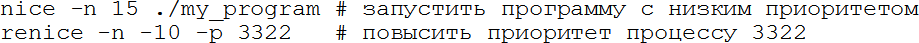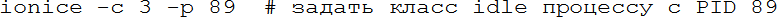Cуперкомпьютеры: администрирование
Ещё одним «камнем преткновения» в современных многоядерных системах является миграция процессов между ядрами. В общем случае для организации работы множества процессов операционная система предоставляет каждому процессу определённый период времени (обычно порядка миллисекунд), после чего процесс переводится в пассивный режим.
Планировщик выполнения заданий, переводя процесс из пассивного режима, выбирает ядро, которое не обязательно совпадает с тем, на котором процесс выполнялся до этого. Нередко получается так, что процесс «гуляет» по всем ядрам, имеющимся в системе. Даже в случае с SMP-системами влияние на скорость работы программы при такой миграции заметно, а в NUMA-системах это приводит ещё и к большим задержкам при доступе в память.
Для того, чтобы избавиться от паразитного влияния миграции процессов между ядрами, используется привязка процессов к ядрам (processor affinity, или pinning). Привязка может осуществляться как к отдельному ядру, так и к нескольким ядрам или даже к одному и более NUMA-узлам. С применением привязки миграция процессов или будет происходить контролируемым образом, или будет исключена вовсе.
Аналогичная проблема присутствует и в механизме выделения памяти пользовательским процессам. Допустим, процессу, работающему на одном NUMA-узле, требуется для работы выделить дополнительную память. В какой области памяти будет выделен новый блок? А вдруг он попадёт на достаточно удалённый NUMA-узел, что резко уменьшит скорость обмена? Для того, чтобы избежать выделения памяти на сторонних узлах, есть механизм привязки процессов к памяти определённого NUMA-узла (memory affinity).
В нормальном случае каждый процесс параллельной программы привязывается к определённым NUMA-узлам как по ядрам, так и по памяти. В этом случае скорость работы параллельной программы не будет зависеть от запуска и будет достаточно стабильной. При запуске параллельных программ такая привязка не просто желательна, а обязательна. Более подробно данный вопрос рассмотрен в главе «Библиотеки поддержки параллельных вычислений», где описываются различные среды параллельного программирования.
В большинстве современных процессоров компании Intel используется технология HyperThreading. Благодаря этой технологии каждое вычислительное ядро представлено в системе как два отдельных ядра. Конечно, эффективность использования аппаратных ресурсов в этом случае сильно зависит от того, как написана программа и с использованием каких библиотек и каким компилятором она собрана. В большинстве случаев параллельные вычислительные программы написаны достаточно эффективно, поэтому ускорения от использования технологии HyperThreading может не быть, и даже наоборот, будет наблюдаться замедление от её использования.
На суперкомпьютерах эта технология вообще может быть отключена в BIOS каждого узла, чтобы не вносить дополнительных трудностей в работу параллельных программ. Как правило, эта технология не приносит ускорения для вычислительных программ. Если вы используете небольшой набор программ на суперкомпьютере, проверьте их работу с включённым и отключённым HyperThreading и выберите лучший вариант. Обычно мы рекомендуем включить её, но при этом указать системе управления заданиями число ядер, как с отключённым HT. Это позволяет получить дополнительные ресурсы для системных сервисов, минимально влияя на работу вычислительных заданий.
Ещё одна особенность архитектуры касается уже не отдельного, а нескольких узлов. Как мы ранее указывали, вычислительные узлы в вычислительном кластере объединены высокоскоростной коммуникационной сетью. Такая сеть может предоставлять дополнительные возможности обмена данными между процессами параллельных программ, запущенных на нескольких вычислительных узлах. В рамках одного узла применяется технология прямого доступа в память (Direct Memory Access, или DMA), позволяющая устройствам узла связываться с оперативной памятью без участия процессора. Например, обмен данными с жёстким диском или с сетевым адаптером может быть организован с использованием технологии DMA.
Адаптер InfiniBand, используя технологию DMA, предоставляет возможность обращаться в память удалённого узла без участия процессора на удалённом узле (технология Remote Direct Memory Access, или RDMA). В этом случае возникнет необходимость синхронизации кэшей процессоров (данный аспект мы не будем рассматривать подробно). Применение технологии RDMA позволяет решить некоторые проблемы масштабируемости и эффективности использования ресурсов.
Существует достаточно серьёзная критика данной технологии. Считается, что модель двухстороннего приёма-передачи (two-sided Send/Receive model), применяемая в суперкомпьютерах компании Cray (коммуникационная сеть SeaStar) и в коммуникационных сетях Quadrics QsNet, Qlogic InfiniPath и Myrinet Express, более эффективна при использовании параллельной среды программирования MPI. Конечно, это не исключает эффективного использования технологии RDMA, но применение её ограничено. В большинстве практических приложений использование RDMA даёт снижение латентности, но на больших приложениях (сотни узлов) может вылиться в чрезмерное использование системной памяти.
Краткое резюме
Знание аппаратуры, основных принципов работы ваших сетей, хранилищ данных и прочих «железных» компонент очень важно для администратора суперкомпьютера. Без этих знаний часто бывает невозможно решить проблемы, возникающие в таких вычислительных комплексах.
Ключевые слова для поиска
rdma, hpc interconnect, numa, smp, cache, latency.
Глава 3. Как работает суперкомпьютер
Рассмотрим стек ПО, который необходим для обеспечения работы суперкомпьютера. Очевидно, что в первую очередь это операционная система, затем системное ПО, которое требуется для работы аппаратной части, – драйверы и т. п., а также ПО для файловой системы.
Следующая часть – набор ПО для организации загрузки и ПО для удалённого доступа. Далее – система контроля запуска заданий (система очередей, batch system). Потом следует ПО, необходимое для работы параллельных программ: готовые параллельные пакты и библиотеки – MPI, Cuda и т. п.
Обязательный компонент – компиляторы и дополнительные библиотеки, часто требующиеся для вычислительных программ, такие как BLAS, FFT и др. Для организации полноценного управления суперкомпьютером также потребуются ПО для организации резервного копирования, мониторинга, ведения статистики, визуализации состояния суперкомпьютера.
Как происходит типичный сеанс пользователя
Существует множество вариантов организации работы с конкретными вычислительными пакетами, которые предоставляют собственный интерфейс для работы с суперкомпьютером. Мы будем рассматривать «общий» вариант.
Итак, пользователь работает на своём компьютере – рабочей станции, ноутбуке, планшете и т. п. Для начала сеанса он запускает ssh-клиент (putty, openssh и т. п.), вводит адрес, логин, указывает пароль или файл с закрытым ключом (или загружает профиль, где всё это уже указано) и открывает соединение с суперкомпьютером. Попав на узел доступа, пользователь может отредактировать и откомпилировать собственную параллельную программу, скопировать по протоколу sftp входные данные. Для запуска программы пользователь выполняет специальную команду, которая ставит его задание в очередь. В команде он указывает число требуемых процессов, возможно, число узлов и другие предпочтения, а также свою программу и её аргументы. Пользователь может проверить статус своего задания, посмотреть список заданий в очереди. Если он понял, что в программе ошибка, то может снять её со счёта или удалить из очереди, если она ещё не запустилась.
При необходимости можно поставить в очередь и несколько заданий (например, если нужно обработать несколько наборов входных данных). После того как задание поставлено в очередь, его ввод/вывод будет перенаправлен в файлы, поэтому можно спокойно завершить сеанс и проверить состояние задания или посмотреть/скачать результаты позже, в другом сеансе. Большинство систем управления заданиями позволяют запустить задание и интерактивно, связав её ввод/вывод с терминалом пользователя. В этом случае придётся оставлять сеанс открытым до тех пор, пока задание стоит в очереди и работает.
Вся работа происходит в командной строке, поэтому пользователь должен знать минимальный набор команд Linux (как правило, это не составляет проблем). Элементарного самоучителя Linux или даже странички на сайте с описанием нужных команд обычно бывает достаточно. Для управления файлами многие пользователи применяют программу Midnight Commander (mc), которая ещё больше упрощает задачу.
Жизненный цикл задания
Типичное задание на суперкомпьютере проходит несколько фаз. Первая – постановка задания в очередь. На этом этапе пользователь указывает путь к исполняемой программе, её аргументы и параметры запуска, такие как число MPI-процессов, число узлов, требования к ним и т. д. Явно или неявно пользователь указывает также способ запуска задания – через команду mpirun (для MPI-приложений), как обычное приложение и т. д.
Система управления заданиями регулярно проверяет, можно ли запустить новую задание, просматривая очередь. Как только наше задание подойдёт к началу очереди или по каким-то иным критериям подойдёт для запуска, система управления (точнее, её планировщик) выберет набор узлов, на которых будет произведён запуск, оповестит их, возможно, выполнит скрипт инициализации (так называемый пролог) и приступит к запуску задания.
Фаза запуска может отличаться в разных системах, но общий смысл одинаков: на вычислительном или управляющем узле запускается стартовый процесс, например mpirun, которому передаётся список узлов и другие параметры. Этот процесс запускает на вычислительных узлах рабочие процессы задания – самостоятельно (через ssh) или используя помощь системы управления заданиями. С этого момента система управления заданиями считает, что задание работает. Она может отслеживать состояние рабочих процессов на узлах, если это поддерживается, или отслеживать только состояние стартового процесса. Как только стартовый процесс завершается либо задание снимается со счёта принудительно (пользователем или самой системой управления), задание переходит в фазу завершения.
В этой фазе система управления пытается корректно завершить работу задания – убедиться, что все её процессы завершились, не осталось лишних файлов во временных каталогах и т. п. Для этого часто используется отдельный скрипт, так называемый эпилог. По окончании фазы завершения задание считается завершённым. Какое-то время информация о ней может сохраняться в системе управления, но обычно данные о ней теперь можно найти только в журналах.
В описанном цикле могут быть и нестандартные действия, например изменение приоритета задания, меняющее скорость его прохождения в очереди, блокировка, временно запрещающая запуск задания, приостановка работы и некоторые другие.
Что скрыто от пользователя
Всё, что мы описали выше, – это то, что видно рядовому пользователю. Однако есть и то, что остаётся для него «за кадром», но играет важную роль для администратора. Это те сервисы, которые обеспечивают корректную работу суперкомпьютера: управление учётными записями, распределённой файловой системой, квотами, сервисы удалённого мониторинга узлов, сбора статистики и журналирования, мониторинга оборудования и инфраструктуры, экстренного оповещения и отключения, резервного копирования. Все эти сервисы работают незаметно для пользователя, но их важность трудно переоценить.
Краткое резюме
Собрать простейший вычислительный кластер можно и «на коленке»: взять два ноутбука, подключить в общую сеть, настроить беспарольный доступ по ssh, на одном из них запустить NFS-сервер, а на другом примонтировать по NFS файловую систему, и – готово, можно запускать MPI-программы. Но производительность такого кластера весьма невелика, а при попытке подключить вместо двух ноутбуков двадцать возникают проблемы: сеть не справляется с нагрузкой, NFS тормозит, один ноутбук завис, и мы полчаса выясняем, что же случилось, и многое другое. Увы, если кластер не «игрушечный», а предназначен для реальных задач, то подходить к его построению и эксплуатации надо серьёзно. Мы кратко обозначили основные компоненты программного «стека» суперкомпьютера, далее попробуем рассмотреть их подробнее.
Ключевые слова
MPI, сеанс работы, ssh-клиент, NFS.
Глава 4. UNIX и Linux – основы
Если вы уже используете Linux и имеете неплохое представление о его администрировании, то смело пропустите эту главу. Если информация из неё будет для вас совсем новой, то для дальнейшего чтения желательно почитать дополнительную литературу, потренироваться в написании скриптов на bash.
В любом случае мы рекомендуем ознакомиться с книгами из списка ниже, в них есть масса информации, полезной даже опытным профессионалам:
Эви Немет, Гарт Снайдер, Трент Хейн, Бэн Уэйли
Unix и Linux: руководство системного администратора
Это классический учебник по Unix и Linux. В нём нередко случаются отсылки к таким древним системам, как VAX и PDP-11, тем не менее он отлично отражает суть работы UNIX и остаётся актуальным по сей день.
Томас Лимончелли, Кристина Хоган, Страта Чейлап
Системное и сетевое администрирование. Практическое руководство
Более новый учебник по Linux, содержит массу полезных примеров.
Брайан Керниган, Роб Пайк
Unix – Программное окружение
Эта книга в большей степени посвящена программированию как в оболочке bash, так и с помощью иных инструментов. Даже если вам не приходится регулярно этим заниматься, настоятельно советую прочесть эту книгу, так как она откроет вам те принципы, по которым строится работа в UNIX, вам станут более понятны многие процессы, происходящие внутри ОС.
Томас Лимончелли
Тайм-менеджмент для системных администраторов
Название говорит само за себя. В книге есть множество ситуаций, в которые попадает любой системный администратор, и практические советы, как из них выходить с минимальными потерями.
Эта глава не претендует на статус учебника по UNIX, но мы постарались собрать в ней все основные понятия, знание которых в дальнейшем вам обязательно потребуется. На сегодняшний день на суперкомпьютерах в подавляющем большинстве случаев используется UNIX-подобная операционная система. Мы говорим UNIX-подобная, так как легендарная ОС UNIX в чистом виде сейчас не развивается и практически не используется.
Краткая историческая справка. После разделения компании AT&T, которая и разработала эту ОС, товарный знак UNIX и права на оригинальный исходный код неоднократно меняли владельцев, в частности, длительное время они принадлежали компании Novell. В 1993 г. Novell передала права на товарный знак и на сертификацию программного обеспечения на соответствие этому знаку консорциуму X/Open, который затем объединился с Open Software Foundation и сейчас называется «The Open Group». Этот консорциум занимается разработкой открытых стандартов для ОС, таких как POSIX (сейчас он переименован в Single UNIX Specification).
Согласно положению «The Open Group», название «UNIX» могут носить только системы, прошедшие сертификацию на соответствие Single UNIX Specification. В настоящее время несколько ОС прошли разные версии этой сертификации, например Solaris, AIX.
Даже те ОС, которые не проходили сертификации UNIX (например Linux), стараются соответствовать этим стандартам. Именно поэтому архитектура приложений на этих ОС очень похожа, а перенос приложения с одной ОС на другую прост, особенно если при написании программы использовались только стандартные библиотеки и функции. Именно эти качества и огромная популярность UNIX в прошлом, а также отлично зарекомендовавшие себя её наследники – Solaris, OpenBSD, FreeBSD, AIX и, конечно же, Linux – обеспечили UNIX-подобным ОС лидерство на серверах всего мира.
Вычислительные кластеры и суперкомпьютеры не исключение. Здесь стандартом de facto является Linux. Именно на эту операционную систему мы и будем ориентироваться. Несмотря на то что существует немало установок на других операционных системах, таких как Windows, FreeBSD, Solaris и других, в данной книге мы не будем останавливаться на их особенностях в классе HPC.
Процессы
Основное понятие в любой ОС – процесс. Это нечто типа контейнера (реально – описания в таблицах ОС), содержащего уникальный идентификатор (PID), права (владелец, группа и некоторые другие), код программы, область данных, стек, набор страниц памяти, таблицу открытых файлов и прочие атрибуты. Для ОС процесс – единица планирования процессорного времени, каждый процесс может исполняться процессором, быть в ожидании исполнения, быть в состоянии системного вызова (передать запрос к ОС и ждать ответ), быть остановленным или завершившимся. Обозначаются они как R (running), S (sleeping), D (uninterruptable sleep), T (stopped) и Z (zombie).
Например, если запустить на компьютере с 2 ядрами 10 программ расчёта числа пи, то одновременно смогут считаться только 2, но ОС будет с большой частотой (например 100 раз в секунду) приостанавливать выполнение активного процесса, помещать его в очередь и отправлять на выполнение следующий процесс из очереди (очень грубо, но суть именно такая). Для процесса это выглядит как будто он монопольно владеет процессором, просто скорость этого процессора раз в 5 ниже, чем могла бы.
Среднее число процессов в очереди обозначается как «уровень загрузки» – Load Average. Если он больше числа ядер, то обычно это значит, что не всем задачам «достаётся» процессор, и они работают медленнее. Надо учесть что в очередь включаются и процессы в состоянии D, то есть высокий LA могут вызвать процессы, которые, например, много читают с диска или пишут (и постоянно ждут в вызове read или write). То есть высокий LA – это сигнал, что потенциально что-то не так, но хорошо бы проверить.
В состояние stopped процесс переводится, только если другой процесс послал ему сигнал STOP. В этом случае он «замирает» и перестаёт исполняться до тех пор, пока не получит сигнал CONT (или не будет завершён). Если процесс в состоянии D, то сигнал игнорируется. В принципе, сигнал STOP процесс может игнорировать, но так делается очень редко.
Состояние zombie возникает, когда процесс завершился, но его родитель «не подтвердил» это (не вызвал системный вызов wait). Это делается для того, чтобы родительский процесс мог получить данные о том, как завершился процесс. т. е. процессы в состоянии zombie уже не потребляют никаких ресурсов ни процессора, ни памяти. По этой же причине их нельзя принудительно завершить – они уже завершены.
Родительский процесс (PPID) есть у каждого процесса в системе, если родительский процесс завершился, то им становится процесс с PID 1 (обычно это специальный процесс init в системе, мы про него поговорим ниже), который выполняет wait для всех таких процессов.
Посмотреть список процессов и их состояние можно с помощью команды ps. У неё нелёгкая судьба, т. к. в разных вариантах популярных ОС (Unix, BSD, Solaris) исторически у неё было много разных, в том числе конфликтующих опций. В результате в Linux используется вариант GNU, который пытается их сочетать. В частности, есть опции, которые обязательно надо указывать с минусом впереди, а другие – наоборот только без минуса. Ниже самые полезные с нашей точки зрения:

К большинству комбинаций можно добавить w, тогда поле имени процесса (обычно программа с аргументами) будет шире. Если добавить дважды, то будет ещё шире, а если трижды, то ограничений на ширину не будет совсем.
Бывает удобно отслеживать активность процессов в реальном времени. Тут помогут команды top и более новомодная htop. Они показывают процессы в виде таблицы, отсортированной по одному полю, и обновляют её раз в 5 секунд (можно поменять интервал). При этом показываются только те процессы, которые поместились на экране, плюс некоторые общие данные о системе – загрузка процессора, памяти, loadaverage, число процессов в разных состояниях.
Можно переключать режимы отображения и сортировки. Для top есть несколько горячих клавиш, их список можно получить, нажав 'h'. Наиболее удобные варианты сортировки и команды:
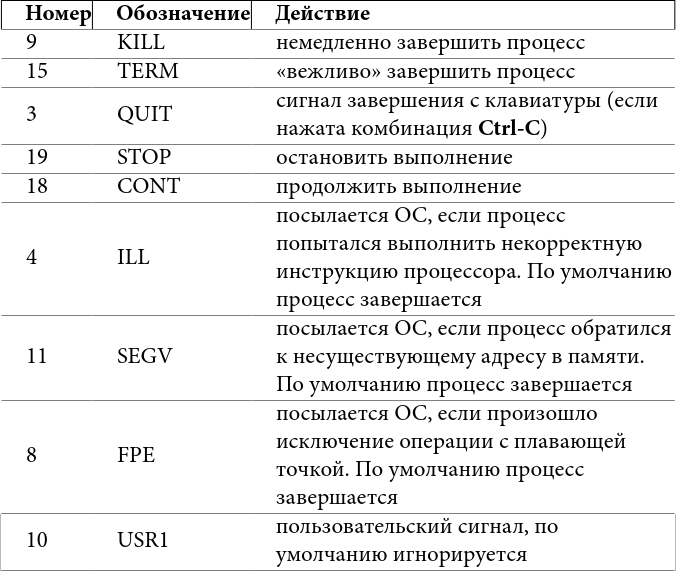
– сортировать процессы по использованию процессора; 1 – показывать загрузку каждого ядра или суммарную; k – послать сигнал процессу; r – изменить приоритет процесса; u – фильтровать по пользователю; q – выход. У htop более дружественный интерфейс, по возможности она использует цветной вывод, загрузку процессора и памяти выводит в виде текстовых прогресс-баров, умеет организовывать процессы в деревья (и схлопывать их с одну строку, что иногда очень удобно). Клавиши управления выведены в нижней строке в стиле Norton Commander (Midnight Commander/FAR manager). Мы уже не раз упомянули сигналы – это простой способ общения процессов, любой процесс может послать другому сигнал, если он принадлежит тому же пользователю (пользователь root может посылать всем). Сигнал – целое число, так что много информации им не передать, но его функция – попросить процесс выполнить какое-то действие. Все сигналы, кроме KILL, могут быть перехвачены и обработаны, если процесс не обрабатывает сигнал, то ОС выполняет заранее определённое действие за него. Для большинства сигналов есть стандартные значения и действия, ниже – самые часто используемые: Таблица 3: некоторые сигналы в Linux Действия «по умолчанию» процесс может изменять (кроме сигнала KILL). Их можно обработать или игнорировать. При корректном завершении память процесса может быть записана в т. н. core-файл для того, чтобы после можно было исследовать причину ошибки отладчиком. Будет ли создан core-файл, определяется настройками ОС и лимитами (см. главу о квотах). Послать сигнал из командной строки можно командой kill. Например, kill -9 1234 принудительно завершит процесс 1234, а kill -STOP 2345 остановит процесс 2345. Как видно, можно использовать как номер сигнала, так и его обозначение. kill -l покажет список всех сигналов. Иногда требуется послать сигнал не одному процессу, а многим, например всем процессам пользователя. Тогда на помощь приходит программа pkill: pkill -u vasya -TERM пошлёт сигнал TERM всем процессам пользователя vasya. Выше мы говорили о том, что процессы, желающие выполняться, ставятся в очередь. В ней они выполняются не всегда подряд, у каждого есть приоритет и влияющий на него параметр nice (вежливость). Чем выше приоритет, тем быстрее процесс продвигается к началу очереди. Явно задать приоритет нельзя, но можно поменять вежливость (часто её тоже называют приоритетом для простоты, но это не совсем так). Делается это командой nice или renice, первая запускает программу с заданным приоритетом, вторая меняет приоритет уже запущенной. Чем выше вежливость, тем ниже приоритет, программа чаще будет «пропускать» других вперёд. Исторически вежливость меняется от 20 до +20, и обычный пользователь не может указать её меньше 0. Например: Здесь мы меняем вежливость с 0 до 15 (приоритет понижается) или до -10 (приоритет повышается). Кроме очереди на ресурсы процессора есть очередь к ресурсам жёстких дисков, несколько процессов могут одновременно читать-писать, и их запросы будут конкурировать. В этой очереди тоже есть приоритет, им управляет команда ionice. Есть три класса приоритетов – idle (выполнять запрос, если больше никого в очереди нет), best effort (нормальная очередь) и real time (запрос должен быть выполнен за заданное время). Внутри классов, кроме idle, есть собственные приоритеты, но в наших задачах можно ограничиться назначением класса idle процессу, занимающему много времени на дисковых операциях, но не приоритетному: Понятие процесса – основное в любой ОС. Не следует путать процессы и нити, важно знать, что такое реальная и виртуальная память процесса, как работают разделяемые библиотеки (shared objects, so) и динамический линкер (ld.so). Изучите документацию на эту тему в дистрибутиве своей ОС или в обширной документации в Интернете.