


Роль читателя. Исследования по семиотике текста
a) узнаваемый стиль или текстовой идиолект, причем этот идиолект нередко может принадлежать не личности, а жанру, социальной группе или исторической эпохе (см.: Теория, 3.7.6);
b) просто актантная роль (/ я / = «субъект [подлежащее] данного предложения»);
c) иллокутивный* сигнал (/ Я клянусь, что… /) или перлокутивный* оператор (/ внезапно случилось нечто ужасное… /).
Обычно такой вызов «духа» отправителя соотносится с вызовом и «духа» адресата (Kristeva, 1970). Рассмотрим следующий отрывок из «Философских исследований» Витгенштейна (фрагмент 66):
(2) «Рассмотрим, например, процессы, которые мы называем «играми». Я имею в виду настольные игры, игры в карты, игры с мячом… Посмотри, есть ли [на самом деле] нечто общее для них всех. Ведь, глядя на них, ты не увидишь чего-то общего, присущего им всем, но [лишь] подобия, отношения сродства, и притом в большом количестве».
Все личные местоимения в этом отрывке (выраженные или невыраженные) не указывают на человека по имени Людвиг Витгенштейн или на какого-либо конкретного (эмпирического) читателя: они представляют собой лишь текстовые стратегии. Присутствие говорящего субъекта (в первом лице) здесь лишь дополняет активизацию такого М-Читателя, чей интеллектуальный облик определен теми интерпретационными операциями, которые ему предназначено произвести (усмотреть сходства, подумать об определенных играх и т. д.). Подобным же образом «автор» здесь – не что иное, как текстовая стратегия, устанавливающая семантические корреляции и активизирующая М-Читателя: «Я имею в виду…» означает лишь, что в пределах этого текста слово «игра» обретает определенный смысл, включающий в себя и настольные игры, и игры в карты, и т. д.
В данном тексте Витгенштейн – не что иное, как некий философский стиль, а его М-Читатель – не что иное, как интеллектуальная способность воспринимать этот стиль и соучаствовать в его актуализации.
В дальнейшем я буду употреблять термин «автор» лишь в метафорическом смысле, т. е. подразумевая под этим термином некий тип «текстовой стратегии». То же относится и к термину «М-Читатель».
Иными словами, М-Читатель – это тот комплекс благоприятных условий[18] (определяемых в каждом конкретном случае самим текстом), которые должны быть выполнены, чтобы данный текст полностью актуализовал свое потенциальное содержание.
0.3. Уровни текста
0.3.1. Тексты повествовательные и неповествовательные
Выше было сказано, что всякий текст есть некое синтактико-семантико-прагматическое устройство, чья предвидимая интерпретация есть часть самого процесса его создания. Но такое определение все же слишком абстрактно. Чтобы сделать его более конкретным, следовало бы представить «идеальный» текст как некую систему «узлов» или «сплетений» и установить, в каких из них ожидается и стимулируется сотрудничество-сотворчество М-Читателя.
Вероятно, подобное аналитическое представление – «вне пределов нынешних возможностей семиотики текста как теоретической дисциплины. До сих пор попытки в этом направлении предпринимались лишь применительно к отдельным текстам (и хотя в таких случаях аналитические категории создавались ad hoc, они нацеливались и на более общее применение). Примеры наиболее успешных попыток такого рода, на мой взгляд, – это анализ новеллы Бальзака «Сарразин», проведенный Р. Бартом (Barthes, 1970)[19], и анализ рассказа Мопассана «Два друга», выполненный А. Греймасом (Greimas, 1976). Более детальные и более формализованные анализы более коротких отрывков текста (как, например, разбор «Маленького принца» Сент-Экзюпери у Я. Петефи – Petőfi, 1975) явным образом задумывались скорее как опыты применения соответствующей теории, а не как попытки исчерпывающей интерпретации выбранного текста.
Современные теории, разрабатывая модели «идеального» текста, обычно представляют его состоящим из различных структурных уровней, которые так или иначе понимаются как идеальные стадии процесса его порождения и / или интерпретации. Так буду действовать и я.
Чтобы представить «идеальный» текст, обладающий наибольшим числом уровней, я буду рассматривать в основном модель вымышленных повествовательных (нарративных) текстов (a model for fictional narrative texts)[20]. Такое решение обусловлено тем, что бóльшая часть очерков, собранных в этой книге, посвящена именно текстам вымышленно-повествовательным. Но тексты подобного рода ставят перед исследователем большинство из тех проблем, которые возникают при изучении других типов текстов: в вымышленно-повествовательных текстах мы можем найти примеры текстов диалогических, описательных, дискурсивных и т. д., т. е. любые типы речевых актов.
Т. А. ван Дейк (van Dijk, 1974b) различает повествования естественные (natural) и искусственные (artificial). Оба представляют собой описания действий, но первые повествуют о событиях, которые представляются как действительно произошедшие (их субъекты – люди или человекоподобные существа, живущие в «реальном» мире; события развиваются от некоего начального состояния до состояния конечного), а вторые имеют дело с персонажами и действиями, относящимися к миру «воображаемому» или «возможному». Очевидно, что в искусственном повествовании не выполняется ряд прагматических условий, обязательных для повествования естественного (например, в художественной литературе [fiction] от автора, строго говоря, не ожидается, что он будет говорить правду), но даже это различие для меня сейчас несущественно: так называемые искусственные повествования всего лишь заключают в себе более широкий диапазон экстенсиональных* проблем (см. обсуждение проблемы возможных миров в главе 8 данной книги).
Поэтому моя модель будет моделировать повествовательные (нарративные) тексты вообще (будь то искусственные или естественные). Я предполагаю, что идеальная модель текстовых явлений, задуманная на более высоком уровне сложности, будет пригодной и для текстов более простых.
Несомненно, художественно-повествовательный текст гораздо сложнее, чем условные контрфактические высказывания[21] разговорного характера, хотя в обоих случаях речь идет о возможном положении дел или о возможном ходе событий. Одно дело – рассказать какой-нибудь девушке, что с ней могло бы случиться, если бы она наивно приняла ухаживания какого-нибудь распутника. И совсем другое дело – поведать кому-либо (вне зависимости от пола) то, что уже необратимо произошло в Лондоне, в XVIII в., с девушкой по имени Кларисса, когда она наивно приняла ухаживания распутника по имени Ловелас.
Во втором случае мы наблюдаем некоторые специфические черты, характерные именно для искусственных повествований:
а) посредством специальной вводной формулы (явной или подразумеваемой) читателю дается понять, что он не должен спрашивать, истинны или не истинны излагаемые факты (иногда читателю внушается, что он должен воспринимать эти «факты» как правдоподобные; это условие отсутствует в повествованиях откровенно нереальных, например в волшебных сказках);
b) читателя знакомят с некими личностями, представляемыми ему с помощью ряда описаний, «привешенных» (по выражению Дж. Сёрла) к их именам собственным и придающих им определенные свойства;
c) последовательность событий более или менее локализована в пространстве и во времени;
d) эта последовательность событий считается «конечной», т. е. у нее есть начало и конец;
e) чтобы рассказать о том, что произошло с Клариссой, текст начинает с некой исходной ситуации, в которой находилась Кларисса, а затем следует за героиней в перипетиях ее жизни, предоставляя читателю возможность задаваться вопросами о том, что произойдет с Клариссой на следующем этапе повествования;
f) весь ход событий в целом, описанный в повествовании, можно резюмировать некоторым числом макровысказываний (macropropositions), образующих остов, каркас данного повествования (мы будем называть этот остов фабулой), выделив таким образом уже иной уровень текста, производный от его линейной манифестации[22], но не тождественный ей.
С другой стороны, контрфактические высказывания отличаются от отрывка искусственного повествования только тем, что в первом случае адресат приглашается к более активному сотрудничеству в деле актуализации предложенного ему текста – он должен сам придумать историю, которую ему подсказывает текст. Ниже мы рассмотрим также несколько неповествовательных текстов, которые как будто не должны соответствовать предлагаемой модели. В таких случаях можно, конечно, попытаться видоизменить модель. Но можно несколько видоизменить и сам текст: как мы увидим, неповествовательный текст обычно можно преобразовать в повествовательный, просто развернув некоторые заложенные в нем потенции.
Конечно, повествовательные тексты – особенно тексты художественные (fictional) – более сложны, чем многие иные типы текстов, и поэтому более трудны для семиотического анализа. Но тем самым они делают такой анализ более интересным и вознаграждающим. Именно поэтому, наверное, мы больше узнаём об устройстве текстов от тех исследователей, которые дерзают изучать сложные повествовательные тексты, чем от тех, кто ограничивается анализом текстов более коротких и простых. Может быть, во втором случае достигается большая степень формализации, но зато опыты первого рода дают нам более высокую степень понимания.
0.3.2. Уровни текста: теоретическая абстракция
Понятие уровни текста весьма проблематично. В линейной манифестации текста (т. е. в той, которая, собственно, и предстает читателю) нет никаких уровней. Согласно Чезаре Сегре (Segre, 1974, 5), «уровень» и «порождение» [текста] – это две метафоры: автор не «говорит», он «уже сказал». При восприятии текста мы имеем дело с планом выражения* – и вовсе не очевидно (во всяком случае, никем не доказано), что то, как мы воспринимаем текст, преобразуя план выражения в план содержания*, отражает (в обратном порядке) тот процесс, в ходе которого некое задуманное содержание преобразовалось в данное выражение. Поэтому понятие уровни текста – понятие чисто теоретическое; оно принадлежит метаязыку семиотики.
На рис. 0.3 постулируется определенная иерархическая схема операций, осуществляемых при интерпретировании текста. Эта моя схема многим обязана модели Яноша Петефи (которая называется TeSWeST: Text-Struktur-Welt-Struktur-Theorie)[23], хотя я и попытался ввести в свою картину элементы еще и других теоретических построений (в частности, актантные структуры А. Греймаса и некоторые идеи Г. А. ван Дейка). В модели Петефи меня особенно привлекает стремление сочетать интенсиональный* и экстенсиональный подходы.
Однако модель Петефи жестко определяет направление порождающего процесса, в то время как моя модель (рис. 0.3) демонстративно отказывается изображать какие-либо направления и какую-либо иерархию этапов (фаз) в процессе читательского сотворчества.
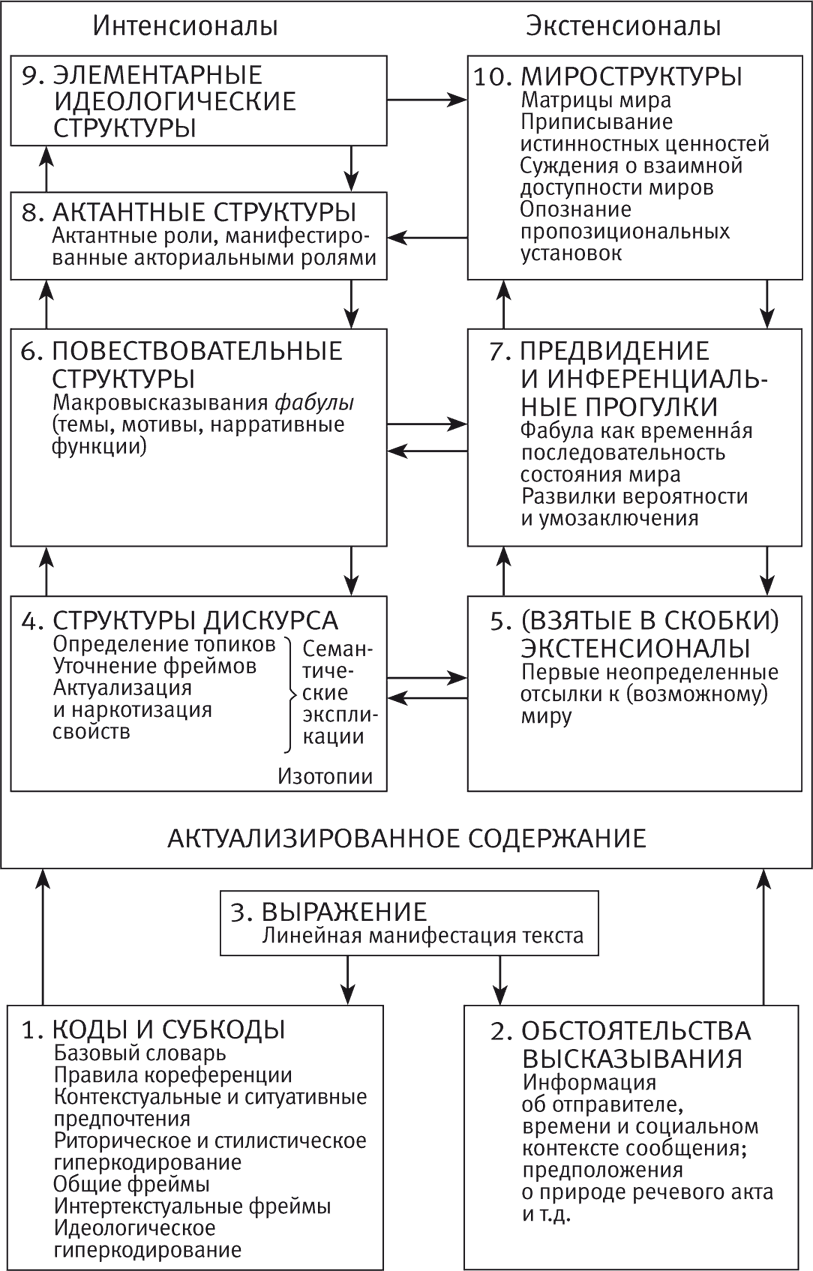
Рис. 0.3
Все уровни и подуровни на моей диаграмме (все они, по сути дела, – лишь метатекстовые «ящички») взаимосвязаны таким образом, что движение от одного к другому возможно в обоих направлениях. Творческое сотрудничество читателя-интерпретатора на более низких уровнях может быть успешным лишь потому, что еще прежде у него возникают гипотезы относительно более высоких уровней – и наоборот. Но то же справедливо и для процесса порождения текста: нередко автор принимает решение, затрагивающее глубинную семантическую структуру всего текста (of his story), только и именно в тот момент, когда он делает некий выбор на уровне лексики, предпочитая, по чисто стилистическим причинам, одно выражение другому. Подобным же образом стрелки на моей диаграмме не изображают какой-либо временной или логический процесс, пусть даже идеализированный; они всего лишь указывают на взаимозависимость между «ящичками».
Таким образом, рис. 0.3 изображает (металингвистически) некие абстрактно представимые уровни, на которых может осуществляться сотворческая активность читателя. Поэтому во избежание недоразумений впредь я буду говорить не об «уровнях» текста (поскольку эта метафора неизбежно подсказывает идею иерархии конкретных операций), а только о «ящичках», имея в виду конкретные элементы теоретически постулированной мною визуализации.
На рис. 0.3, пожалуй, лишь в одном-единственном отношении изображен реальный ход интерпретации текста: движение неизбежно должно начинаться в «ящичке» № 3 («линейная манифестация текста») – и нельзя «прыгнуть» из этого «ящичка» дальше, не пройдя хотя бы через «ящичек» № 1, обозначающий систему кодов и субкодов, необходимых для преобразования плана выражения в план содержания.
0.4. Линейная манифестация текста и обстоятельства высказывания (utterance[24])
0.4.1
Линейной манифестацией текста [ «ящичек» № 3] я называю его лексемную поверхность. Читатель применяет к воспринимаемым выражениям заданный код или, вернее, систему кодов и субкодов [ «ящичек» № 1], чтобы преобразовать эти выражения в первые уровни содержания [ «ящички» № 4, 5 и т. д.].
Текст (3) – это отрывок из стихотворения Кристиана Моргенштерна[25] «Большой Лалула» («Der grosse Lalula»):
(3) Kroklowafgi? Semememi!
Seikronto prafriplo.
Bifzi, bafzi; hulalomi…
quasti besti bo…
Этот текст имеет линейную манифестацию, т. е. план выражения, с которым, однако, не может быть соотнесен никакой план содержания, поскольку автор не имеет в виду никакого существующего кода (я не говорю для простоты о возможных звуковых коннотациях*, а также об ореоле «литературности» у этого предадаистского эксперимента).
Текст (4) – отрывок из стихотворения Тристана Тзара[26] «Toto-Vaca»:
(4) ka tangi te kivi
kivi
ka rangi te mobo
moho…
Этот текст имеет линейную манифестацию, которой я не могу приписать никакого содержания. Однако это смогут, вероятно, сделать некоторые читатели, поскольку данный текст изначально вроде бы представлял собой стихотворение на языке маори.
На этом уровне рассмотрения возможна фонетическая интерпретация, особенно важная для таких текстов, как тексты (3) и (4), но игнорируемая при последующем анализе, поскольку при рассмотрении повествовательных текстов меня, естественно, больше интересуют «ящички» более высоких уровней. См., однако, Теорию (3.7.4), где обсуждается «дальнейшая сегментация плана выражения», имеющая место в эстетических текстах. См. также в Теории разделы о ratio difficilis и изобретении (3.4.9, 3.6.7, 3.6.8), где речь идет о тех случаях, когда манипуляции с планом выражения существенно затрагивают самое природу используемых кодов. В очерке о языке Эдема (глава 3 в данной книге) я также отчасти затрагиваю эти проблемы.
0.4.2
Схема на рис 0.3 напрямую увязывает линейную манифестацию текста и акт высказывания (the act of utterance) (на рис. 0.2 он включен в число «обстоятельств, которые определяют исходные пресуппозиции»).
Эта связь между предложением (sentence) и его произнесением (utterance) (между énoncé и énonciation) позволяет адресату любого текста сразу же распознать, хочет ли отправитель осуществить пропозициональный акт* или же речевой акт какого-то иного рода. Если текст прост по своей структуре и имеет явной целью указание, повеление, вопрос и т. д., то адресат, вероятно, будет переключаться с «ящичка» № 2 на «ящичек» № 10, определяя одновременно и чтó отправитель имеет в виду, и (в плане конкретного содержания) лжет ли он или говорит правду, спрашивает ли он о чем-то, приказывает ли что-то выполнимое или невыполнимое и т. д. В зависимости от сложности текста и от изощренности адресата в дальнейшем могут быть задействованы и другие «ящички» – скрытые идеологические структуры можно заподозрить даже в таком тексте, как / Поди сюда, ублюдок / (варианты на выбор: / …паршивый интеллигент / / …паршивый еврей /, / …паршивый негр /, / …поповская рожа /, / …старый хрыч /, / …мой юный друг / и т. д.).
При чтении же вымышленно-повествовательного (fictional) текста отсылка к акту высказывания (the reference to the act of utterance) обретает другие функции. Такая отсылка может иметь две формы. В более простом случае возникает своего рода метатекстовое высказывание (proposition) примерно такого смысла: «есть / был некий человек, который высказывает / высказал (utters / uttered) текст, который я сейчас читаю, и который просит [меня] совершить акт приостановки недоверия[27], поскольку он говорит / говорил о некотором возможном ходе событий». (Заметим, что такое же метатекстовое высказывание применимо и к научному тексту, за исключением приостановки недоверия – в этом случае, напротив, читатель приглашается особенно верить рассказчику.)
Более сложные операции могут применяться тогда, когда читатель пытается реконструировать (например, к качестве филолога) исходные обстоятельства, при которых был высказан данный текст (исторический период, этническую или культурную принадлежность рассказчика и т. д.). В подобном случае, как только эти внешние обстоятельства установлены, они «закладываются» в «ящичек» № 1, где преобразуются в соответствующие элементы энциклопедического знания (encyclopedic knowledge) (т. е. в контекстуальные и прочие предпочтения[28], фреймы*[29] и другие виды гиперкодирования* [overcoding][30]).
0.5. Экстенсионалы, взятые в скобки [ «ящичек» № 5]
Когда читатель текста распознает существование неких индивидов[31] (одушевленных или неодушевленных), обладающих определенными свойствами (среди которых и совершение неких действий), то он, по-видимому, делает некие референциальные предположения (indexical presuppositions), иными словами, он соотносит вышеупомянутых индивидов с неким возможным миром* (a possible world)[32]. Чтобы использовать информацию, содержащуюся в его «базовом словаре» [ «ящичек» № 1], читатель – до поры до времени – предполагает также, что этот возможный мир тождествен миру его, читателя, собственного опыта (отраженного в «базовом словаре»).
Если же по ходу чтения и декодирования текста читатель обнаруживает какие-либо расхождения между миром собственного опыта и миром, изображенным в тексте (например, если камень, предмет неодушевленный, вдруг начинает говорить), то он или сразу «прыгает» в «ящичек» № 10, или временно берет эти экстенсионалы «в скобки», т. е. «приостанавливает свое недоверие» в ожидании дополнительной семантической информации, которая может быть получена в «ящичке» № 4 («Структуры дискурса»).
0.6. Структуры дискурса
[ «ящичек» № 4]
0.6.1. Коды, гиперкодирование, фреймы
[ «ящичек» № 1]
В «ящичке» № 4 читатель сопоставляет линейную манифестацию текста с системой кодов и субкодов, содержащейся в том языке, на котором текст написан («ящичек» № 1). Эту сложную систему кодов и субкодов я называю энциклопедической компетенцией (competenza enciclopedica); в Теории (2.12) она представлена как Модель Q[33].
Так начинается трансформация плана выражения в план содержания. В порыве лексикологического оптимизма можно было бы сказать, что в этой операции нет ничего сложного, потому что содержание всякого словесного выражения предустановлено словарем и читателю надо лишь декодировать план выражения лексема за лексемой, вынимая из словаря и складывая один с другим («амальгамируя») соответствующие смыслы. Но все знают, что на самом деле все не так просто (см.: Теория, 2.15): для любой общей теории «амальгамирования» семем* камнем преткновения оказываются «контекстуальные смыслы (значения)».
Впрочем, я – в отличие от многих теоретиков текста – не верю, что между словарным значением слова и значением (кон)текстуальным лежит непроходимая пропасть. Правда, до сих пор методом анализа в терминах семантических компонентов (semantic compositional analysis) не удалось объяснить сложные процессы текстовой амальгамации. Но я не думаю, что подобный метод должен быть полностью отвергнут и заменен подходом, при котором некий автономный набор текстовых правил определяет окончательную интерпретацию лексических значений. Я полагаю, напротив, что если текст может быть порожден и интерпретирован, то это происходит по тем же семантическим причинам, по каким сами лексические значения могут быть поняты, а предложения – порождены и интерпретированы. Проблема лишь в том, чтобы включить в число семантических компонентов также и то, что я называю контекстуальными и ситуативными предпочтениями (Теория, 2.11), а также учесть правила гиперкодирования (Теория, 2.14) и такой фактор, как текстовые операторы (см. ниже раздел 0.6.2). Очерк о семантике Чарльза Пирса (глава 7 данной книги) должен способствовать восприятию подобной точки зрения.
В разделе 0.6.2 мы увидим, что даже такая текстовая категория, как фрейм, основана на модели семемного представления в терминах грамматики [семантических] падежей*. Мы также увидим (в разделе 0.7.4), что есть большое структурное подобие между данным типом семемного представления и более абстрактными структурами. Поэтому мы можем предположить, что семема сама по себе – это зачаточный текст, а текст – развернутая семема[34].
Итак, было бы нереалистично рассматривать «ящички» на рис. 0.3 как «реальные» шаги в процессе интерпретации текста: скорее это виртуальные узлы интерпретационного процесса, который на самом деле гораздо более непрерывен (континуален) и «расписание» которого довольно непредсказуемо.
Сказав все это, мы можем теперь перейти к рассмотрению различных кодов и субкодов в «ящичке» № 1.
0.6.1.1. Базовый словарь [ «ящичек» № 1]. На этом подуровне читатель прибегает к лексикону (запасу слов), имеющему формат базового словаря*, и сразу же определяет основные семантические свойства выражений, составляющих текст, чтобы произвести их предварительное «амальгамирование». Если в тексте говорится, что / Жила-была однажды принцесса по имени Белоснежка. Она была очень красивая /, то читатель по ходу первоначального семантического анализа слова «принцесса» определяет, что Белоснежка – это, несомненно, «женщина». Семема «принцесса» потенциально гораздо более сложна (например, «женщина» значит «человеческое существо женского пола», а таковое существо обладает многими свойствами: определенными телесными органами и т. д.). Но на данной стадии читатель еще не знает, какие из этих потенциальных свойств будут актуализованы. Прояснить эту неопределенность могут только дальнейшее «амальгамирование» и текстовые операторы. Пока же, на том подуровне, о котором идет речь, читатель актуализует грамматические и семантические свойства лексем (в случае с Белоснежкой – единственное число, женский род, существительное, одушевленное, человек и т. д.) и может начать установление кореференций*.
0.6.1.2. Правила кореференций [ «ящичек» № 1]. На основе первоначального семантического анализа и распознавания синтаксических свойств читатель устанавливает значения анафорических* и дейктических* выражений (различных шифтеров*). Так, он понимает, что / Она / в процитированном тексте должно быть соотнесено с принцессой. Мы увидим в разделе 0.6.2, что бóльшую часть подобных кореференций нельзя установить без помощи текстовых операторов. Так или иначе, читатель устанавливает здесь пробные ко-текстовые (co-textual) отношения[35]. На этом уровне читатель производит все трансформации поверхностных структур в глубинные в пределах одного предложения. Если возникают неоднозначности, читатель ожидает указаний («ключей») от последующего текста (см. раздел 0.6.3).
0.6.1.3. Контекстуальные и ситуативные предпочтения [ «ящичек» № 1]. Ко-текстуальные отношения – это все те связи в пределах линейной манифестации текста, которые выражены входящими в нее лексемами. Контекстуальные же предпочтения устанавливаются до появления текста тем семантическим механизмом, который мы называем энциклопедией* (см.: Теория, 2.11), и они лишь потенциально присутствуют в каждом данном тексте. Одна из задач читателя – актуализовать эти предпочтения (выбирая одни и игнорируя другие). Иными словами, контекстуальные предпочтения – это закодированные абстрактные возможности встретить данное выражение (слово) в сочетании с другим выражением (словом), принадлежащим той же семиотической системе (в данном случае – к конкретному языку). Так, хорошее энциклопедическое описание слова «кит» должно включать в себя, по крайней мере, два контекстуальных предпочтения: в контексте, где доминирует семема «древность», кит – это рыба; в контексте, где доминирует семема «современность», кит – это млекопитающее.