
Cуперкомпьютеры: администрирование
Из доступного количества LID и вытекает ограничение на количество устройств в подсети. Именно при помощи LID получателя пакета коммутаторы определяют, на какой порт надо передавать полученный пакет: записи в таблице форвардинга коммутаторов (forwarding table) в качестве ключа используют именно LID. Для упрощения обработки подсетей, в которых имеется много возможных альтернативных маршрутов между заданными парами точек, порту или коммутатору может назначаться несколько LID. В этом случае назначается базовый LID (Base LID) и LMC (LID Mask Control, управляющая маска LID). LMC – это число от 0 до 128.
Младшие LMC бит базового LID должны быть равны нолю, и считается, что порту назначены 2LMC подряд идущих значений LID, т. е. значения от Base LID до Base LID + 2LMC – 1. Если на порт назначается только один LID, то LMC = 0. Обычно в одной подсети используются не более двух значений LMC: одно для назначения LID портам адаптеров и другое (чаще всего ноль) для назначения LID коммутаторам.
Глобальный идентификатор GID имеет длину в 128 бит. Он назначается каждому оконечному порту. Фактически, GID – это адрес IPv6, в котором младшие 64 бита – это GUID порта, которому назначен этот GID. Старшие 64 бита GID (GID Prefix, префикс GID) по умолчанию равны 0xFE80::/64 (подробности по текстовому представлению адресов и префиксов IPv6 см. в RFC2373). Область действия этого префикса – подсеть (link-local scope). Пакеты данных с GID назначения, имеющим такой префикс, не будут переданы маршрутизаторами между подсетями, т. е. GID с такими префиксами могут использоваться только для передачи данных внутри подсети. При инициализации подсети может быть назначен один (или ни одного) префикс GID, отличный от префикса по умолчанию. При этом GID с префиксом по умолчанию все равно должен работать как GID порта.
Префикс 0xFEC0::/64 – префикс с сайтовой областью действия (site-local scope). Пакеты данных, предназначенные таким адресам, могут передаваться маршрутизаторами из подсети в подсеть, но не должны покидать пределы сайта (области с единым администрированием адресного пространства). Также может быть назначен префикс с глобальной областью действия (global scope), он должен выбираться по правилам, установленным для адресов IPv6. Кроме одноадресных (unicast) GID есть и GID, предназначенные для многоадресной (multicast) передачи данных. Префикс многоадресных GID имеет старший байт 0xFF, про значение остальных бит префикса можно подробнее прочитать в RFC2373 и RFC2375.
Кроме адресации при помощи LID и GID есть еще один способ адресации, адресация при помощи направленного маршрута (Directed Route). Этим способом можно адресовать только пакеты управления подсетью (Subnet Management Packet, SMP). Он используется в основном при начальной инициализации подсети, когда портам еще не назначены LID и не установлены таблицы форвардинга коммутаторов, или после перезагрузки адаптера или коммутатора, когда доступ к ним при помощи LID ещё невозможен. В режиме адресации при помощи направленного маршрута в пакете перечисляется список портов коммутаторов, через которые должен пройти пакет данных (Initial Path). Также в пакете есть счётчик количества пересылок (hop count), который указывает число элементов в списке портов, указатель на текущий элемент в списке портов (hop pointer), указатель направления D (Direction, 0 – пакет пересылается от источника к адресату запроса, 1 – пакет содержит ответ и пересылается по направлению к источнику исходного запроса) и обратный маршрут (reverse path).
Получив пакет с полем D = 0, коммутатор при помощи указателя на текущий элемент Hop Pointer определяет порт, в который следует направить полученный пакет, записывает номер порта, через который пакет получен, в поле для сохранения обратного маршрута Reverse Path, и увеличивает поле hop pointer на единицу. Если список закончился, то получатель обрабатывает пакет, формирует ответ, меняет указатель направления на обратный (устанавливает поле D в 1) и посылает ответ. При получении пакета, в котором указатель направления установлен на обратное, коммутаторы используют обратный маршрут для определения порта для пересылки, соответственно не записывают нового обратного маршрута, и на каждом шаге уменьшают значение hop pointer на единицу.
Кроме чистого направленного маршрута возможен вариант, когда указывается LID коммутатора, до которого пакет должен быть направлен при помощи обычной адресации (по LID), и LID получателя, которому пакет должен быть направлен после того, как будет пройден путь, определяемый направленным маршрутом. Очевидно, что при этом части фабрики до и после пути, определяемого направленным маршрутом, должны быть уже инициализированы и поддерживать пересылки при помощи LID.
Управление подсетью InfiniBand
Как было сказано выше, для нормальной работы подсеть InfiniBand должна быть настроена: назначены LID портам адаптеров и коммутаторов, настроены таблицы форвардинга коммутаторов (в отличие от сетей Ethernet, в сетях InfiniBand коммутаторы не формируют свою таблицу форвардинга сами, она должна настраиваться извне).
Компонентом, который отвечает за такую настройку, а затем за поддержание подсети в рабочем состоянии, является менеджер подсети (Subnet Manager). Менеджер подсети – это программа, которая может работать на компьютере с адаптером InfiniBand или на коммутаторе (не все коммутаторы InfiniBand поддерживают запуск менеджера подсети). Для надёжности в подсети может быть запущено несколько менеджеров, в этом случае один из них является главным (master), а остальные – запасными (standby). В случае, если главный менеджер перестаёт работать, его функции берет на себя один из запасных. Также главный менеджер может явно передать роль главного одному из запасных менеджеров, например, в процессе нормальной остановки.
После запуска менеджер подсети при помощи пакетов управления подсетью, передаваемых по направленным маршрутам, выясняет структуру подсети: какие есть адаптеры, коммутаторы, маршрутизаторы, и какие между ними есть связи. Если после определения структуры подсети выяснится, что других, более приоритетных менеджеров подсети в этой подсети нет, данный менеджер становится активным и осуществляет настройку подсети, т. е. назначает всем конечным портам LID, каждому конечному порту сообщает LID порта, на котором работает сам менеджер подсети, устанавливает таблицы форвардинга коммутаторов и делает некоторые другие настройки. После этого подсеть готова к работе. В процессе работы подсети менеджер время от времени собирает информацию об изменениях её структуры (этот процесс называется Sweeping) и соответствующим образом меняет конфигурацию.
Запасные менеджеры время от времени опрашивают главного, и если тот перестаёт отвечать на запросы, один из запасных становится главным и перенастраивает подсеть, указывая ей расположение нового менеджера подсети.
IP через InfiniBand (IP over IB, IPoIB)
Работа стека протоколов TCP/IP поверх InfiniBand не является частью спецификации InfiniBand, она определена в соответствующих документах RFC. Работа InfiniBand вполне возможна и без IPoIB. Однако некоторые программы и библиотеки хотя и предназначены для работы поверх InfiniBand, требуют также работающего IP поверх InfiniBand. Чаще всего при помощи IpoIB определяют InfiniBand-идентификаторы (LID, GID) процессов, работающих на других вычислительных узлах, а после определения дальнейшие коммуникации осуществляются без участия стека TCP/IP.
Настройка IP поверх InfiniBand, в общем, не отличается от настройки IP поверх Ethernet. Есть только несколько моментов, на которые следует обратить внимание. Интерфейсы IPoIB в системе называются ib0, ib1 и т. д. (по одному интерфейсу на порт InfiniBand). Адреса лучше назначать статически, прописывая их в конфигурационных файлах серверов и вычислительных узлов. Работа протокола DHCP поверх IPoIB возможна, но для надёжности мы рекомендуем его не использовать.
Адрес канального уровня (link layer address), который в сетях Ethernet называется MAC-адрес или hardware address, для IPoIB имеет длину в 20 байт. Поэтому некоторые утилиты, в частности, широко применяемая утилита ifconfig, в которых жёстко прописана длина MAC-адреса Ethernet в 6 байт, не могут корректно работать и отображать адреса канального уровня для IPoIB. Утилита ip, рекомендуемая для замены ifconfig, такого недостатка лишена. В адресе канального уровня содержится GID порта, номер пары очередей (Queue Pair Number, QPN, аналог номера порта в TCP для InfiniBand) и флаги, указывающие, какие протоколы транспортного уровня InfiniBand могут использоваться для передачи IP.
Утилиты для просмотра информации по сетям InfiniBand
В этом разделе мы приводим примеры выдачи некоторых утилит из комплекта OFED с объяснениями выдаваемой информации. Эти данные помогут сориентироваться в том, что происходит в сети InfiniBand, и диагностировать некоторые ошибки в её работе.
Команда ibstat показывает состояние всех портов на всех адаптерах InfiniBand, установленных на узле, где она запущена
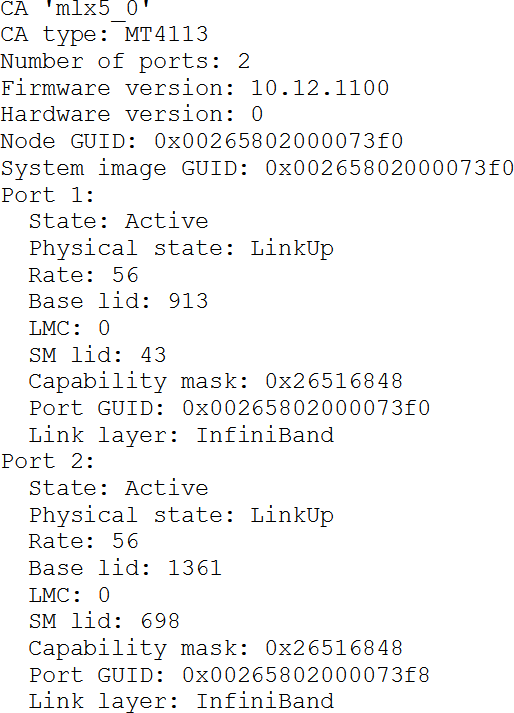
Сначала выводится информация по адаптеру: его имя (mlx5_0), тип адаптера (название модели), количество портов, версии встроенного программного (firmware) и аппаратного обеспечения, а также идентификаторы Node GUID и System Image GUID.
Для каждого порта в строке Link layer выводится тип подключения: InfiiniBand или Ethernet. Некоторые адаптеры InfiniBand позволяют подключаться как к сети InfiniBand, так и к Ethernet. Тип подключения определяется установленным трансивером. Строка Port GUID показывает GUID порта. Base lid – первый LID, присвоенный данному порту. Всего порту присвоено, как говорилось выше, 2LMC подряд идущих LID. SM lid – LID порта, на котором работает менеджер данной подсети. Rate – скорость передачи данных, на которой работает порт (56 в данном случае – это режим 4x FDR).
Physical state – состояние физического уровня передачи данных. Нормальное состояние – LinkUp. Также может быть Disabled, Polling (в это состояние порт переходит после включения), Configuration (согласование режимов работы с другой стороной связи), Recovery (восстановление после сбоя связи). Есть и другие состояния, но их появление означает серьёзный сбой в работе оборудования, и мы их здесь описывать не будем.
State – состояние канального уровня передачи данных. Active – состояние нормального функционирования, возможна передача любых типов данных. Down – передача данных невозможна (физический уровень ещё не перешёл в состояние LinkUp). Initialize – состояние, в которое канальный уровень переходит сразу после того, как физический уровень перешёл в состояние LinkUp. В этом состоянии возможны приём и передача только пакетов управления подсетью (SMP, Subnet Management Packets). В этом состоянии менеджер подсети должен настроить порт (задать LID и прочие параметры) и перевести порт в состояние Active. Есть и другие состояния, но порт не должен находиться в них долгое время, поэтому мы опустим их описания.
Capability mask – набор флагов, описывающих поддерживаемые портом режимы работы (скорости и т. п.).
Команда ibstatus также выводит информацию обо всех портах, но немного в другом формате, и выдаёт частично отличающийся набор данных:
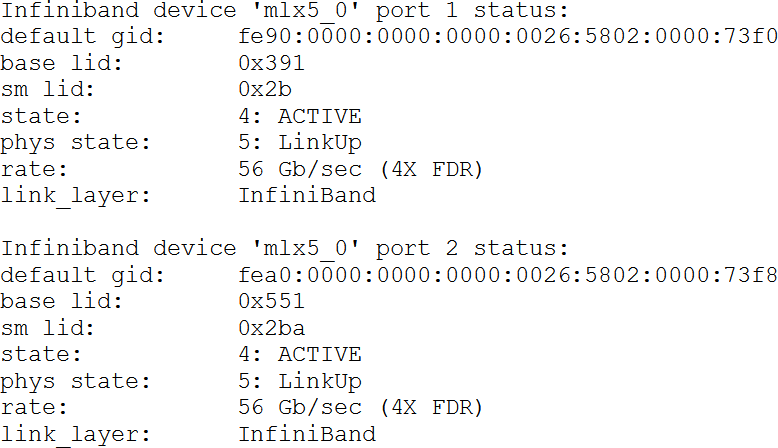
Обратите внимание, что информация о базовом LID и LID менеджера подсети дана в шестнадцатеричном виде. Более подробно дана информация о скорости, на которой работает порт. Ещё добавлена строка default gid, в которой указан GID для данного порта.
Иногда нужно узнать, какой машине назначен конкретный LID. Для этого можно применить утилиту smpquery. Вообще эта утилита предназначена для посылки пакетов управления подсетью SMP (Subnet Management Packet) и выдачи ответов в понятной человеку форме. В нашем случае нам нужен запрос описания узла (node description). Вот пример выдачи команды smpquery nodedesc 914 (запрос описания узла с LID 914):
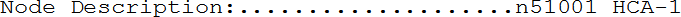
Узел ответил, что LID 914 назначен адаптеру HCA-1 вычислительного узла с именем n51001.
При помощи smpquery доступна информация о том узле, которому адресован запрос. В то же время менеджер подсети имеет информацию обо всех узлах подсети. Запросить информацию у менеджера подсети можно при помощи утилиты saquery. Информацию об узле подсети с LID 914 можно запросить командой saquery 914. Вот пример выдачи такой команды:
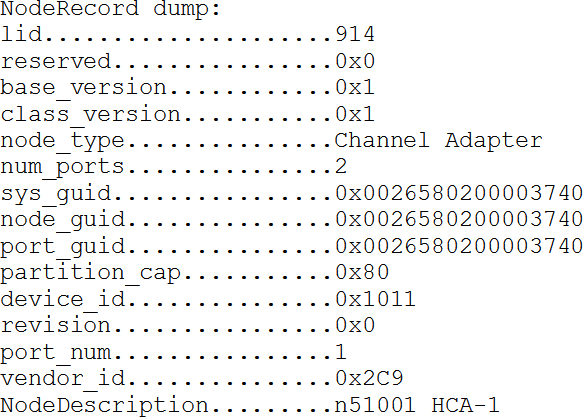
В последней строке указано описание узла, включающее имя хоста. Также приводится дополнительная информация. Ещё раз обращаем внимание, что команда smpdump позволяет запрашивать информацию об узле в сети InfiniBand у самого этого узла, а команда saquery – у менеджера подсети. Если результаты этих запросов различаются или если команда saquery выдаёт ошибку – это свидетельство того, что имеются проблемы с менеджером подсети. Ещё две полезные утилиты при диагностике сетей InfiniBand – утилиты ibnetdiscover и ibdiagnet. Утилита ibnetdiscover пытается обнаружить все компоненты подсети: конечные узлы, коммутаторы, маршрутизаторы и связи между ними, и выводит информацию обо всех найденных компонентах. Утилита ibdiagnet также пытается найти все компоненты подсети, но кроме этого она ещё и пытается обнаружить ошибки в конфигурации подсети, такие как совпадающие GUID, скорости портов и т. п.
Мы не будем приводить примеры выдачи этих утилит, так как они достаточно объёмны, а для ibdiagnet ещё и состоят из нескольких файлов. Мы упоминаем эти утилиты, чтобы иметь представление, какие средства можно использовать при диагностике проблем с сетью InfiniBand.
Утилиты, которые посылают информацию в сеть, имеют ключи для выбора адаптера и порта, с которым следует работать (напомним, что в разных подсетях один и тот же LID может относиться к разным устройствам). Ключ -C предназначен для указания адаптера (например, mlx4_0 в примерах выше), а ключ -P позволяет указать номер порта заданного адаптера (порты нумеруются, начиная с 1).
Хранение данных
В каждый узел – управляющий, вычислительный или служебный – могут быть установлены локальные жёсткие диски. Наряду с этим возможно подключение внешних дисковых подсистем, доступ к которым будет производиться со всех узлов одновременно.
Локальные жёсткие диски могут использоваться для загрузки операционной системы, как виртуальная память (область подкачки) и для хранения временных данных. Конечно, вычислительные узлы могут и не иметь локальных дисков, если загрузка операционной системы на них организована через сеть, хотя даже в этом случае локальный диск полезен для области подкачки и хранения временных данных. На управляющем узле локальные жёсткие диски обычно устанавливаются, а сетевая загрузка при этом не предусматривается.
На внешних системах хранения данных (далее – СХД) обычно располагаются программные пакеты и утилиты, запуск которых требуется на всех узлах, а также домашние каталоги пользователей, временные хранилища общего доступа (для хранения временных данных расчётов) и прочие данные, которые должны быть доступны со всех узлов. Внешние СХД обычно различаются по внутреннему устройству и по способу доступа, от чего зависит уровень надёжности хранения данных и скорость доступа к ним. Внутреннее устройство СХД мы разбирать здесь не будем, упомянем лишь различные способы доступа.
По способу доступа СХД разделяются как минимум на три типа:
• непосредственно подключённая СХД – Direct Attached Storage или DAS;
• СХД с доступом по локальной сети или сетевое хранилище данных – Network Attached Storage, или NAS;
• СХД, подключённая через выделенную сеть хранения данных – Storage Area Network или SAN (см. рис. 3).
Непосредственно подключённая СХД подключается либо к выделенному узлу хранения данных, либо к управляющему узлу. Такая СХД всегда видна в операционной системе узла, к которому она подключена, как локально подключённое дисковое устройство (физическое подключение – по SATA, SAS, Fibre Channel).

Рис. 3: сеть хранения данных (SAN)
Для обеспечения отказоустойчивости и повышения скорости работы в системах хранения нередко используют технологию RAID (redundant array of independent disks – избыточный массив независимых дисков). В рамках RAID несколько дисков равного объёма объединяются в один логический диск. Объединение происходит на уровне блоков (которые могут не совпадать с физическими блоками дисков). Один логический блок может отображаться на один или несколько дисковых блоков.
Есть несколько «уровней», которые приняты как стандарт de-facto для RAID:
RAID-0 – логические блоки однозначно соответствуют блокам дисков, при этом они чередуются: блок0 = блок0 первого диска, блок1 = блок1 второго диска и т. д.;
RAID-1 – зеркальный массив, логический блок N соответствует логическим блокам N всех дисков, они должны иметь одинаковое содержимое;
RAID-2 – массив с избыточностью по коду Хэмминга;
RAID-3 и -4 – дисковые массивы с чередованием и выделенным диском контрольной суммы;
RAID-5 – дисковый массив с чередованием и невыделенным диском контрольной суммы;
RAID-6 – дисковый массив с чередованием, использующий две контрольные суммы, вычисляемые двумя независимыми способами.
Уровень 0 обеспечивает наибольшую скорость последовательной записи – блоки пишутся параллельно на разные диски, но не обеспечивает отказоустойчивости; уровень 1 – наибольшую отказоустойчивость, так как выход из строя N-1 диска не приводит к потере данных.
Уровни 2, 3 и 4 в реальности не используются, так как уровень 5 даёт лучшую скорость и надёжность при той же степени избыточности. В этих уровнях блоки дисков объединяются в полосы, или страйпы (англ. stripe).
В каждом страйпе один блок выделяется для хранения контрольной суммы (для уровня 6 – два страйпа), а остальные – для данных, при этом диск, используемый для контрольной суммы, чередуется у последовательных страйпов для выравнивания нагрузки на диски. При записи в любой блок рассчитывается контрольная сумма данных для всего страйпа, и записывается в блок контрольной суммы. Если один из дисков вышел из строя, то для чтения логического блока, который был на нём, производится чтение всего страйпа и по данным работающих блоков и контрольной суммы вычисляются данные блока.
Таким образом, для RAID-5 можно получить отказоустойчивость при меньшей избыточности, чем у зеркала (RAID-1), – вместо половины дисков можно отдать под избыточные данные только один диск в страйпе (два для RAID-6). Как правило, «ширина» страйпа составляет 3-5 дисков. Ценой этого становится скорость работы – для записи одного блока нужно сначала считать весь страйп, чтобы вычислить новую контрольную сумму.
Часто применяют двухуровневые схемы – RAID-массивы сами используются как диски для других RAID-массивов. В этом случае уровень RAID обозначается двумя цифрами: сначала нижний уровень, затем верхний. Наиболее часто встречаются RAID-10 (RAID-0, построенный из массивов RAID-1), RAID-50 и -60 – массивы RAID-0, построенные из массивов RAID-5 и -6 соответственно. Подробнее о RAID читайте в литературе и Интернете.
Если используется распределённое хранение данных, например, как в Lustre (о ней мы расскажем далее), то узлов хранения данных может быть несколько, а данные, хранящиеся на такой СХД, распределяются по узлам хранения данных. СХД с доступом по локальной сети (или сетевое хранилище данных, NAS) обычно предоставляет дисковое пространство узлам по специальным протоколам, которые можно объединить под общим названием сетевые файловые системы. Примерами таких файловых систем могут быть NFS (Network File System), Server Message Block (SMB) или её современный вариант – Common Internet File System (CIFS).
Строго говоря, CIFS и SMB – два разных названия одной и той же сетевой файловой системы, изначально разработанной компанией IBM и активно используемой в операционных системах компании Microsoft. Сейчас CIFS может применяться практически в любой операционной системе для предоставления доступа к файлам через локальную сеть. Как правило, кроме NFS и CIFS системы NAS могут предоставлять доступ к хранимым данным и по другим протоколам, например FTP, HTTP или iSCSI.
СХД, подключённые через специальные сети хранения данных (SAN), обычно видны в операционной системе как локально подключённые дисковые устройства. Особенность SAN в том, что для формирования такой сети в целях повышения надёжности могут использоваться дублированные коммутаторы. В этом случае каждый узел будет иметь несколько маршрутов для доступа к СХД, один из которых назначается основным, остальные – резервными. При выходе из строя одного из компонентов, через которые проходит основной маршрут, доступ будет осуществляться по резервному маршруту.
Переключение на резервный маршрут будет происходить мгновенно, и пользователь не обнаружит, что вообще что-то вышло из строя. Для того чтобы это работало, необходима поддержка множественных маршрутов (multipath) в оборудовании и ОС. Заметим, что хотя для multipath и есть стандарты, но в реальности часто встречается «капризное» оборудование, для корректной работы которого с multipath требуются нестандартные драйверы или пакеты системного ПО.
Отличие NAS от SAN довольно условное, поскольку существует протокол обмена iSCSI, позволяющий использовать обычную локальную сеть в качестве сети хранения данных. В этом случае сетевое хранилище данных будет видно в операционной системе как локально подключённое дисковое пространство. Сеть хранения данных может объединяться с высокоскоростной коммуникационной сетью. Например, в качестве SAN-сети способна выступать InfiniBand, используемая для высокоскоростного обмена данными между вычислительными узлами кластера.
Особенности аппаратной архитектуры
Ни для кого не секрет, что в самом начале компьютерной эры понятия «процессор» и «ядро» (имеется в виду вычислительное ядро процессора) были синонимичными. Точнее, понятие «ядро» к процессору не относилось вовсе, поскольку многоядерных процессоров ещё не было. В каждом компьютере устанавливался обычно один процессор, который в каждый момент времени мог исполнять лишь один процесс. Современные системы такого типа можно встретить и сейчас, но они, как правило, предназначены для решения специальных задач (контроллеры, встраиваемые системы).
Для увеличения мощности сервера или рабочей станции производители устанавливали несколько «одноядерных» процессоров (обычно от двух до восьми). Такие системы существуют и сейчас и называются симметричными многопроцессорными системами, или SMP-системами (от англ. Symmetric Multiprocessor System) (см. рис. 4).
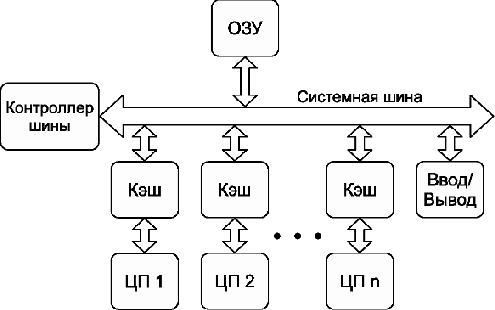
Рис. 4: симметричная многопроцессорная система (SMP)
Как видно из схемы, каждый процессор, представляющий собой одно вычислительное ядро, соединён с общей системной шиной. В такой конфигурации доступ к памяти для всех процессоров одинаков, поэтому система называется симметричной. В последнее время в каждом процессоре присутствует несколько ядер (обычно от 2 до 16). Каждое из таких ядер может рассматриваться как процессор в специфической SMP-системе. Конечно, многоядерная система отличается от SMP-системы, но эти отличия почти незаметны для пользователя (до тех пор, пока он не задумается о тонкой оптимизации программы).
Для ускорения работы с памятью нередко применяется технология NUMA – Non-Uniform Memory Access. В этом случае каждый процессор имеет свой канал в память, при этом к части памяти он подсоединён напрямую, а к остальным – через общую шину. Теперь доступ к «своей» памяти будет быстрым, а к «чужой» – более медленным. При грамотном использовании такой архитектуры в приложении можно получить существенное ускорение.
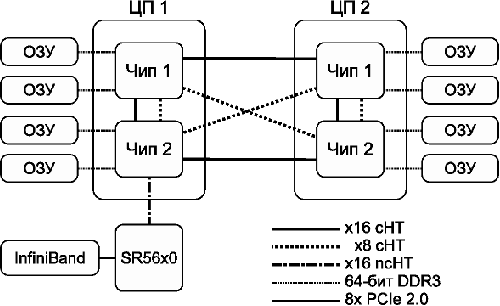
Рис. 5: схема узла NUMA на примере AMD Magny-Cours
Например, в архитектуре AMD Magny-Cours (см. рис. 5) каждый процессор состоит из двух кристаллов (логических процессоров), соединённых между собой каналами HyperTransport. Каждый кристалл (чип) содержит в себе шесть вычислительных ядер и свой собственный двухканальный контроллер памяти. Доступ в «свою» память идёт через контроллер памяти, а в «соседнюю» – через канал HyperTransport. Как видим, построить SMP- или NUMA-систему из двух или четырёх процессоров вполне возможно, а вот с большим числом процессоров – уже непросто.