признаков зависит оценка книги? Использую корреляцию, дисперсионный анализ;
* Какие слова чаще всего используются в названии книги? Использую NLTK.
Начну с характеристик центрального положения.
Я буду для простоты писать «статистика» вместо «математическая статистика», «статистический анализ», хотя строго говоря это не одно и то же.
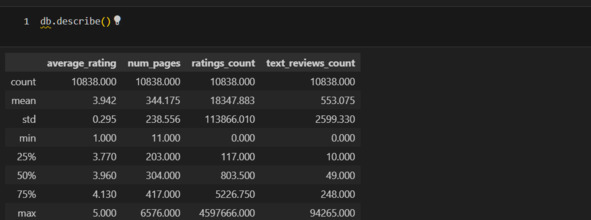
Уже в этой таблице можно видеть важнейшие концепции статистики. Выше я писал, что статистика должна описывать наборы данных и их взамиодействие. Здесь мы видим описание именно наборов данных, взаимодействие будет позже.
В таблице дается описание для четерых численных признаков: average_rating, num_pages, ratings_count, text_reviews_count. Остальные признаки являются категориальными и в эту таблицу не попали, но ниже я также рассмотрю и эти признаки. Пока продолжу изучать таблицу. Для каждого признака, например для text_reviews_count, приведен ряд характеристик (метрик): count, mean и т. д. Об этих характеристиках можно говорить как о характеристиках центрального положения. Откуда пошло такое выражение? Это показано на рисунке ниже
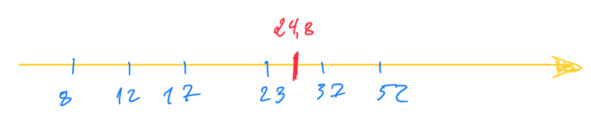
Среднее значение 24,8 есть характеристика центрального положения, так как фактические данные (8,12…52) расположены вокруг этого среднего. Отсюда же видно, например, что можно посчитать расстояние от центра до каждого значения, что приводит к дисперсии и стандартному отклонению.
В чем смысл таких характеристик? У меня есть набор данных. Я хочу его как-то охарактеризовать. Зачем? Во-первых, чтобы лучше понять объект, который описывается этими данными. Например, про среднюю оценку я теперь знаю, что она у книг составляет 3.9. Во-вторых, чтобы уметь предсказывать будущие события. Например, я хочу знать, а какую оценку поставят новой книге. При прочих равных можно считать, что эта оценка будет близка к среднему значению. Но так как точно сказать этого нельзя, то меня интересует, в каком диапазоне может быть эта оценка, здесь помогает std. Минимум и максимум определяют, в каких границах расположены оценки. Благодаря этому я достоверно знаю, что оценка не может быть меньше 1 и не может быть больше 5. А к чему же все эти проценты: 25%, 50%, 75%? Эти проценты показывают следующее: 25% оценок ниже чем 3.77, 50% оценок ниже чем 3.96 и т. д. Это условно можно представить как вероятность: вероятность того, что оценка книги будет 3.77 составляет 25%.
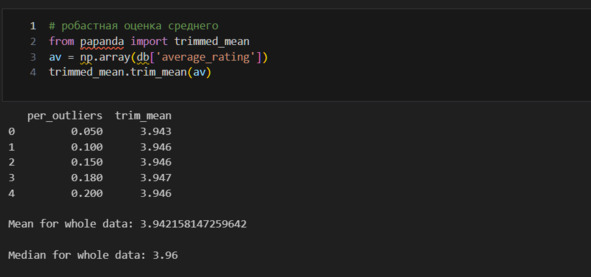
Так я изучаю характеристики каждого набора данных. Замечаю, что в num_pages, ratings_count, text_reviews_count есть странности. Так, например, среднее в num_pages составляет 344, но максимальное значение 6576. Говоря иначе, в среднем в одной книге 344 страницы, но есть книга, у которой 6576 страниц. Это может свидетельствовать о выбросах в данных. Непосредственно о выбросах я расскажу позже, но уже сейчас надо это учитывать. Если я предполагаю, что в моем наборе данных есть выбросы, то я могу использовать робастные, то есть устойчивые к выбросам методы оценки среднего. Я могу найти такую оценку с помощью библиотеки papanda.
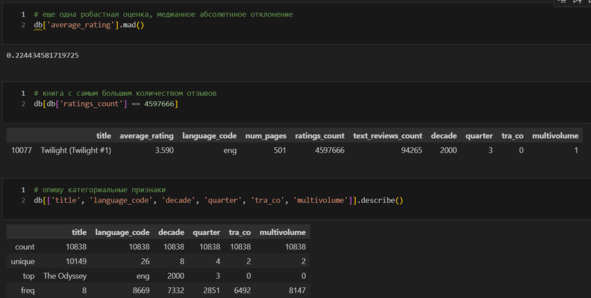
Вижу, что в данных 10149 уникальных названий книг из 10838.
Чаще всего встречается The Iliad, 8 раз. Однако надо учитывать, что есть еще несколько книг, которые в изданы 8 раз. Например, Анна Каренина. Поэтому The Iliad можно считать случайным.
26 различных языков, самый частый eng, 8669.
Декад всего 13, самая частая – это 2000, на которую приходится 7332.
Кварталов 4, самый частый 3, на него приходится 2851 книга.
Категорий «с соавтором, переводчиком» и без две: либо переводчик или соавтор есть, либо их нет. Чаще всего их нет, таких случаев 6492.
Аналогично, либо книга является частью многотомного издания и тогда в колонке multivolume стоит 1, либо не является частью такого издания и тогда получается 0. Вижу, что в наборе, как правило, не многотомные издания (их 8147).
Опять-таки, а зачем мне эти знания? Во-первых, чтобы лучше понимать природу того объекта, который исследуется. В каком году книге чаще выходили? А в каком квартале? С каким названием? Все это может помочь понять не только, что выпускают издательства, но и вкусы читателей. Во-вторых, категориальные признаки позволяют разбить объекты на группы, скажем можно разбить книги по языку, и уже внутри каждой группы посмотреть оценки, количество страниц. Эта возможность ставит дополнительные задачи. Например, категории не должны быть слишком маленькими, так как невозможно будет доверять результатам. Например, если у меня по какому-то языку только две книги, то определить среднюю я смогу, но эта средняя может быть слишком далека от истинного значения. Надо помнить, что в статистике всегда руководствуются законом больших чисел.