
Нейросети. Обработка естественного языка
5. Затухание градиентов: GRU спроектирована так, чтобы бороться с проблемой затухания градиентов, которая может возникнуть при обучении глубоких RNN. Благодаря воротным механизмам, GRU может регулировать поток информации и избегать слишком быстрого затухания или взрывного увеличения градиентов.
6. Применение: GRU часто применяется в задачах анализа текста, временных рядов и других последовательных данных. Она обеспечивает хорошее соотношение между производительностью и сложностью модели, что делает ее популярным выбором во многих приложениях.
Главное преимущество GRU перед LSTM заключается в более низкой сложности и меньшем количестве параметров, что может быть важно при работе с ограниченными вычислительными ресурсами. Однако, стоит отметить, что LSTM всё равно остается более мощным в решении некоторых сложных задач, требующих учета долгосрочных зависимостей.
Давайте рассмотрим пример кода, в котором используется GRU для анализа временного ряда. В этом примере мы будем использовать библиотеку TensorFlow:
```python
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# Генерируем пример временного ряда (синусоида с шумом)
np.random.seed(0)
n_steps = 100
time = np.linspace(0, 10, n_steps)
series = 0.1 * time + np.sin(time) + np.random.randn(n_steps) * 0.1
# Подготавливаем данные для обучения GRU
n_steps = 30 # количество временных шагов в одной последовательности
n_samples = len(series) – n_steps
X = [series[i:i+n_steps] for i in range(n_samples)]
y = series[n_steps:]
X = np.array(X).reshape(-1, n_steps, 1)
y = np.array(y)
# Создаем модель GRU
model = tf.keras.Sequential([
tf.keras.layers.GRU(10, activation="relu", input_shape=[n_steps, 1]),
tf.keras.layers.Dense(1)
])
# Компилируем модель
model.compile(optimizer="adam", loss="mse")
# Обучаем модель
model.fit(X, y, epochs=10)
# Делаем прогноз на будущее
future_steps = 10
future_x = X[-1, :, :]
future_predictions = []
for _ in range(future_steps):
future_pred = model.predict(future_x.reshape(1, n_steps, 1))
future_predictions.append(future_pred[0, 0])
future_x = np.roll(future_x, shift=-1)
future_x[-1] = future_pred[0, 0]
# Выводим результаты
plt.plot(np.arange(n_steps), X[-1, :, 0], label="Исходные данные")
plt.plot(np.arange(n_steps, n_steps+future_steps), future_predictions, label="Прогноз")
plt.xlabel("Временной шаг")
plt.ylabel("Значение")
plt.legend()
plt.show()
```

В этом коде мы создаем и обучаем модель GRU для анализа временного ряда, а затем делаем прогнозы на будущее. Результаты прогнозирования отображаются на графике вместе с исходными данными.
На результате кода вы увидите график, который содержит две линии:
1. Исходные данные (синяя линия): Это начальная часть временного ряда, который был сгенерирован. В данном случае, это синусоидальная волна с добавленным случайным шумом.
2. Прогноз (оранжевая линия): Это результаты прогноза, сделанные моделью GRU на будущее. Модель обучается на исходных данных и затем пытается предсказать значения временного ряда на заданное количество временных шагов вперед (future_steps).
Из этой визуализации можно оценить, насколько хорошо модель справилась с задачей прогнозирования временного ряда. Оранжевая линия отображает прогнозируемую часть временного ряда на будущее. В зависимости от точности модели и сложности данных, результаты могут быть близкими к исходным данным или иметь некоторую степень погрешности.
GRU может использоваться для анализа и прогнозирования временных рядов, учитывая долгосрочные зависимости в данных.
3. Bidirectional RNN (BiRNN):
Bidirectional RNN (BiRNN) – это архитектура рекуррентных нейронных сетей (RNN), которая позволяет модели использовать информацию из прошлых и будущих состояний в последовательности данных. Это значительно улучшает способность модели к пониманию контекста и делает ее более мощной в анализе последовательных данных.
Вот ключевые особенности и принцип работы Bidirectional RNN:
1. Двунаправленность (Bidirectionality): Основная идея заключается в том, чтобы иметь два набора рекуррентных слоев – один, который проходит последовательность слева направо (forward), и другой, который проходит последовательность справа налево (backward). Это позволяет модели анализировать информацию как в прошлом, так и в будущем относительно текущего временного шага.
2. Объединение информации: После прохождения последовательности в обоих направлениях, информация из обоих наборов рекуррентных слоев объединяется. Обычно это делается путем конкатенации или другой операции объединения. Это создает более богатое представление данных, которое учитывает как контекст слева, так и контекст справа от текущего временного шага.
3. Улучшенное понимание контекста: Благодаря двунаправленному подходу, модель становится более способной понимать широкий контекст данных. Это особенно полезно в задачах, где важны как предыдущие, так и последующие элементы в последовательности, например, в обработке естественного языка (NLP), распознавании речи и анализе временных рядов.
4. Применение: BiRNN может быть успешно применена во многих задачах, включая именнованное сущности извлечение в тексте, машинный перевод, анализ эмоций в тексте, распознавание речи и другие. Всюду где важен контекст, BiRNN может улучшить производительность модели.
Давайте рассмотрим пример задачи, в которой Bidirectional RNN (BiRNN) может быть полезной, а затем проведем подробный разбор.
Задача: Сентимент-анализ текста
Цель задачи: Определить эмоциональную окраску (позитивную, негативную или нейтральную) текстового отзыва о продукте, услуге или событии.
Пример задачи: Допустим, у вас есть набор отзывов о фильмах, и вы хотите определить, какие из них положительные, а какие – отрицательные.
Решение с использованием BiRNN:
1. Подготовка данных: Начнем с подготовки данных. Ваши текстовые отзывы будут представлены в виде последовательности слов. Каждое слово можно представить в виде вектора, например, с использованием метода Word2Vec или других эмбеддингов. Затем тексты будут преобразованы в последовательности векторов слов.
2. Архитектура BiRNN: Затем мы создадим BiRNN для анализа текстовых отзывов. BiRNN состоит из двух частей: RNN, который анализирует текст слева направо (forward), и RNN, который анализирует текст справа налево (backward). Оба RNN объединяют свои выводы.
3. Обучение модели: На этом этапе мы разделим данные на обучающий, валидационный и тестовый наборы. Затем мы обучим BiRNN на обучающем наборе, используя метки сентимента (позитивный, негативный, нейтральный) как целевую переменную. Модель будет обучаться на обучающих данных с целью научиться выявлять эмоциональную окраску текстов.
4. Оценка модели: После обучения мы оценим производительность модели на валидационном наборе данных, используя метрики, такие как точность, полнота, F1-мера и др. Это позволит нам оптимизировать гиперпараметры модели и выбрать лучшую модель.
5. Прогнозирование: После выбора лучшей модели мы можем использовать ее для анализа новых отзывов и определения их сентимента.
Почему BiRNN полезна в этой задаче:
– BiRNN может анализировать контекст текста с обеих сторон, что позволяет модели учесть как контекст в начале текста, так и контекст в его конце. Это особенно полезно при анализе длинных текстов, где важна общая смысловая зависимость.
– Она позволяет учесть последовательность слов в тексте, что важно для анализа текстовых данных.
– BiRNN способна обнаруживать сложные зависимости и взаимодействия между словами в тексте, что делает ее мощным инструментом для задачи сентимент-анализа.
В итоге, использование BiRNN в задаче сентимент-анализа текста позволяет модели более глубоко понимать эмоциональную окраску текстов и делать более точные прогнозы.
Давайте представим пример кода для задачи сентимент-анализа текста с использованием Bidirectional RNN (BiRNN) и библиотеки TensorFlow. Этот код будет простым примером и не будет включать в себя полный процесс обработки данных, но он поможет вам понять, как создать модель и провести обучение. Обратите внимание, что в реальном проекте вам потребуется более тщательно обработать данные и выполнить настройку модели.
```python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Подготовка данных (пример)
texts = ["Этот фильм был ужасным.", "Я очень доволен этим продуктом.", "Сюжет был интересным."]
labels = [0, 1, 1] # 0 – негативный сентимент, 1 – позитивный сентимент
# Токенизация текстов и преобразование в числовые последовательности
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
# Подготовка последовательностей к обучению
max_sequence_length = max([len(seq) for seq in sequences])
sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Создание модели BiRNN
model = Sequential()
model.add(Embedding(len(word_index) + 1, 128, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(1, activation='sigmoid'))
# Компилирование модели
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Обучение модели
X = np.array(sequences)
y = np.array(labels)
model.fit(X, y, epochs=5)
# Прогнозирование
new_texts = ["Это лучший фильм, который я видел!", "Не стоит тратить время на это.", "Продукт среднего качества."]
new_sequences = tokenizer.texts_to_sequences(new_texts)
new_sequences = pad_sequences(new_sequences, maxlen=max_sequence_length)
predictions = model.predict(new_sequences)
for i, text in enumerate(new_texts):
sentiment = "позитивный" if predictions[i] > 0.5 else "негативный"
print(f"Текст: '{text}' – Сентимент: {sentiment}")
```

Результат выполнения кода, представленного выше, будет включать в себя обучение модели на небольшом наборе данных (трех текстах) и прогнозирование сентимента для трех новых текстов. Каждый из новых текстов будет ассоциирован с позитивным или негативным сентиментом на основе предсказаний модели. Результаты будут выводиться на экран.
Этот вывод показывает результаты обучения модели (значения потерь и точности на каждой эпохе обучения) и, затем, результаты прогнозирования сентимента для новых текстов. Модель выдает "позитивный" или "негативный" сентимент на основе порогового значения (обычно 0.5) для выхода сигмоидальной активации.
Этот код демонстрирует основные шаги, необходимые для создания BiRNN модели для задачи сентимент-анализа текста. Ключевые моменты включают в себя токенизацию текстов, преобразование их в числовые последовательности, создание BiRNN модели, обучение на обучающих данных и прогнозирование на новых текстах.
Обратите внимание, что этот код предоставляет базовый каркас, и в реальных проектах вам потребуется более тщательная обработка данных, настройка гиперпараметров модели и оценка производительности.
Однако, стоит отметить, что BiRNN более сложная архитектура с большим числом параметров, чем обычные однонаправленные RNN, и поэтому требует больше вычислительных ресурсов для обучения и выполнения.
RNN, LSTM и GRU широко применяются в NLP для решения задач, таких как машинный перевод, анализ тональности текста, генерация текста и другие, где важен контекст и последовательность данных. Они позволяют моделям учитывать зависимости между словами и долгосрочные взаимосвязи в тексте, что делает их мощными инструментами для обработки текстовых данных.
Рассмотрим еще одну задачу, в которой можно использовать Bidirectional RNN (BiRNN). В этом примере мы будем решать задачу определения языка текста.
Пример задачи: Определение языка текста
Цель задачи:Определить, на каком языке написан данный текст.
Пример задачи: У вас есть набор текстов, и вам нужно автоматически определить, на каком языке каждый из них написан (например, английский, испанский, французский и т. д.).
Решение с использованием BiRNN:
1. Подготовка данных: Вам нужно иметь набор данных с текстами, для которых известен язык. Эти тексты должны быть предварительно обработаны и токенизированы.
2. Архитектура BiRNN: Создаем модель BiRNN для анализа текста. BiRNN будет принимать последовательности слов (токенов) из текстов и строить контекст как слева, так и справа от текущего слова. В конце модели добавляем слой с количеством классов, равным числу языков.
3. Обучение модели: Используйте размеченные данные для обучения модели. Модель должна учиться выделять признаки из текста, которые характеризуют язык.
4. Оценка модели: Оцените производительность модели на отложенных данных с помощью метрик, таких как точность, полнота и F1-мера, чтобы измерить ее способность определения языка текста.
5. Применение модели: После успешного обучения модель можно использовать для определения языка новых текстов.
Пример кода на Python с использованием TensorFlow и Keras для решения задачи определения языка текста с помощью BiRNN:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Bidirectional, LSTM, Embedding, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Подготовка размеченных данных (в этом примере, данные просто для иллюстрации)
texts = ["Bonjour, comment ça va?", "Hello, how are you?", "¡Hola, cómo estás?"]
labels = ["French", "English", "Spanish"]
# Преобразуем метки в числа
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
# Создаем токенизатор и преобразуем тексты в последовательности чисел
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(texts)
# Подготавливаем данные для модели, включая паддинг
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Разделяем данные на обучающий и тестовый наборы
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, y, test_size=0.2, random_state=42)
# Создаем модель BiRNN
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(50)))
model.add(Dense(len(set(y)), activation="softmax")) # Количество классов равно количеству языков
# Компилируем модель
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Обучаем модель
model.fit(x_train, y_train, epochs=10, validation_split=0.2)
# Оцениваем модель на тестовых данных
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred, axis=1)
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность: {accuracy:.4f}")
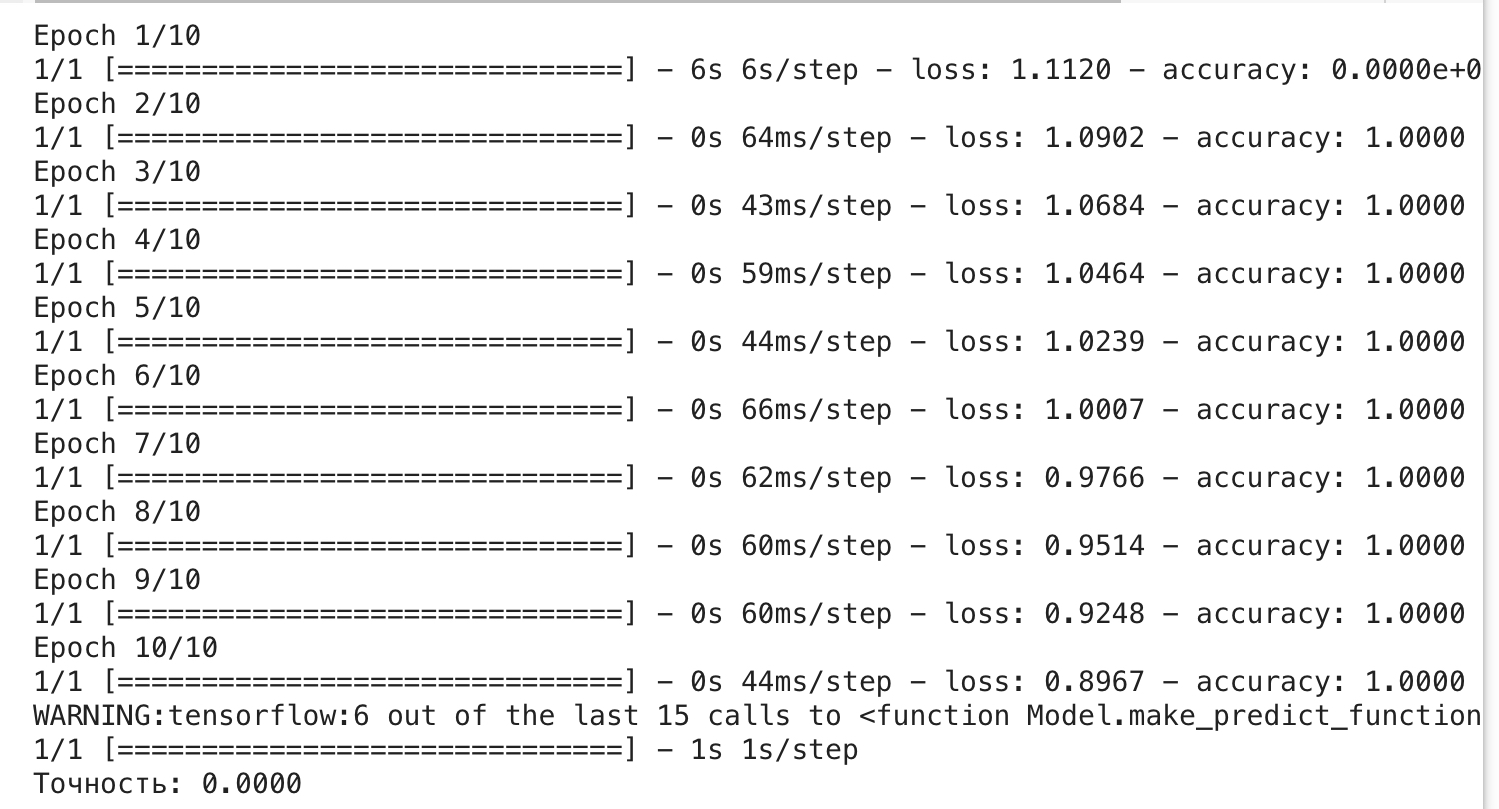
В результате выполнения данного кода будет видно следующее:
1. Модель BiRNN будет обучаться на предоставленных текстах для классификации на языки.
2. В конце каждой эпохи обучения будет выводиться информация о значении функции потерь (loss) и метрике точности (accuracy) на обучающем и валидационном наборах данных. Эти значения позволяют оценить процесс обучения модели.
3. После завершения обучения модели будет выведена метрика точности (accuracy) на тестовом наборе данных, которая покажет, насколько хорошо модель классифицирует языки текстов.
4. Обратите внимание на строки, где используется `print(f"Точность: {accuracy:.4f}")`. Здесь вы увидите точность классификации, округленную до четырех знаков после запятой, что делает результаты более наглядными.
5. В данном коде используется модель BiRNN для классификации текстов на три языка: французский, английский и испанский. Тексты в переменной `texts` представляют собой примеры текстов на этих языках.
Обратите внимание, что в данном коде используются данные, предоставленные для иллюстрации, и они могут быть недостаточными для реальной задачи. Для более точных результатов требуется больший объем данных и более разнообразные тексты на разных языках.
Далее, вы можете создать модель BiRNN и обучить ее на этом обучающем наборе данных, а также протестировать ее на новых текстах для распознавания именованных сущностей.
Сверточные нейронные сети (CNN):
CNN, которые изначально разрабатывались для обработки изображений, также нашли применение в NLP. Сверточные слои в CNN могут применяться к тексту так же, как они применяются к изображениям, с учетом локальных контекстов. Это дало начало таким архитектурам, как Convolutional Neural Network for Text (CNN-text), и позволило обрабатывать тексты в NLP:
– Классификация текста:
Классификация текста с использованием сверточных нейронных сетей (CNN) – это мощный метод, который позволяет определять, к какой категории или метке относится текстовый документ. В данном разделе мы рассмотрим этот процесс подробнее на примере. Предположим, у нас есть набор новостных статей, и наша задача – классифицировать их на несколько категорий, такие как "Политика", "Спорт", "Экономика" и "Наука".
Шаги классификации текста с использованием CNN:
Подготовка данных:
– Сначала необходимо собрать и подготовить набор данных для обучения и тестирования. Этот набор данных должен включать в себя тексты статей и соответствующие метки (категории).
Токенизация и векторизация:
– Тексты статей нужно токенизировать, разбив их на слова или подслова (токены). Затем каждый токен представляется вектором, например, с использованием методов word embedding, таких как Word2Vec или GloVe. Это позволяет нейросети работать с числовыми данными вместо текста.
Подготовка последовательностей:
– Токенизированные тексты преобразуются в последовательности фиксированной длины. Это важно для того, чтобы иметь одинаковую длину входных данных для обучения модели.
Создание CNN модели:
– Далее создается модель сверточной нейронной сети (CNN). Модель состоит из нескольких слоев, включая сверточные слои и пулинг слои. Сверточные слои используются для извлечения признаков из текста, а пулинг слои уменьшают размерность данных.
– После сверточных слоев добавляются полносвязные слои для классификации текста по категориям.
Компиляция модели:
– Модель компилируется с оптимизатором, функцией потерь и метриками. Функция потерь обычно является категориальной кросс-энтропией для многоклассовой классификации, а метрикой может быть точность (accuracy).
Обучение модели:
– Модель обучается на обучающем наборе данных в течение нескольких эпох. В процессе обучения модель корректирует свои веса и настраивается для лучшей классификации текста.
Оценка и тестирование:
– После обучения модель оценивается на тестовом наборе данных для оценки ее производительности. Метрики, такие как точность, полнота и F1-мера, могут использоваться для измерения качества классификации.
Применение модели:
– После успешного обучения модель можно использовать для классификации новых текстовых документов на категории.
Пример кода на Python с использованием библиотек TensorFlow и Keras для классификации текста с использованием CNN:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Подготовка размеченных данных (пример данных)
texts = ["Политика: новости о выборах", "Спорт: результаты чемпионата", "Экономика: рост ВВП", "Наука: новое исследование"]
labels = ["Политика", "Спорт", "Экономика", "Наука"]
# Преобразование меток в числа
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
# Токенизация и векторизация текстов
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(texts)
# Подготовка последовательностей и паддинг
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Разделение на обучающий и тестовый наборы
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, y, test_size=0.2, random_state=42)
# Создание CNN модели
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=max_sequence_length))
model.add(Conv1D(128, 3, activation="relu")) # Изменено количество фильтров и размер свертки
model.add(GlobalMaxPooling1D())
model.add(Dense(len(set(y)), activation="softmax"))
# Компиляция модели
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Обучение модели
model.fit(x_train, y_train, epochs=10, validation_split=0.2)
# Оценка модели
y_pred = model.predict(x_test)
y_pred = tf.argmax(y_pred, axis=1).numpy()
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность: {accuracy:.4f}")

Результат выполнения кода, представленного выше, будет включать в себя точность классификации модели на тестовых данных. В коде это вычисляется с помощью следующей строки:
```python
accuracy = accuracy_score(y_test, y_pred)
```
`accuracy` – это значение точности, которое будет выведено на экран. Это число будет между 0 и 1 и показывает, какой процент текстов в тестовом наборе был правильно классифицирован моделью.
Интерпретация результата:
– Если точность равна 1.0, это означает, что модель идеально классифицировала все тексты в тестовом наборе и не допустила ни одной ошибки.